A Pandas hozzáférést biztosít a kritikus szempontok és utasítások széles skálájához, amelyek célja az adatok gyors kiértékelése. Kihasználjuk a Pandas DataFrame-ek HTML-táblákká alakításának folyamatát. A fejlesztőknek és a felhasználóknak integrálniuk kell Python DataFrame-eiket egy HTML-forráskódba. Ezzel a Pandas kiterjesztéssel könnyedén áthelyezik adataikat egy HTML-fájlba erre a célra a Pandas to HTML technikával. A módszertan elmagyarázásához az implementációhoz a „Spyder” eszközt használjuk, hogy lépésről lépésre könnyen érthető legyen az egyes implementációk mellett.
Ha egy helyi HTML-fájlt szeretnénk elemezni a Pandasban, akkor a címke nevét és szöveges aspektusait használjuk. A fájlból származó tag-ul kóddal együtt személyre szabhatjuk a címke címét és tartalmát. Ha meg akarjuk kapni a HTML-fájlt az URL-ből a Pandasban, akkor végig kell vennünk néhány lépést, amelyek tartalmazzák a web URL-paramétert a vizsgálati funkció meghívásához. Ezután hivatkozunk azokra a változókra, amelyek lehetővé teszik az adatbázis-objektumokból való átolvasást, és beolvassuk a teljes URL belsejét az adatváltozóba, hogy lefuttassa a kódot, és az adatokat HTML formátumban nyomtatja ki.
Pandák szintaxisa HTML-re:

Példa: Jelenítse meg egy Pandas DataFrame renderelését HTML kódba és táblázatba
Egy HTML-weboldalon a Pythonban lévő Pandas képes a Pandas DataFrame-et HTML-táblázattá alakítani. A Pandas DataFrame a „pandas.DataFrame.to html()” metódussal kerül végrehajtásra. Nézzük meg példánkat, és beszéljük meg a Python DataFrame HTML-forráskóddal történő átalakításának eljárását. Ennek eléréséhez először meg kell terveznünk a DataFrame-et, amely végül HTML-be kerül. Annak érdekében, hogy a Pandas filozófiát alkalmazzuk a Python kódunkra, a Pandas könyvtárat „pd” néven importáljuk.
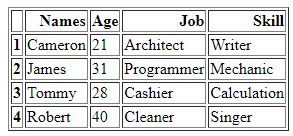
A DataFrame „Tagok” a tag információihoz kapcsolódó szótárakat tartalmazza a négy deklarált változóval együtt: „Név”, „Kor”, „Munka” és „Képesség”. Az első sorban a „Cameron” a „nevek”, a „21” az „életkor”, az „Architect” a „Job” és a „Writer” a „Skill” adatok tárolódnak. Ily módon az általunk hozzárendelt DataFrame inicializált értékek második sora a „James”, a „31”, a „Programmer” és a „Mechanic” a megfelelő oszlopokban. Ily módon a másik szótár adatai között szerepel a „Tommy”, „28”, „Pénztár” és „Számítás”. Az utolsó sor, amelyet a DataFrame-ünkhöz rendelünk, tartalmazza a „Robert” értéket a „Nevek”, a „40” az „Age”, a „Cleaner” a „Job” és az „Singer” adatot. „Képesség”.
A továbbiakban a DataFrame-ünkhöz hozzárendelve az „index” tartományt is megadjuk nekik „1” és „4” között, mivel a DataFrame négy soros lehet. Ezt követően a „pd.dataframe()” függvény segítségével egyesítjük az adatokat az indexszámokkal együtt. Végül a „print()” függvényt használjuk a DataFrame megjelenítésére.
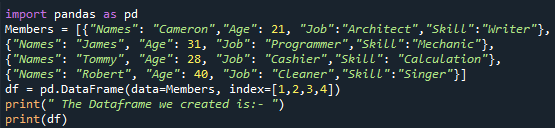
Most láthatjuk az általunk létrehozott DataFrame „tagjaink” megjelenítését. Itt láthatjuk, hogy ez a DataFrame egyszerű megjelenítése, amelyet HTML-forrássá alakítunk. Egyszerűen négy oszlopa van – „Nevek”, „Életkor”, „Munka” és „Képesség” – minden hasonló adattal, amelyet a DataFrame-ünkhöz rendelünk a kódban. Sorainak indexszáma „1”, „2”, „3” és „4”. Ennél a lépésnél látjuk, hogy létrehozzuk a DataFrame „tagjainkat”. A DataFrame létrehozása után folytatjuk a további megvalósítást.
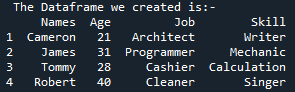
Most ez az a lépés, ahol meglátjuk, hogyan alakíthatjuk át a DataFrame „tagjainkat” HTML kóddá. Itt az ideje, hogy megértsük a Python DataFrame to html() metódusát, amely a DataFrame-et HTML-vé fejleszti. A html() függvény megváltoztatja a teljes DataFrame-et, ami azt eredményezi, hogy a DataFrame minden sora különálló sorozat lesz a HTML-táblázatban. Ebből a célból deklaráljuk a „html” változót, és a „df.to_html()” függvény segítségével tároljuk, hogy a teljes DataFrame-ünket HTML kóddá alakítsuk. A „df.to_html()” függvény megvalósítása után a „html” könyvtárban alkalmazzuk a „print()” függvényt.

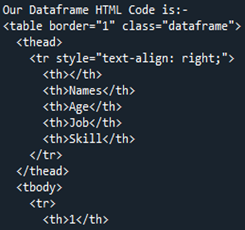
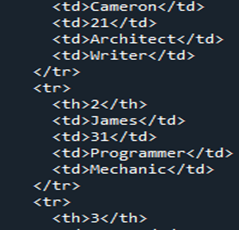
Most nézzük meg a HTML-kódot, amelyet a Pandas DataFrame „Members”-ből konvertáltak. Ez a módja annak, hogy bármelyik DataFrame-ünket HTML-forráskóddá alakítsuk, amely a teljes DataFrame-et HTML-kódban írja le, beleértve az összes olyan címkét, amelynek táblázatszegélye „1”. Az oszlopnevek a HTML-elem táblázatfejléceként a „” alá vannak beágyazva, míg a teljes DataFrame egy „ Mivel a DataFrame-ünkben négy sor volt, a „ Most elmentjük a HTML kódunkat az aktuális futó könyvtárba „jelként”, a „.html” kiterjesztéssel együtt. Az „open()” függvényt használjuk a fájl helyének meghatározásához: „file=open(“signal.html”, „w”). Mivel a „w” hely kulcsszó tárolja a fájl megjelenítéséhez és HTML formában való közzétételéhez, a „.write()” függvényt használjuk, és a Pandas kódunkat a fájl „close()” függvényével együtt leállítjuk. Az egyszerűbb esetek többségéről beszélünk, amellyel elmentjük a „.html” fájlkiterjesztéssel együtt, amely HTML-be konvertálja, és ugyanabban a könyvtárban biztosítja a böngésző felületét. A DataFrame „tagjaink” HTML-be átalakítása után megkapjuk a HTML kódunkat, amelyet először elmentünk ugyanabba a könyvtárba. Amikor megkapjuk a HTML forráskódunkat, a webkiterjesztéssel együtt megnyithatjuk a HTML forrásfájl böngészővel való megnyitásával. Látjuk, hogy a kimenetet HTML-táblaként jeleníti meg a böngésző oldalon. Amint azt a táblázat kimenetén láthatjuk, az „1” szegélyméretet tartalmazza, és nincs cellatávolság mellettük. A táblázat öt oszlopot mutat. Ebből négy oszlopnév: „Nevek”, „Kor”, „Munka” és „Képesség”. Ha az „1” indexszámról beszélünk, akkor a „Nevek” oszlopban a „Cameron”, az „Age” oszlopban a „21”, a „Job”-ban az „építész”, a „Képességben” pedig az „Író” szerepel. A táblázatban szereplő „2” indexszám a „Nevek” részben a „James”-t, az „Életkorban” a „31”-et, a „Munkakörben” a „Programozót”, a „Képességben” pedig a „szerelőt” mutatja. A „Nevek” oszlop „3” indexében „Tommy”, „28” az „Életkor”, „Pénztár” a „Munka” és „Számítás a „Képesség” oszlopban a böngészőoldalon. A táblázat utolsó sorának „4” indexe „Róbert” a „Nevek”, „40” az „Age”, „Cleaner” a „Job” és „Singer” a „Képesség” között. Annak érdekében, hogy a DataFrame-et a cikk HTML-forráskódjává alakíthassuk, először a „Members” néven állítottuk össze. Amikor egy DataFrame-et HTML kódba renderelünk, a „html = df.to html()” függvényt használjuk. A HTML tábla megjelenítésekor a „file = open(“signal.html”, „w”)” könyvtárat és a „signal.html” fájl helyét használjuk, amelyek ugyanabba a könyvtárba kerülnek. Ennek révén a Pandas DataFrame-ünket HTML forráskódfájllá tudtuk alakítani és táblázattal is megjeleníteni.” HTML-elemmé módosul. Ezenkívül a DataFrame minden sora sorrá alakul a „
” címkével együtt a HTML-táblázatban. A „” a „CSS” néhány elemét használja a táblázat sorát leíró „ ” címkével együtt.
” négyszer használatos a záró címkéikkel együtt. Amint azt a HTML-ben tudjuk, nyitó és záró címkéket is tartalmaznia kell a megfelelő HTML-kódban. Az összes adat vagy DataFrame a nyitó „ ” és „
” és a záró címke közé van zárva. A teljes HTML-kód többi része ugyanazokat az adatokat tartalmazza, mint a DataFrame-ben, csak egyszerű HTML-forráskóddá alakítják át a táblázat létrehozásához szükséges címkékkel együtt.

Következtetés