Példa # 01
Bemutatjuk a gyakorlatban, hogyan használhatjuk a „pandas” „to_json()” metódusát a „pandas” DataFrame JSON formátumra cseréjéhez. Ide importáljuk a „pandas” csomagot, ami a „numpy”, és mi „np”-ként importáljuk. Most a „pandas” kód végrehajtásához importálni kell a panda csomagjait. A csomag importálásához az „import” kulcsszót használjuk. Ezután beállítjuk a „pandákat pd-ként”, ami azt jelenti, hogy könnyen elérhetjük vagy felhasználhatjuk bármelyik „pandas csomagot”, amelyre szükségünk van, ha csak a „pd”-t helyezzük oda.
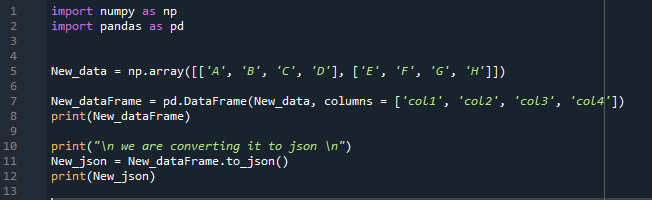
Itt létrehozzuk a numpy tömböt az „np. tömb”, ez az „np” segít a numpy könyvtári függvények elérésében. Ez a numpy tömb a „New_data” változóban is tárolódik, és ehhez a számszerű tömbhöz az „A, B, C, D” és az „E, F, G, H” értékeket írjuk. Ez a számtalan tömb most a „pd.DataFrame” metódussal DataFrame-mé konvertálódik. Ez a „panda” metódus, amelyet itt a „pd” elhelyezésével érünk el. Amikor ezt a numpy tömböt DataFrame-be konvertáljuk, akkor az oszlopneveket is megadjuk.
Az oszlopfejlécként hozzáadott nevek: „col1, col2, col3 és col4”. Ekkor látja, hogy van lent a „nyomtatás”, amelyben beállítjuk a DataFrame nevét, ami jelen esetben „New_dataFrame”, tehát ez a kód végrehajtása során jelenik meg. Most ezt a DataFrame-et JSON formátumba konvertáljuk a „to_json()” metódus használatával. A DataFrame nevét „New_dataFrame” a „to_json()” metódussal állítjuk be, és ezt a metódust is elhelyezzük a „New_json” változóban. Itt egyetlen paramétert sem adtunk át ehhez a „to_json()” metódushoz. A DataFrame JSON formátuma most „nyomtatásba” kerül, és a konzolon is megjelenik.
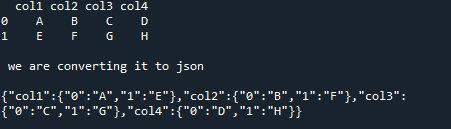
Ennek a kódnak a fordításához és végrehajtásához nyomjuk meg a „Shift+Enter” billentyűkombinációt, és ha a kód hibamentes, akkor a kimenet megjelenik. Ide illesztjük be ennek a kódnak az eredményét is, amelyben bemutattuk az ebben a példában létrehozott DataFrame-et, valamint a DataFrame JSON-formátumát.
02. példa
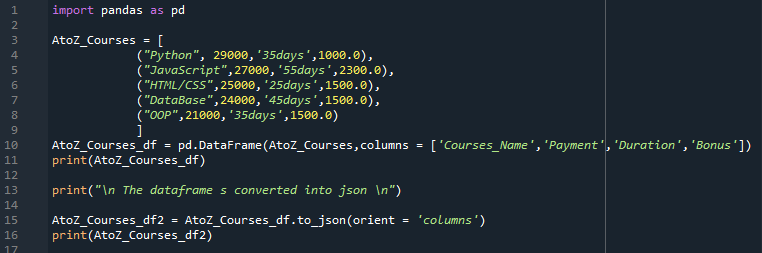
Itt csak egy könyvtárat importálunk, ez a „pandák”, majd létrejön az „AtoZ_Courses” lista, és elhelyezünk benne néhány listát, amelyek a „Python, 29000, 35 days és 1000.0”, majd a „ JavaScript, 27000, 55 nap és 2300.0”, ezután hozzáadjuk a „HTMLCSS, 25000, 25 nap és 1500.0” kifejezést. Most két további adatot is beszúrtunk: „Adatbázis, 24000, 45 nap és 1500.0”, valamint „OOP, 21000, 35 nap, 1500.0”. Az „AtoZ_Courses” lista most megváltozott a DataFrame-ben, és elneveztük „AtoZ_Courses_df”-nek. A „Courses_Name, Payment, Duration és Bonus” itt a DataFrame oszlopneveiként szerepel.
Most ebben a lépésben létrejön a DataFrame, és hozzáadjuk a „print()” utasításhoz, hogy megjelenítse a terminálon. Most a „to_json()” metódussal átalakítjuk az „AtoZ_Courses_df” DataFrame-et JSON formátumba. Ez a „to_json()” metódus is kapott egy paramétert, amely „orient= column”, amely egyben az alapértelmezett paraméter is. A DataFrame-et diktátumként jeleníti meg „{oszlopnév -> {index érték -> oszlopérték}} formátumban”.
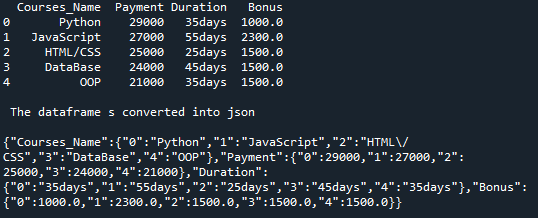
Itt JSON formátumban megjeleníti az oszlop nevét, majd az oszlop összes értékét az index értékével együtt. Először megemlíti az első oszlop nevét, majd az első oszlop összes értéke megjelenik az indexértékekkel együtt, majd a második oszlop nevét és a második oszlop összes értékét indexekkel és így tovább.
03. példa
A DataFrame ebben a kódban generálódik „Bachelors_df” néven. Öt oszlopot szúrtunk be ehhez a „Bachelors_df”-hez. Az első itt található oszlop a „Diák” oszlop, és beillesztjük a „Lily, Smith, Bromley, Milli és Alexander” kifejezést. A következő oszlop a „Fokozat” oszlop, amely az „IT, BBA, English, CS és DVM” szavakat tartalmazza. Ezután jön a „csatlakozási_év”, ahol összeadjuk a hallgatók csatlakozási éveit, amelyek a következők: „2015, 2018, 2017, 2015 és 2014”.
Az oszlop melletti oszlop az „év_érettségi”, amely a hallgatók érettségi éveit tartalmazza: „2019, 2022, 2021, 2019 és 2018”. Ide adjuk a „CGPA” oszlopot is, amelyben a tanulók CGPA-jait helyezzük el „3.3, 3.5, 3.6, 3.7 és 3.8”. A „Bachelors_df” terminálon való megjelenítéséhez a „print()” kifejezésben szerepeltetjük. Most a „Bachelors_df” DataFrame-et JSON formátumba konvertáljuk a „to_json()” metódussal.
Az „orient= records” paraméter szintén átadásra kerül ebben a kódban ennek a „to_json()” metódusnak. Ez az „orient=rekordok” a JSON-formátumot „[{oszlopnév -> oszlopérték}, … , {oszlopnév -> oszlopérték}]” formában jeleníti meg. A DataFrame JSON formátuma most „nyomtatásra” van állítva, és a terminálon is megjelenik.
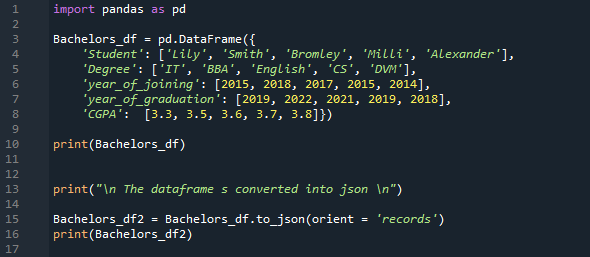
A DataFrame itt egyszerűen csak oszlopok és sorok formájában jelenik meg, de JSON formátumban észreveheti, hogy megadja az oszlop nevét, majd megjeleníti az oszlop értékét; az egyik oszlop értékének megjelenítése után kiírja a második oszlop nevét, majd berakja az oszlop értékét, és így tovább, mert a „to_josn” metódus paraméterét „orient= records”-ként állítottuk be.

04. példa
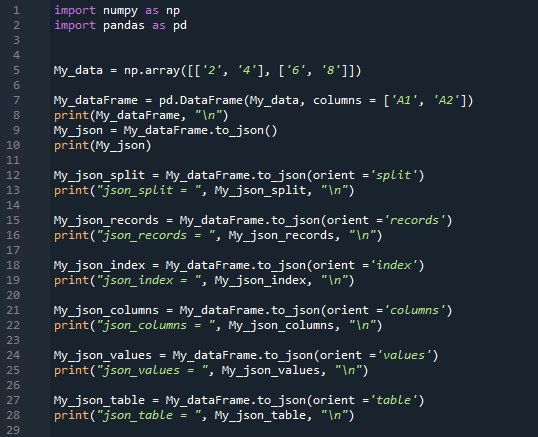
Létrehozunk egy „My_data” számszerű tömböt, amelybe beillesztjük a „2, 4” és „6, 8” számokat. Ezután módosítsa a numpy tömböt a DataFrame „My_dataFrame”-re, és állítsa be az oszlopneveket „A1 és A2”-re. Most, miután megjelenítette a DataFrame-et itt a „print” használatával. Először a „to_json()” metódust használjuk paraméterek nélkül, és megjelenítjük. Ezt követően a „to_json()” metódusok paraméterét „orient=split”-re állítjuk, és ki is nyomtatjuk ezt a formátumot. Ezután ismét alkalmazzuk a „to_josn()”-t a „My_dataFrame”-re, és ezúttal az „orient=records”-t adjuk meg ennek a függvénynek a paramétereként.
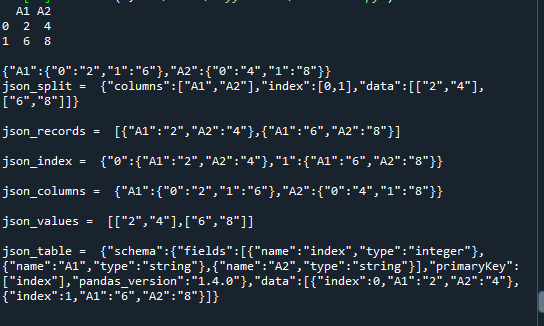
Ez alá helyezzük az „orient= index”-et a „My_dataFrame”-vel, és ezt a JSON-formátumot jelenítjük meg. E paraméter után ismét használjuk a „to_json” paramétert az „orient = column” paraméterrel, és azt is rendereljük. Ezután a „to_json()” metódus paramétereként az „orient= értékeket” adjuk át, és alkalmazzuk a „My_dataFrame”-re. Ennek a függvénynek a paraméterét is beállítottuk az „orient= table” értékre, és ismét ugyanazzal a DataFrame-mel használjuk, és ezt a JSON formátumot is megjelenítjük. Most megjegyezzük a JSON formátumai közötti különbséget a kód kimenetében.
Itt könnyen megtalálhatja a különbséget a JSON formátumai között, amelyeket ugyanarra a DataFrame-re alkalmaztunk. Minden paraméter, amelyet a „to_json” metódussal átadtunk, különböző formátumokban jelenik meg itt.
Következtetés
Ez az útmutató bemutatja a JSON formátumot, és részletesen elmagyarázza ezt a JSON-formátumot, valamint azt, hogy hogyan lehet a pandas DataFrame-et JSON-ba konvertálni. Elmagyaráztuk, hogy a „to_json()” metódust használják a pandas DataFrame JSON formátumba konvertálására. Különböző paramétereket is tárgyaltunk, amelyeket itt átadtunk a „to_json()” metódusnak. Teljes útmutatót adtunk, amelyben a „to_json()” metódusokat használtuk úgy, hogy az összes lehetséges paramétert ehhez a „to_json()” metódushoz helyeztük a „pandas” kódunkban, és megmutattuk nekik a kimenetben, hogy ezek a paraméterek hogyan változtatják meg a formátumot. a JSON.