A „Pandas” egy nagy teljesítményű eszköz a python környezethez. Ez egy „nyílt” forráskód az adatok elemzéséhez. A pandák összekapcsolása és a panda egyesítése módszer a két adatkeret egyetlen adatkeretté való egyesítésére szolgál. A pandák mindkét módszerében az a különbség, hogy a pandák „join” funkciója index segítségével csatlakozik az adatkerethez. Míg a pandák „merge” funkciója az index és az oszlop metódus segítségével csatlakozik az adatkerethez, amelyben mi magunk választhatjuk ki a kívánt oszlopot. A pandák összevonási módszerét leginkább a pandák összekapcsolási módszeréhez képest alkalmazzák. A megvalósításhoz a „spyder” szoftvert fogjuk használni, amely a python környezetben található, és a pandas join metódus() és a pandas merge() metódusfüggvény kódmegvalósításában nyújt előnyöket.
A Pandas Join() metódus szintaxisa
„df1. csatlakozik ( df2 ) ”A fenti szintaxisban a „df” az „adatkeret” rövidítése. A szintaxisban két adatkeret található a „dot join” funkcióval, amely a metódus meghívására szolgál. Ez a panda módszer két adatkeret összekapcsolására. Úgy működik, hogy az index segítségével egyesíti az adatkereteket egyetlen keretben.
A Pandas Merge() metódus szintaxisa
„df1. összeolvad ( df2 , tovább = 'oszlop_neve' ) ”A pandák egyesítése módszerének szintaxisa két adatkerettel rendelkezik: „df1” és „df2”. A „pont-összevonás” funkció a két adatkeret összekapcsolásának módszerét hívja elő az oszlopok fordított megjelenésével.
Két adatkeret kombinálásának alábbi módjait fogjuk ismertetni a panda összevonás és a panda csatlakozás módszereinek használatához:
- Pandas Join metódus átfedés.
- A pandák index-visszaállítással csatlakoznak a módszerhez.
- Pandák egyesítési módszere ('bal és jobb' oszlop).
- A pandák egyesítési módszere explicit.
Adatkeretek létrehozása a Pandas Merge és Pandas Join Method megvalósításához
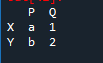
Először is létre kell hoznunk egy adatkeretet. Ehhez a „spyder” eszközt fogjuk használni. A megnyitás után kezdje el írni a kódot. Importálja a pandákat „pd”-ként a pandakönyvtári egyesület számára. Az adatkeret változók megfelelően „x”, „y”, „p” és „q”, „a” pedig „1” és „b” értékkel, a hozzárendelt érték pedig „2”.

A kimenet egy „df” a hozzárendelt értékekkel. Olyan nagyra tehetjük, amennyi az adat.
Újabb adatkeret létrehozása
Létre kell hoznunk egy másik adatkeretet, hogy világosan megértsük a pandák egyesülésének és összeolvadásának módszereit. Itt a „df” ugyanazt hoztuk létre, mint a fenti „df”, csak a hozzárendelt változók értékei különböznek. Van „h”, „j”, „s” és „d”, míg a „b” értéket „8”, az „Y” pedig „3” értékkel rendeli.

A kimenet egy egyszerű „df”-et jelenít meg.

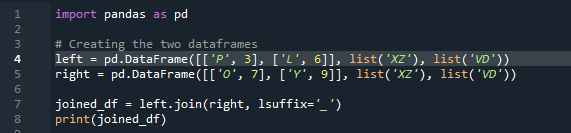
01. példa: Pandák csatlakozási módszere (átfedés)
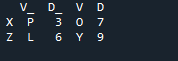
Most meglátjuk, hogyan lehet két adatkeretet összekapcsolni a panda join metódussal. Ehhez a módszerhez kiválaszthatjuk az adatkeretből azt az oszlopot, amelyen dolgozni szeretnénk. A példát a „df”-ből „balra” átfedő oszloppal vettük, így ezt az „utótaggal” javíthatjuk, hogy kiküszöböljük az adatok átfedését. Itt az „x”, „z”, „v”, „d” változókat használjuk. „p”, „o”, „l” és „y” a „3”, „6”, „7” és „9” értékekkel. A „.join” meghívja a metódust, az igazítást balra illesztve a jobb oldali „df” utótaggal. ”. A kódban használt „utótag” azért van, mert az adatkeretben van két azonos nevű oszlop, amely „kulcs”, és amelyek nem fedik át az adatokat.
A kimenet nem jelenít meg átfedő adatokat a két „df” összekapcsolásának módszerével a panda join módszerrel.
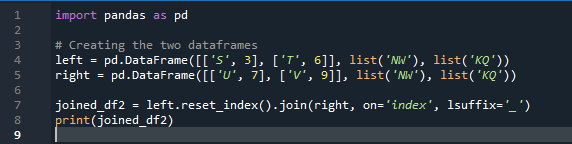
02. példa: Pandák csatlakozási módszere index-visszaállítással
Ebben a példában külön megadjuk az „on” paraméterrel rendelkező oszlopot, amely „kulcsként” használható a metódus összekapcsolásában, amely segít a két adatkeret összekapcsolásában. a kombinált dolog ezzel a paraméterrel történik. Ezenkívül a két „df” közül az egyik indexének hasonlónak kell lennie ahhoz, hogy csatlakozzon hozzájuk. Hasonló típusú vagy azonos célra felhasznált adatok együttesen is feldolgozhatók. Ez az indexet fogja használni, a jobb oldali használatával. A változók az „s”, „t”, „u”, „v”, „n”, „w”, „k” és „q”. A hozzárendelt értékek: „3”, „6”, „7” és „9”. A „pontindex visszaállítása” a pandák módszere a „df” indexének visszaállítására. A reset index beállítja az adatkeret lista összes egészét 0-tól egészen addig, amíg az adatkeret adatai meg nem hosszabbodnak.
Itt látható a kimenet a pandák index „kulcs” csatlakozási módszerével.
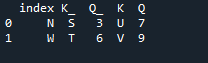
03. példa: Pandák egyesítési módszere ('bal és jobb' oszlop)
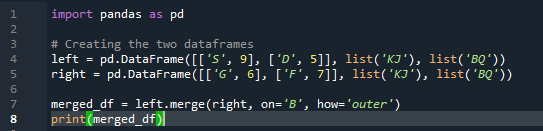
Az egyesítési módszer hasonló műveletet hajt végre, mint a panda join metódus. Mindkét módszer egy hasonló adatkereten lévő adatok kombinálására szolgál. Az egyesítési módszer sokoldalúbb, megköveteli a kulcs megadását. A bal és jobb oldali oszlopokban is megadhatjuk az adatkeret működésétől függően. A kód változói: „s”, „d”, „g”, „f”, „k”, „j”, „b” és „q”. a hozzárendelt értékek „9”, „5”, „6” és „7”. A külső „join” implementáció mindkét „df”-en megtörténik a pandas merge metódus függvény „how” paraméterének használatával.
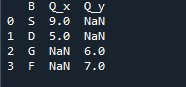
A látott kimenet a két adatkeret egyesített adatait mutatja. A „NaN” azt jelenti, hogy „nem szám”, ami azt jelenti, hogy ahol nincs szám az adatokban, ott a „NaN” jelenik meg.
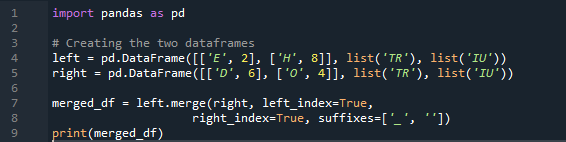
04. példa: Az egyesítési módszer kifejezetten
Ebben a példában az összevonási módszer az index megsemmisítése, és az indexértéket nem feltételezzük az adatkereten. Ezt a módszert az elvégzendő munkának megfelelően fogjuk végrehajtani, ahol a megjelölő explicit a nyomon követés. A bal oldali index vagy a jobb oldali index alapján egyesíti az adatokat a paraméterrel. Ebben az adatkeretben a változók a következők: „t”, „r”, „I”, „u”, „h”, „o”, „e” és „e”. A hozzárendelt értékek „2”, „4”, „6” és „4”. A fenti példa a pandák egyesítési módszerére az igény szerinti oszlopválasztással a két adatkeret összekapcsolásának leglátványosabb és legértékesebb módja. A kódsor végén annak ellenőrzése, hogy az egyesítő kulcs egyedi-e az adatkészletben.
Az alábbi kimenetben az index nem jelenik meg index nélkül, hanem a funkció a jobb és bal index alapján történik.
Következtetés
A merge() és a join() metódusok nagyon kényelmesek és hatékonyak. Mindkét funkció a két különálló adatkeret egyazon adatkereten belüli összekapcsolására szolgál, de esettől függően eltérő felhasználásuk van. Ebben a cikkben megismertük a fő különbségeket a pandák csatlakozási és egyesítési módszerei között. A példák elvégzése és a panda join metódus megértése után azzal a tudattal zárjuk le, hogy ha rugalmasabb és adatbázis-stílusú csatlakozást szeretnénk, akkor érdemes a panda-összevonási módszert választani. Másrészt, ha az indexszel való adatkeret-kombinációt széles körben szeretnénk elvégezni, akkor a pandas join() metódusfüggvényt is használhatjuk.