Gyors vázlat
Ez a bejegyzés a következőket mutatja be:
- Memória hozzáadása az OpenAI Functions Agenthez a LangChainben
- 1. lépés: Keretrendszerek telepítése
- 2. lépés: Környezetek beállítása
- 3. lépés: Könyvtárak importálása
- 4. lépés: Adatbázis létrehozása
- 5. lépés: Adatbázis feltöltése
- 6. lépés: Nyelvi modell konfigurálása
- 7. lépés: Memória hozzáadása
- 8. lépés: Az ügynök inicializálása
- 9. lépés: Az ügynök tesztelése
- Következtetés
Hogyan lehet memóriát hozzáadni az OpenAI Functions Agenthez a LangChainben?
Az OpenAI egy mesterséges intelligencia (AI) szervezet, amely 2015-ben alakult, és kezdetben non-profit szervezet volt. A Microsoft 2020 óta rengeteg vagyont fektetett be, mivel a természetes nyelvi feldolgozás (NLP) az AI-val virágzik a chatbotokkal és a nyelvi modellekkel.
Az OpenAI-ügynökök létrehozása lehetővé teszi a fejlesztők számára, hogy olvashatóbb és pontosabb eredményeket kapjanak az internetről. A memória hozzáadásával az ügynökök jobban megérthetik a csevegés kontextusát, és a korábbi beszélgetéseket is a memóriájukban tárolhatják. A LangChain OpenAI függvényügynökéhez való memória hozzáadásának folyamatának megismeréséhez egyszerűen hajtsa végre a következő lépéseket:
1. lépés: Keretrendszerek telepítése
Először is telepítse a LangChain függőségeket a „langchain-kísérleti” keretrendszer a következő kóddal:
pip install langchain - kísérleti
Telepítse a 'google-search-results' modul a keresési eredmények lekéréséhez a Google szerverről:
pip install google - keresés - eredmények 
Telepítse továbbá az OpenAI modult, amellyel a LangChain nyelvi modelljeit készítheti:
pip install openai 
2. lépés: Környezetek beállítása
A modulok beszerzése után állítsa be a környezeteket az API-kulcsok segítségével OpenAI és SerpAPi fiókok:
import teimport getpass
te. hozzávetőlegesen, körülbelül [ 'OPENAI_API_KEY' ] = getpass. getpass ( 'OpenAI API kulcs:' )
te. hozzávetőlegesen, körülbelül [ 'SERPAPI_API_KEY' ] = getpass. getpass ( 'Serpapi API kulcs:' )
Futtassa a fenti kódot az API-kulcsok megadásához mindkét környezet eléréséhez, majd nyomja meg az Enter billentyűt a megerősítéshez:
3. lépés: Könyvtárak importálása
Most, hogy a telepítés befejeződött, használja a LangChainből telepített függőségeket a memória és az ügynökök felépítéséhez szükséges könyvtárak importálásához:
a langchainből. láncok import LLMMathChaina langchainből. llms import OpenAI
#get könyvtárat keresni a Google-tól az interneten keresztül
a langchainből. segédprogramok import SerpAPIWrapper
a langchainből. segédprogramok import SQLDatabase
innen: langchain_experimental. sql import SQLDatabaseChain
#szerezzen könyvtárat eszközök készítéséhez számára az ügynök inicializálása
a langchainből. ügynökök import AgentType , Eszköz , inicializálás_ügynök
a langchainből. chat_models import ChatOpenAI
4. lépés: Adatbázis létrehozása
Az útmutató folytatásához létre kell hoznunk az adatbázist, és csatlakoznunk kell az ügynökhöz, hogy válaszokat kapjunk belőle. Az adatbázis felépítéséhez le kell tölteni az SQLite-t ezzel útmutató és erősítse meg a telepítést a következő paranccsal:
sqlite3A fenti parancs futtatása a Windows terminál megjeleníti az SQLite telepített verzióját (3.43.2):
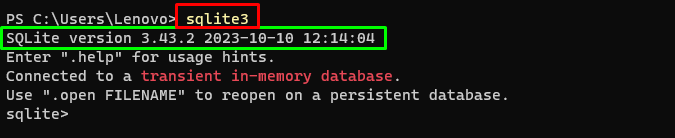
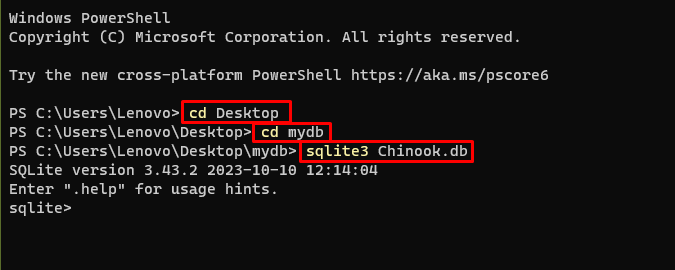
Ezután egyszerűen lépjen a számítógépén lévő könyvtárba, ahol az adatbázis létrejön és tárolódik:
cd asztalicd mydb
sqlite3 Chinook. db
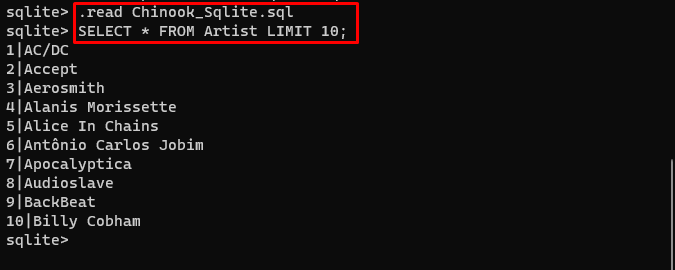
A felhasználó egyszerűen letöltheti innen az adatbázis tartalmát link a könyvtárba, és futtassa a következő parancsot az adatbázis felépítéséhez:
. olvas Chinook_Sqlite. sqlKIVÁLASZTÁS * FROM előadó LIMIT 10 ;
Az adatbázis sikeresen elkészült, és a felhasználó különböző lekérdezések segítségével kereshet benne adatokat:
5. lépés: Adatbázis feltöltése
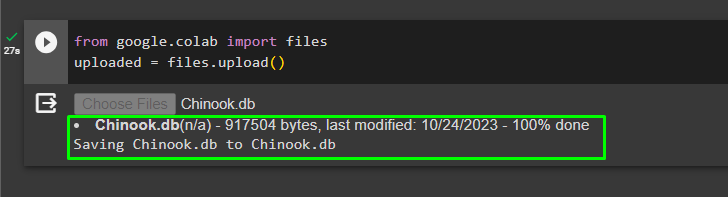
Az adatbázis sikeres felépítése után töltse fel a '.db' fájlt a Google Colaboratorynak a következő kóddal:
a google-ból. ET AL import fájlokatfeltöltve = fájlokat. feltölteni ( )
Válassza ki a fájlt a helyi rendszerből a gombra kattintva „Fájlok kiválasztása” gombot a fenti kód végrehajtása után:
A fájl feltöltése után egyszerűen másolja ki a fájl elérési útját, amelyet a következő lépésben fog használni:
6. lépés: Nyelvi modell konfigurálása
Készítse el a nyelvi modellt, láncokat, eszközöket és láncokat a következő kóddal:
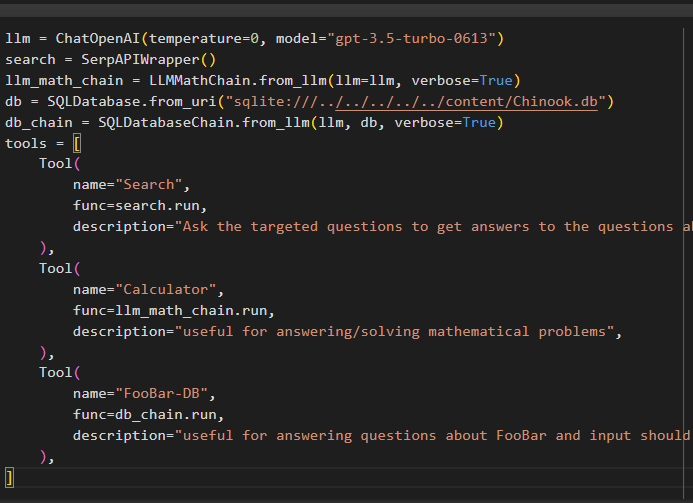
llm = ChatOpenAI ( hőfok = 0 , modell = 'gpt-3.5-turbo-0613' )keresés = SerpAPIWrapper ( )
llm_math_chain = LLMMathChain. from_llm ( llm = llm , bőbeszédű = Igaz )
db = SQLDatabase. from_uri ( 'sqlite:///../../../../../content/Chinook.db' )
db_lánc = SQLDatabaseChain. from_llm ( llm , db , bőbeszédű = Igaz )
eszközöket = [
Eszköz (
név = 'Keresés' ,
func = keresés. fuss ,
leírás = 'Tegye fel a célzott kérdéseket, hogy választ kapjon a közelmúlt ügyeivel kapcsolatos kérdésekre' ,
) ,
Eszköz (
név = 'Számológép' ,
func = llm_math_chain. fuss ,
leírás = 'hasznos matematikai feladatok megválaszolásához/megoldásához' ,
) ,
Eszköz (
név = 'FooBar-DB' ,
func = db_lánc. fuss ,
leírás = 'hasznos a FooBar-ral kapcsolatos kérdések megválaszolásához, és a bemenetet teljes kontextust tartalmazó kérdés formájában kell megadni' ,
) ,
]
- A llm változó tartalmazza a nyelvi modell konfigurációit a ChatOpenAI() metódus használatával a modell nevével.
- A keresés változó tartalmazza a SerpAPIWrapper() metódust az ügynök eszközeinek felépítéséhez.
- Építsd meg a llm_math_chain hogy az LLMMathChain() metódus segítségével megkapjuk a matematika tartományhoz kapcsolódó válaszokat.
- A db változó az adatbázis tartalmát tartalmazó fájl elérési útját tartalmazza. A felhasználónak csak az utolsó részt kell módosítania „content/Chinook.db” az utat tartó 'sqlite:///../../../../../' ugyanaz.
- Hozzon létre egy másik láncot az adatbázisból származó lekérdezések megválaszolásához a db_lánc változó.
- Konfigurálja az eszközöket, mint pl keresés , számológép , és FooBar-DB a válasz kereséséhez, a matematikai kérdések megválaszolásához és a lekérdezésekhez az adatbázisban:
7. lépés: Memória hozzáadása
Az OpenAI függvények konfigurálása után egyszerűen készítse el és adja hozzá a memóriát az ügynökhöz:
a langchainből. felszólítja import MessagesPlaceholdera langchainből. memória import ConversationBufferMemory
agent_kwargs = {
'extra_prompt_messages' : [ MessagesPlaceholder ( változó_neve = 'memória' ) ] ,
}
memória = ConversationBufferMemory ( memória_kulcs = 'memória' , return_messages = Igaz )
8. lépés: Az ügynök inicializálása
Az utolsó összeállítandó és inicializálandó komponens az ügynök, amely tartalmazza az összes összetevőt, például llm , eszköz , OPENAI_FUNCTIONS és más, ebben a folyamatban használandó:
ügynök = inicializálás_ügynök (eszközöket ,
llm ,
ügynök = AgentType. OPENAI_FUNCTIONS ,
bőbeszédű = Igaz ,
agent_kwargs = agent_kwargs ,
memória = memória ,
)
9. lépés: Az ügynök tesztelése
Végül tesztelje az ügynököt úgy, hogy elindítja a csevegést a „ Szia ” üzenet:
ügynök. fuss ( 'Szia' ) 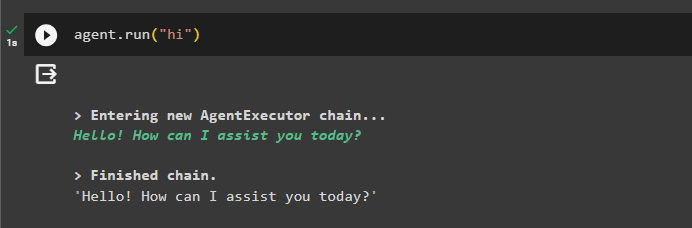
Adjon hozzá néhány információt a memóriához az ügynök futtatásával:
ügynök. fuss ( 'A nevem John Snow' ) 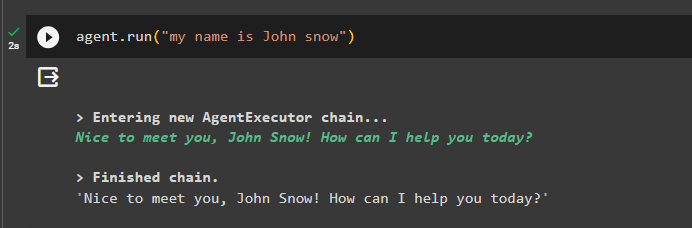
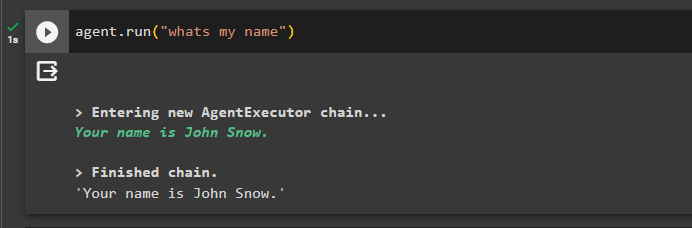
Most tesztelje a memóriát úgy, hogy felteszi a kérdést az előző csevegésről:
ügynök. fuss ( 'mi a nevem' )Az ügynök a memóriából lekért névvel válaszolt, így a memória sikeresen fut az ügynökkel:
Ez minden most.
Következtetés
A memória hozzáadásához a LangChain OpenAI-függvényügynökéhez telepítse a modulokat, hogy megkapja a függőségeket a könyvtárak importálásához. Ezt követően egyszerűen készítse el az adatbázist, és töltse fel a Python notebookba, hogy használható legyen a modellel. Konfigurálja a modellt, az eszközöket, a láncokat és az adatbázist, mielőtt hozzáadja őket az ügynökhöz, és inicializálja azt. A memória tesztelése előtt építse fel a memóriát a ConversationalBufferMemory() segítségével, és adja hozzá az ügynökhöz, mielőtt tesztelné. Ez az útmutató részletesen bemutatja, hogyan lehet memóriát hozzáadni az OpenAI függvényügynökhöz a LangChainben.