Néha az adott adatkészlet nem egyetlen CSV-fájlban található. Mindegyik különböző Excel-táblázaton található. Már tudja, hogy több adatkészlet helyett előnyösebb az összes számítási vagy előfeldolgozási tevékenységet egyetlen adatkészleten végrehajtani. Lecsökkenti vagy megtakarítja az előfeldolgozási feladatokra fordított időt. Emellett adatelemzőként vagy adattudósként gyakran előfordulhat, hogy túlterheli magát számos CSV-fájl miatt, amelyeket össze kell egyesíteni, mielőtt elkezdené a rendelkezésre álló adatok elemzését vagy vizsgálatát. Másrészt nem mindig lehetséges, hogy az összes fájl egyetlen vagy ugyanabból az adatforrásból származik, és ugyanazokkal az oszlop-/változónevekkel és adatszerkezettel rendelkezik. Ez a bejegyzés megtanítja Önnek, hogy két vagy több CSV-fájlt kombináljon hasonló vagy eltérő oszlopszerkezettel.
Miért érdemes a CSV-fájlokat kombinálni?
Az adatkészlet lehet egy adott tárgyhoz kapcsolódó értékek vagy számok gyűjteménye vagy csoportja. Például az egyes tanulók teszteredményei egy adott osztályban egy példa az adathalmazra. A nagy adatkészletek mérete miatt ezeket gyakran külön CSV-fájlokban tárolják különböző kategóriákhoz. Például, ha egy beteget meg kell vizsgálnunk egy adott betegség miatt, akkor minden összetevőt figyelembe kell vennünk, beleértve a nemét, a kórlapját, az életkorát, a betegség súlyosságát stb. Következésképpen a CSV-adatok kombinálása szükséges a különböző prediktorokat befolyásoló tényezők vizsgálatához. szempontokat. Ezenkívül jobb egyetlen adatkészletet dolgozni és kezelni, nem pedig több adatkészletet a számítási vagy előfeldolgozási feladatok végrehajtása során. Memóriát és egyéb számítási erőforrásokat takarít meg
Hogyan lehet CSV-fájlokat kombinálni a Pythonban?
Többféle módon és módszerrel kombinálhat két vagy több CSV-fájlt a Pythonban. Az alábbi részben az append(), concat() és merge() függvényeket stb. fogjuk használni a CSV-fájlok pandas adatkeretté való kombinálásához, majd az adatkeretek egyetlen CSV-fájllá lesznek konvertálva. Megtanítjuk, hogyan lehet több CSV-fájlt kombinálni hasonló vagy változó oszlopszerkezettel.
1. módszer: CSV-k kombinálása hasonló struktúrákkal vagy oszlopokkal
Jelenlegi munkakönyvtárunkban két CSV fájl található, a „test1” és a „test2”.
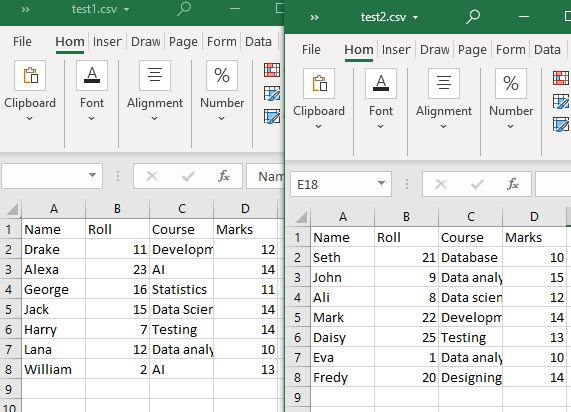
1. példa: Az append() függvény használata
Mindkét CSV-fájl szerkezete azonos. A glob() függvény ebben a módszerben csak a munkakönyvtárban lévő CSV-fájlok listázására lesz használva. Ezután a „pandas.DataFrame.append()”-t fogjuk használni a CSV-fájlok olvasásához (közös táblázatszerkezettel).

Kimenet:
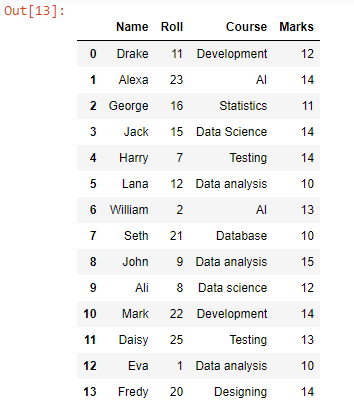
Az append függvény segítségével a test2.csv minden adatsorát hozzáfűztük vagy hozzáadtuk a test1.csv adatsoraihoz, mivel látható, hogy a fájl összes adatsora össze van vonva. Ennek az adatkeretnek a CSV-vé alakításához használhatjuk a to_csv() függvényt.

Ezzel létrehoz egy kombinált CSV-fájlt a „teszt1” és „teszt2” CSV-fájlokból a munkakönyvtárunkban a megadott névvel, azaz merged.csv.
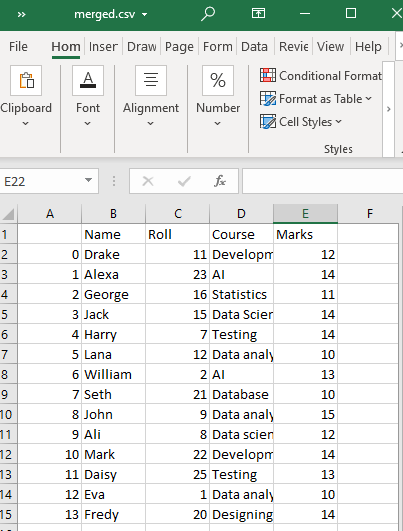
2. példa: A concat() függvény használata
Először a panda modult fogjuk importálni. A térképmódszer minden általunk továbbított CSV-fájlt beolvas a pd.read_csv() használatával. Ezeket a leképezett fájlokat (CSV-fájlokat) a rendszer alapértelmezés szerint a sortengely mentén egyesíti a pd.concat() függvény használatával. Ha vízszintesen szeretnénk egyesíteni a CSV-fájlokat, átadhatjuk az axis=1-et. A figyelmen kívül hagyási index = True megadása folyamatos indexértékeket hoz létre a kombinált adatkerethez.

A pd.read_csv() a concat() függvényen belül kerül átadásra, hogy az összefűzés után beolvassa a CSV-fájlokat a pandas adatkeretbe.
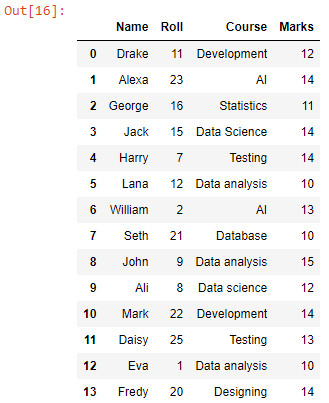
Kaptunk egy adatkeretet a munkakönyvtár összes CSV-fájljának egyesített adataival. Most alakítsuk át CSV-fájllá.
A kombinált CSV-fájlunk az aktuális könyvtárban jön létre.
2. módszer: CSV-k kombinálása különböző struktúrákkal vagy oszlopokkal
Az első módszerben tárgyaltuk az azonos oszlopokkal és szerkezettel rendelkező CSV-fájlok kombinálását. Ebben a módszerben a CSV-fájlokat különböző oszlopokkal és szerkezetekkel kombináljuk.
1. példa: Merge() függvény használata
A pandas modulban található „pandas.merge()” függvény két CSV-fájlt kombinálhat. Az összevonás egyszerűen azt jelenti, hogy két adatkészletet egyetlen adatkészletté egyesítenek megosztott oszlopok vagy attribútumok alapján.
Az adatkereteket négy különböző módon egyesíthetjük:
- Belső
- Jobb
- Bal
- Külső
Az ilyen típusú egyesítések végrehajtásához két CSV-fájlt fogunk használni.
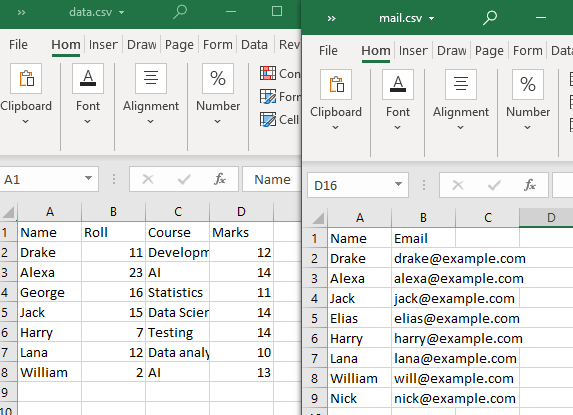
Vegye figyelembe, hogy legalább egy attribútumot vagy oszlopot mindkét CSV-fájlnak meg kell osztania. Amint azt megfigyeltük, a „Név” oszlopot és egyes attribútumait mindkét CSV-fájl megosztja.
Egyesítés belső csatlakozással
A how=’inner’ paraméter megadása a merge() függvényben a két adatkeretet a megadott oszlopnak megfelelően egyesíti, majd egy új adatkeretet biztosít, amely csak az azonos/azonos értékeket tartalmazó sorokat tartalmazza mindkét eredeti adatkeretben.
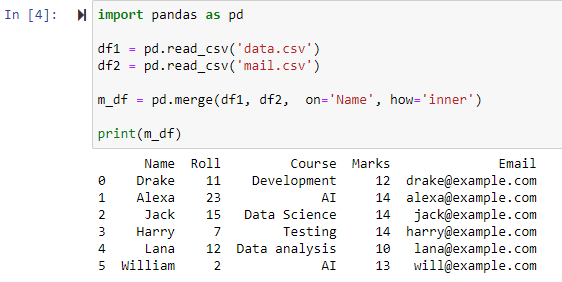
Mint látható, a függvény egyesítette mindkét CSV-fájlt, és visszaadta a sorokat a „Név” oszlop közös attribútumai alapján.
Egyesítés jobb külső csatlakozással
Ha a how=’right’ paraméter meg van adva, a két adatkeret az „on” paraméterhez megadott oszlop alapján kombinálódik. És egy új adatkeret, amely tartalmazza a jobb oldali adatkeret összes sorát, beleértve azokat a sorokat is, amelyekhez a bal oldali adatkeret nem tartalmaz értékeket, a bal oldali adatkeret oszlopértéke NAN-ra lesz állítva.
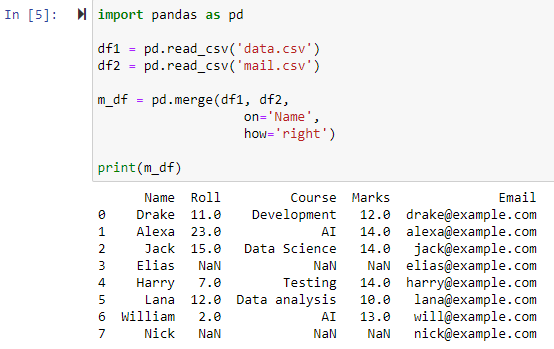
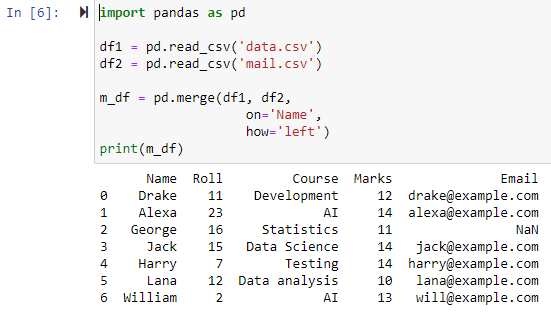
Egyesítés bal külső csatlakozással
Ha a paraméter „left”-ként van megadva, a két adatkeret a megadott oszlop alapján kombinálódik az „on” paraméter használatával, és egy új adatkeretet ad vissza, amely tartalmazza a bal oldali adatkeret összes sorát, valamint a NAN-t tartalmazó sorokat. vagy null értékeket a megfelelő adatkeretben, és a jobb oldali adatkeret oszlop értékét NAN-ra állítja.
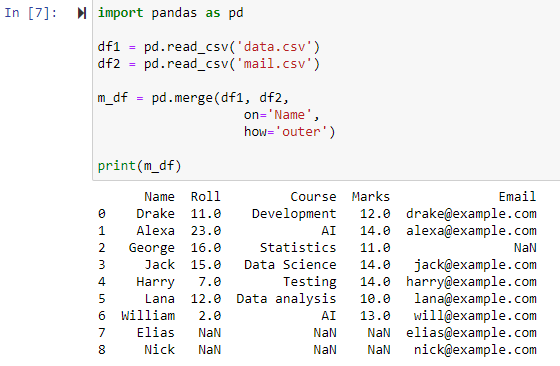
Egyesítés teljes külső csatlakozással
Ha a how='outer' meg van adva, a két adatkeret az 'on' paraméterhez megadott oszloptól függően kombinálódik, egy új adatkeretet ad vissza, amely tartalmazza a df1 és df2 adatkeret sorait is, és a NAN értéket állítja be minden sorhoz. amelyekhez az egyik adatkeretben hiányoznak az adatok.
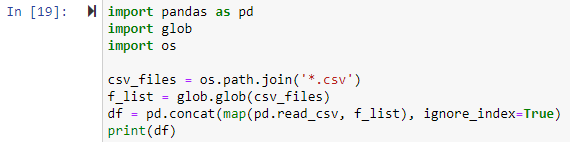
2. példa: Az összes CSV-fájl egyesítése a munkakönyvtárban
Ennél a módszernél a glob modult használjuk az összes .csv-fájl egy pandas DataFrame-be való egyesítésére. Először minden könyvtárat importálni kellett. Ezután minden egyesíteni kívánt CSV-fájlhoz beállítunk egy elérési utat. Az alábbi példában a fájl elérési útja az os.path.join() függvény első argumentuma, a második argumentum pedig vagy az összekapcsolandó elérési útvonal-összetevők vagy .csv-fájlok. Itt a „*.csv” kifejezés minden olyan fájlt megkeres és visszaad a munkakönyvtárban, amely a .csv fájlkiterjesztéssel végződik. A glob.glob(files joined) függvény bemenetként elfogadja az egyesített fájlok nevének listáját, és kiadja az összes egyesített/kombinált fájl listáját.
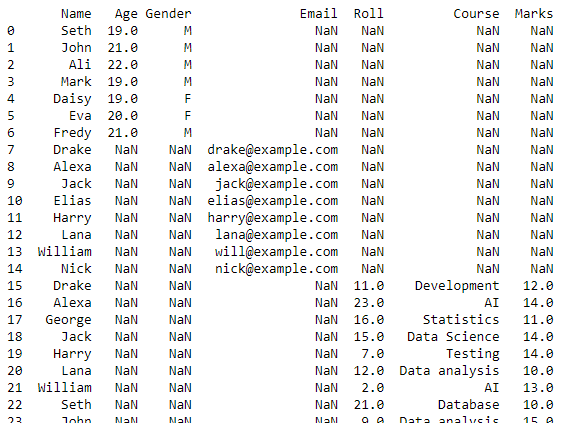
Ez a szkript egy adatkeretet ad vissza a munkakönyvtárunkban található összes CSV-fájl egyesített adataival.
Ez az adatkeret CSV-fájllá alakul, és a to_csv() függvényt használjuk ehhez az átalakításhoz. Ez az új CSV-fájl az aktuális munkakönyvtárban tárolt összes CSV-fájlból létrehozott kombinált CSV-fájlok lesznek.
Következtetés
Ebben a bejegyzésben megvitattuk, miért kell kombinálnunk a CSV-fájlokat. Megbeszéltük, hogyan lehet két vagy több CSV-fájlt kombinálni Pythonban. Ezt az oktatóanyagot két részre osztottuk. Az első részben elmagyaráztuk, hogyan használhatjuk az append() és concat() függvényeket az azonos szerkezetű vagy oszlopnevű CSV-fájlok kombinálására. A második részben a merge() metódust, az os.path.join() és a glob metódust használtuk a különböző oszlopokból és szerkezetekből álló CSV-fájlok kombinálására.