„A „Pandas” nagyszerű nyelv az adatok elemzéséhez az adatközpontú python-csomagok nagyszerű ökoszisztémájának köszönhetően. Ez megkönnyíti mindkét tényező elemzését és importálását. A szórás az átlagból származtatott „tipikus” eltérés. Sokat használják, mivel az adatkeret eredeti mértékegységeit adja vissza. A pandák az std() függvényt használták a szórás kiszámításához. A szórást a megadott értékekből lehet kiszámítani, amelyek sor vagy oszlop formájában lehetnek az adatkeretben. Meg fogjuk valósítani a pandák szórásának minden lehetséges módját. A kód megvalósításához a „spyder” eszközt fogjuk használni, ahogy az egy python-barát környezetben van írva.”
Szintaxis
„df.std ( ) ”
A következő szintaxist használjuk az adatkeret szórásának kiszámításához. A „df” az adatkeretben az „adatkeret” rövidítése. Mit csinál a szórás? Azt méri, hogy a szükséges adatok mennyire kiterjedtek. Minél nagyobb a magas értékek kiterjesztése, annál nagyobb a szórás.
Visszatérés
A panda szórása visszaadja az adatkeretet, ha a szint a követelmény alapján van megadva.
Vegye figyelembe, hogy az „std()” függvény automatikusan figyelmen kívül hagyja a „df” „NaN” értékeit a pandák szórásának kiszámításakor. A „NaN” úgy magyarázható, hogy „nem szám”, ami azt jelenti, hogy nincs érték hozzárendelve egy adotthoz.
A következő módszereket hajtjuk végre a pandák szórásának példáival:
-
- Pandák szórásának számítása egyetlen oszlopban.
- Pandák szórás számítása több oszlopban.
- Pandák szórás számítása minden numerikus oszlopra.
- pandák szórása a tengely segítségével = 1.
- panda szórása a tengely segítségével = 0.
Adatkeret létrehozása a szórás kiszámításához pandákban
Először nyissa meg a „spyder” szoftvert. Most importálja a pandas könyvtárat pd-ként. Létrehozunk egy adatkeretet, amely egy „x”, „y” és „z” kifejezéseket tartalmazó eredménytáblából áll, amelyek pontjai „22”, „10”, „11”, „16”, „12”, „45” ”, „36” és „40”. A gólpasszok értékei „8”, „9”, „13”, „7”, „22”, „24”, „4” és „6”, a lepattanók értéke „17”, „ 14', '3', '5', '9', '8', '7' és '4'.
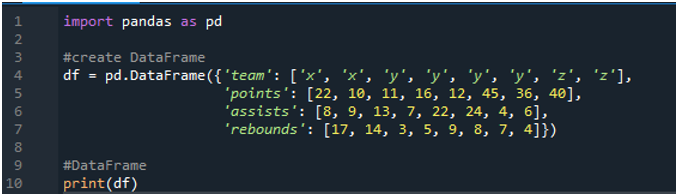
A kijelzők a létrehozott adatkeretet mutatják a kódban hozzárendelt értékek szerint:

01. példa: Pandák szórásának kiszámítása egyetlen oszlopban
Ebben a példában a pandák adatkeretében lévő egyetlen oszlop szórását fogjuk kiszámítani. Az adatkeretben a csapat értékei „u”, „v” és „b”, a pontjaik pedig „44”, „33”, „22”, „44”, „45”, „88”, „96” ” és „78”. A gólpasszok értéke '7', '8', '9', '10', '11', '14', '18' és '17', a lepattanók értéke is '11', ' 9', '8', '7', '6', '5', '4' és '3'. A „pontok” oszlop az adatkeretből van kiválasztva az egyoszlopos szórás kiszámításához.
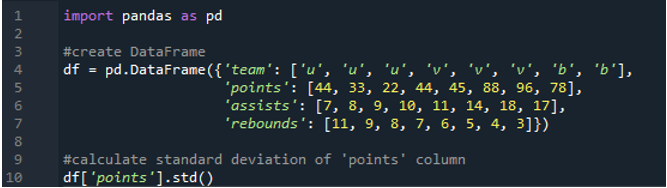
A kimenet a „pontok” oszlopból számított szórást mutatja:

02. példa: Pandák szórásának kiszámítása több oszlopban
Ebben a példában a pandák szórásának számításait több oszlopban hajtjuk végre. Ebben az adatkeretben ismét a sporteredménytáblázat adatai szerepelnek, ahol a csapat értéke „n”, „w” és „t”, a pontszám pedig „33”, „22”, „66”, „55”, „44”, „88”, „99” és „77”. A gólpasszok '9', '7', '8', '11', '16', '14', '12' és '13', a lepattanók pedig '5', '8', '1', ' 2', '3', '4', '6' és '7'. Itt az adatkeretre alkalmazott std() függvény segítségével kiszámítjuk a két oszlop „pontok” és „lepattanók” szórását.
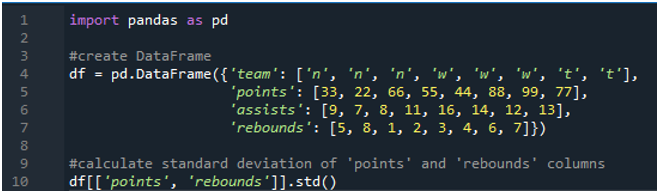
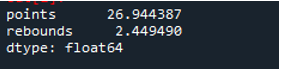
Amint látjuk, a kimenet azt mutatja, hogy a szórás értéke 26,944387 a pontok oszlopában és 2,449490 a felpattanó oszlopban.
03. példa: Pandák szórásának kiszámítása az összes numerikus oszlopra
Most megtanultuk, hogyan kell kiszámítani az egy- és többsoros szórását. Mi van, ha nem akarjuk megadni az összes oszlopnevet az adatkeretben, és a teljes adatkeretet kiszámítani? Ez lehetséges a pandák szórásának egy egyszerű függvény implementációjával a teljes adatkeret kiszámításához az eredményekben. Az adatkeret itt „l”, „m” és „o” karakterekből áll, a „33”, „36”, „79”, „78”, „58”, „55” pontozási értékekkel, és két csapat ugyanannyit ér el. vagyis „25”. A gólpasszok: „1”, „2”, „3”, „4”, „6”, „9”, „5” és „7”, a lepattanók pedig „14”, „10”, „2” , '5', '8', '3', '6' és '9'. Az adatkeretben lévő pandák összes szabványos oszlopeltérését ki tudjuk számítani a panda „std()” függvény segítségével.
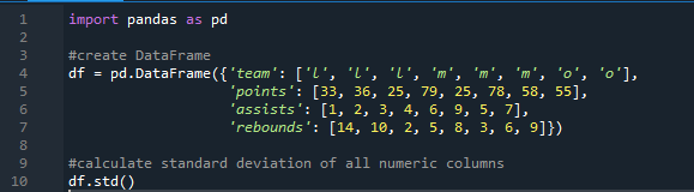
A kijelzőn látható az alább látható teljes „df” számított szórása; Azt is észrevehetjük, hogy a pandák nem számolták ki az első oszlop szórását, ami a „csapat”, mert az nem numerikus oszlop.
04. példa: Pandák szórása a tengely használatával = 0
Ebben a példában az adatkeretekben a sportágak csapatai „g”, „h” és „k” további adatokkal szerepelnek. Itt a szórást úgy fogjuk kiszámítani, hogy a tengelyt „0”-ként használjuk, amely paraméter a pandák szórásában használatos. Ez az argumentum kiszámítja az adatkeret szórását oszloponként.
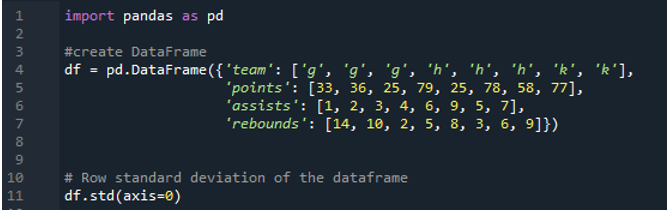
A következő kimenet a számított szórás oszlopaiban jeleníti meg az eredményeket. A pontoszlop számított szórása „24,0313062”, a gólpassz oszlopban a számított szórása „2,669270”, a visszapattanó oszlop számított szórása pedig „3,943802”.
05. példa: Pandák szórása a tengely használatával = 1
Itt az „1”-hez rendelt tengelyparamétert fogjuk használni a pandák szórásának kiszámításához. Milyen különbséget jelenthet az „1” tengely? Az „1” tengely argumentum kiszámítja az adatkeretben lévő számértékek soronkénti szórását. Az adatkeretben a három csapat „s”, „d” és „e” szerepel, hozzáadva a csapat pontjaiként létrehozott adatoszlopokat, a csapat gólpasszait és a csapat lepattanóit. Az útvonalak mindegyike különböző értékekkel van hozzárendelve az adatkeretben. Ez a tengelyparaméter olyan játékmódosító, hogy addigra az elvégzett szórással számított oszlopban, ahol szeretnénk, ott kell dolgoznunk az adatokon.
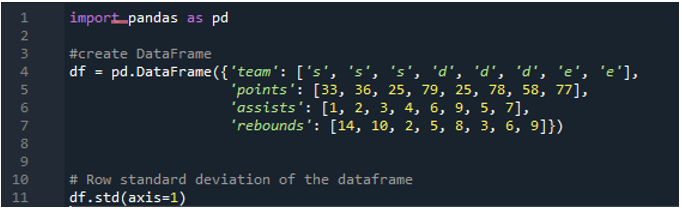
A következő kimenet az adatkeret sorában kiszámított szórást jeleníti meg:
Következtetés
A pandák szórása egy nagyon technikai függvény, ami nagyon előnyös függvény, mivel megkeresi a panda adatkeretek lelkesedési paktumának szórását. Ebben a vezércikkben a pandák szórásának számítási módszereit tanulmányoztuk. Elvégeztük a szórás egyoszlopos és több oszlopos számítását, valamint a teljes adatkeret szórását együtt. Minden stratégia jól működik mindaddig, amíg következetesen és a kívánt eredménnyel használják őket.