Ez a cikk azt tárgyalja, hogyan használható az Elasticsearch többfunkciós API több JSON-dokumentum lekérésére az azonosítóik alapján. Ezen túlmenően, az Elasticsearch lehetővé teszi, hogy egyetlen lekérdezés használatával lekérje a dokumentumokat az indexekből, csak a dokumentumazonosítók használatával.
Fedezzük fel.
Szintaxis kérése
A következő az Elasticsearch többfunkciós API szintaxisa:
GET /_mget
GET /
A multi-get API több indexet is támogat, ami lehetővé teszi a dokumentumok lekérését akkor is, ha azok nem ugyanabban az indexben vannak.
A kérés a következő elérési út paramétereket támogatja:
-
– Annak az indexnek a neve, ahonnan a dokumentumokat le kell kérni az azonosítóik alapján.
A többi lekérdezési paramétert is megadhatja az ábrán látható módon:
- Preferencia – Meghatározza az előnyben részesített csomópontot vagy szilánkot.
- Valós idő – Ha igazra van állítva, a művelet valós időben történik.
- Frissítés – Kényszeríti a műveletet a célszilánkok frissítésére a megadott dokumentumok lekérése előtt.
- útvonalválasztás – Egy érték, amely a műveletek adott szilánkra való irányítására szolgál.
- Store_fields – A dokumentum helyett az indexben tárolt dokumentummezőket kéri le.
- _forrás – Logikai érték, amely meghatározza, hogy a kérésnek vissza kell-e adnia a _source mezőt vagy sem.
A lekérdezéshez szükség van a törzsre, amely a következő értékeket tartalmazza:
- Dokumentumok – Meghatározza a beolvasni kívánt dokumentumokat. Ezenkívül ez a szakasz a következő attribútumokat támogatja:
- _id – A céldokumentum egyedi azonosítója.
- _index – A céldokumentumot tartalmazó index.
- útvonalválasztás – A dokumentum elsődleges szilánkjának kulcsa.
- _forrás – Ha igaz, akkor az összes forrásmezőt tartalmazza; ellenkező esetben kizárja őket.
- _tárolt_mezők – A felvenni kívánt tárolt_mezők.
- Ids – A beolvasni kívánt dokumentumok azonosítói.
1. példa: Több dokumentum lekérése ugyanabból az indexből
A következő példa bemutatja, hogyan használható az Elasticsearch többfunkciós API a meghatározott azonosítókkal rendelkező dokumentumok lekéréséhez a Netflix indexéből:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: jelentéskészítés' -H 'Tartalom típusa: alkalmazás/json' -d'{
'dokumentumok': [
{
'_id': 'T3wnVoMBck2AezXPytlJ'
},
{
'_id': 'W3wnVoMBck2AezXPytlJ'
}
]
}'
Az adott kérésnek le kell kérnie a megadott azonosítókkal rendelkező dokumentumokat a Netflix indexéből. Az eredmény a képen látható:
{'dokumentumok': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ',
'_version': 1,
'_seq_no': 0,
'_primary_term': 1,
'talált': igaz,
'_forrás': {
'duration': '90 perc',
'listed_in': 'Dokumentumfilmek',
'ország': 'Egyesült Államok',
'date_added': '2021. szeptember 25.',
'show_id': 's1',
'rendező': 'Kirsten Johnson',
'release_year': 2020,
'értékelés': 'PG-13',
'Description': 'Amikor apja élete végéhez közeledik, Kirsten Johnson filmrendező leleményes és komikus módon rendezi meg halálát, hogy segítsen mindkettőjüknek szembenézni az elkerülhetetlennel.'
'type': 'Film',
'cím': 'Dick Johnson halott'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AezXPytlJ',
'_version': 1,
'_seq_no': 12,
'_primary_term': 1,
'talált': igaz,
'_forrás': {
'ország': 'Németország, Cseh Köztársaság',
'show_id': 's13',
'rendező': 'Christian Schwochow',
'release_year': 2021,
'értékelés': 'TV-MA',
'description': 'Miután családja nagy részét meggyilkolják egy terrorista merényletben, egy fiatal nőt tudtán kívül rávesznek, hogy csatlakozzon ahhoz a csoporthoz, amelyik megölte őket.'
'type': 'Film',
'title': 'I Am Karl',
'duration': '127 perc',
'listed_in': 'Drámák, nemzetközi filmek',
'szereplők': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '2021. szeptember 23.'
}
}
]
}
Leegyszerűsíthetjük a kérést úgy is, hogy a dokumentumazonosítókat egy egyszerű tömbbe helyezzük, az alábbiak szerint:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: jelentéskészítés' -H 'Tartalom típusa: alkalmazás/json' -d'{
'ids': ['T3wnVoMBck2AezXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Az előző kérésnek hasonló műveletet kell végrehajtania.
2. példa: Töltse le a dokumentumokat több indexből
A következő példában a kérelem több dokumentumot kér le különböző indexekből, amint az látható:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: jelentéskészítés' -H 'Content-Type: Application/json' -d'{
'dokumentumok': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Az eredmény a képen látható:

3. példa: Adott mezők kizárása
Egy adott kérésből kizárhatunk bizonyos mezőket a source_include és a source_exclude paraméterek használatával.
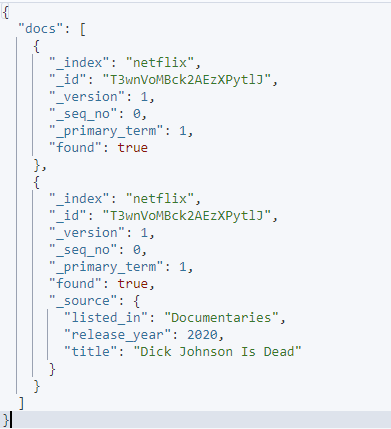
Egy példa a képen látható:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: jelentéskészítés' -H 'Content-Type: Application/json' -d'{
'dokumentumok': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ',
'_source': hamis
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ',
'_forrás': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'leírás', 'típus', 'date_added' ]
}
}
]
}'
Az adott kérés a forrásbefoglalás és kizárás használatával adja meg, hogy egy adott dokumentumban mely mezőket kívánja lekérni.
Az eredmény a képen látható:
Következtetés
Ebben a bejegyzésben megvitattuk az Elasticsearch multi-get API-val való munkavégzés alapjait, amely lehetővé teszi több dokumentum lekérését különböző forrásokból az azonosítóik alapján. További információkért bátran tekintse meg a többi dokumentumot.
Boldog kódolást!