A reguláris kifejezés vagy a reguláris kifejezés olyan speciális karakterek halmaza, amelyek kombinációjával mintát alkotnak a karakterláncok karaktereinek kereséséhez. A számítógép-programozásban és a szoftverfejlesztésben a regex tanulása nagyon hasznos lehet bármilyen szövegben található információ megtalálásában. A reguláris kifejezések használatával mindenféle szövegkeresési, formázási és szövegcsere művelet elvégezhető.
Ez az oktatóanyag elvezeti Önt a reguláris szóköz használatához Java nyelven.
Mi a Regex a Java-ban?
A reguláris kifejezés vagy reguláris kifejezés lehet olyan egyszerű, mint egy karakter vagy egy összetett minta. Létrehozható szöveg- és szimbólumsorral, meghatározott sorrendben. A reguláris kifejezésekben szereplő karakterek többsége betűk és tipográfiai szimbólumok. A Regex megkülönbözteti a kis- és nagybetűket, ezért tartsa ezt szem előtt létrehozása és használata során.
Hogyan használjunk Regex szóközt a Java-ban?
Bár a Java-nak nincs előre meghatározott Regular Expression osztálya. Használhatunk azonban reguláris kifejezéseket a ' java.util.regex ” könyvtár. Tartalmaz néhány osztályt, mint pl. Minta ”, amely egy regex minta meghatározására szolgál, és „ Gyufák ” osztály, amely a mintával való keresésre szolgál.
Két módszer létezik a reguláris szóköz használatára a Java nyelvben, az alábbiak szerint:
-
- Pattern.matches() metódus használata (előre meghatározott reguláris kifejezés használata)
- Minta és Matcher osztály használata (felhasználó által meghatározott reguláris kifejezés létrehozása az illeszkedéshez)
Nézzük meg, hogyan működnek ezek a módszerek a szóközök regexével a Java nyelven.
1. módszer: Használjon előre meghatározott reguláris szóközt a Pattern.matches() metódussal Java nyelven
Ha egy karakterláncban szóközöket szeretne keresni, a Javaban három gyakori reguláris kifejezés létezik:
-
- \s : Egyetlen fehér szóközt jelent.
- \s+ : Több fehér szóközt jelez.
- \u0020 : Ez a szóköz Unicode kódja, amelyet reguláris kifejezésként használnak a szóköz megtalálására a szövegben.
Ezeket a regexeket használhatjuk a statikus metódusban ' egyezés() ' a ' Minta ' osztály. A mintaosztály a „ java.util.regex ” csomagot. Alább látható a Pattern.matches() metódus szintaxisa:
Szintaxis
Minta.gyufa ( '\s' , ' ' ) ;
A megadott metódus két argumentumot igényel: a reguláris kifejezést és a megfelelő karakterláncot. Az első „\s” argumentum a fehér szóköz reguláris kifejezése vagy regex, a második argumentum '' a szóköz a karakterláncban. Igaz vagy hamis logikai értékként tér vissza.
1. példa: Használja a „\s” WhiteSpace Regex-et
Itt a „ \s ” regex a Pattern.matches() metódusban. Második argumentumként egy karakterláncot adunk át a metódusban szóköz nélkül. A metódus ellenőrzi a reguláris kifejezést és a karakterláncot, majd visszaad egy logikai értéket, amely a ' mérkőzés ” változó:
logikai érték mérkőzés = Minta.egyezik ( '\s' , '' ) ;
Nyomtassa ki az egyezési változó értékét a ' System.out.println() ” módszer:
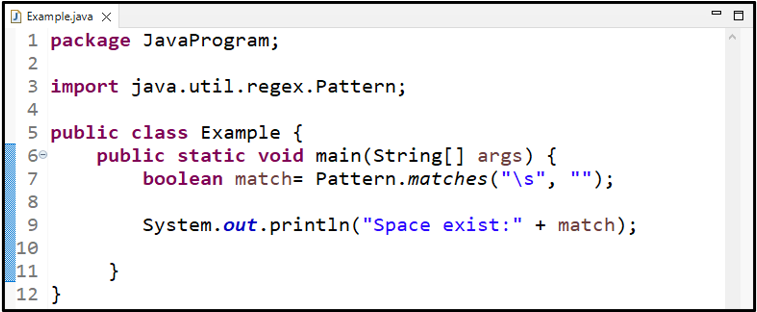
A ' Pattern.matches() ' módszere ' hamis ” mert az átadott karakterláncban nincs szóköz:

Most látni fogunk néhány más példát a szóköz és más reguláris kifejezések párosítására.
2. példa: Használja a „\s+” WhiteSpace Regex-et
Ebben a példában átadjuk a „ \s+ ' szabályos kifejezés a ' egyezés() ” módszer több szóköz megkeresésére:
logikai érték mérkőzés = Minta.egyezik ( '\s+' , ' ' ) ;
Nyomtassa ki annak az egyezési változónak az értékét, amely a metódus visszaadott eredményét tárolja:
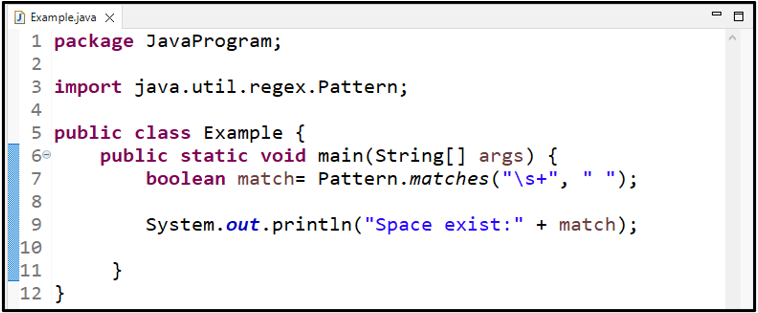
Mivel a második argumentum szóközöket tartalmaz, az eredményül kapott érték a következőképpen jelenik meg: igaz ”:

3. példa: Használja a „\u0020” WhiteSpace Regex-et
Itt megmutatjuk, hogyan használják az Unicode-ot reguláris kifejezésként a Java-ban. A megadott célra a „ \u0020 ” regex a szóköz Unicode-jaként:
logikai érték mérkőzés = Minta.egyezik ( '\u0020' , ' ' ) ;
Nyomtassa ki a visszaadott értéket:
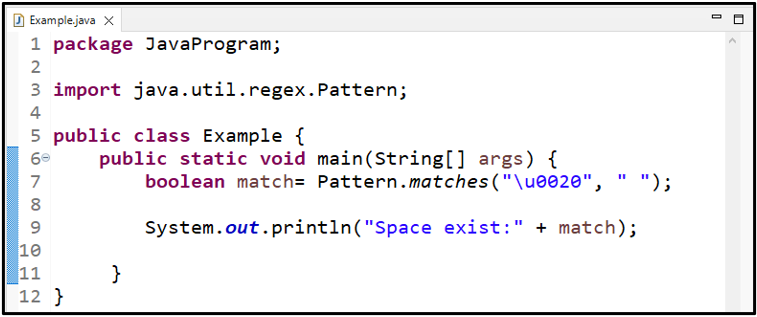
A Pattern.matches() metódus kiírja a „ igaz ” átadott karakterláncként, amely szóközöket tartalmaz:

Térjünk át a másik módszerre a regex használatához Javaban.
2. módszer: Felhasználó által definiált reguláris szóköz használata mintával és egyező osztállyal
Az ' Minta ' osztály egy minta meghatározására vagy létrehozására szolgál, míg a ' Gyufa ” osztály az adott minta szerinti keresésre szolgál. A reguláris kifejezés mintája a „ fordít() ” a Pattern osztály metódusa. Csak egy paraméterre van szükség, az a minta, amelyet bármilyen célra le szeretne fordítani.
Szintaxis
Pattern.compile ( ' \t \p{Zs}' ) ;
Az Gyufa osztály megfelel a mintának a ' egyezés() ” módszerrel. Egy ' húr ” mint a minta.
Szintaxis
mintaVáltozó.matcher ( húr ) ;
Van néhány előre definiált reguláris kifejezés a szóközökhöz, amelyeket fentebb tárgyaltunk, a többit alább soroljuk fel:
-
- \\t\\p{Zs}
- \\p{Zs}
Most nézzünk meg néhány példát.
1. példa: Használja a „\\t\\p{Zs}” WhiteSpace Regex-et
Ebben a példában megszámoljuk a szóközök számát. Először létrehozunk egy karakterláncot ' s ” és nyomtassa ki a konzolon:
Karakterlánc s = 'WelcometoLinuxHint' ;System.out.println ( s ) ;
Ezután meghatározunk egy mintát ' \\t\\p{Zs} ', amely szóköz reguláris kifejezésként működik a Java nyelvben, és egyenlő a ' \s ”. A megadott minta összeállítása után a „ változó regexPattern ” eredő értéket fog tartalmazni:
Hívja a ' egyezés() 'módszer és passz' s ' Húr:
Hozzon létre egy egész típusú változót ' számol ” és inicializálja a „” értékkel 0 ”:
Számolja meg a karakterláncban található szóközök számát a ' míg ” hurok. A hurok bejárja a Stringet, és növeli a count változó értékét, ha szóközzel találkozik:
count++;
}
Végül nyomtassa ki a count értékét, hogy megmutassa, hány szóköz található egy karakterláncban:
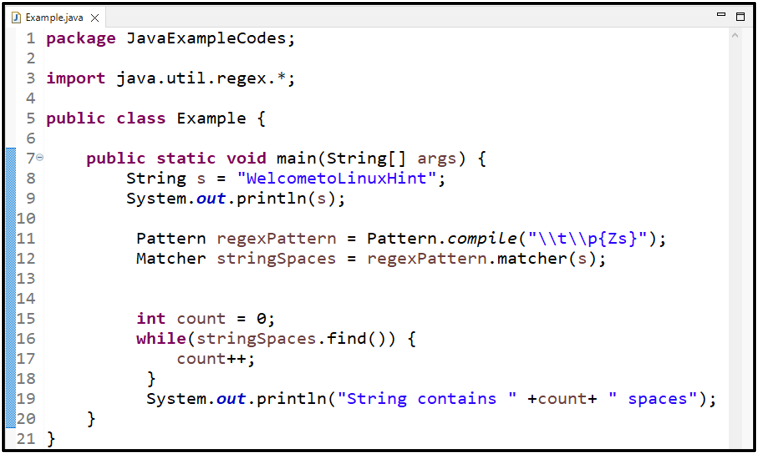
Kimenet

2. példa: Használja a „\p{Zs}” WhiteSpace Regex-et
Most egy másik minta használatával megtaláljuk a szóközöket a karakterláncban \p{Zs} ”. Ez a minta hasonlóan működik, mint a ' \s ” és „ \s+ ” szabályos kifejezés:
Pattern regexPattern = Pattern.compile ( '\\p{Zs}' ) ;
Most úgy hívjuk, hogy egyezés() 'módszer és passz' s ” Karakterlánc argumentumként:
A fenti példához hasonlóan mi is használunk egy „ míg ” ciklus a karakterláncban lévő szóközök megszámlálásához és kinyomtatásához:
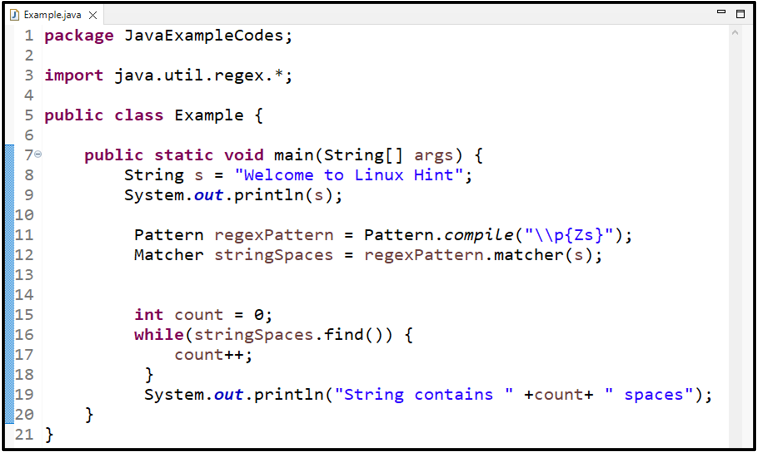
A megadott kimenet azt jelzi, hogy a „String” Üdvözli a Linux Hint ” három szóközt tartalmaz:

Összeállítottuk az összes legegyszerűbb módszert, amelyek segíthetnek a reguláris szóköz használatában a Java nyelven.
Következtetés
Sok reguláris kifejezés létezik a szóközökre, mint pl. \s ”, „ \s+ ”, „ \u0020 ”, „ \\t\\p{Zs} ”, és „ \\p{Zs} ”. Ezeket a reguláris kifejezéseket a Pattern osztály matches() metódusában vagy a Pattern Class definiálásával és a Matcher osztály segítségével történő egyeztetésével használjuk. A leggyakrabban használt reguláris szóköz a \s és \s+. Ebben az oktatóanyagban bemutattuk a reguláris szóköz használatának összes módszerét a Java nyelven.