„A CSV (Comma-Separated Values) az egyik legsokoldalúbb és legkönnyebben használható adatformátum. Ez egy könnyű adatformátum, amely lehetővé teszi a fejlesztők és alkalmazások számára, hogy adatokat vigyenek át és elemezzenek egyik forrásból a másikba.
A CSV-adatok táblázatos formátumban tárolják az adatokat, ahol az egyes oszlopok vesszővel vannak elválasztva, és egy új rekordot rendelnek hozzá egy új sorhoz. Ez nagyon jó választássá teszi adatbázisok, például SQL-adatbázisok, Cassandra-adatok és egyebek exportálására.
Ezért nem meglepő, hogy olyan forgatókönyvbe fog kerülni, amikor CSV-fájlt kell importálnia az adatbázisába.
Ennek az oktatóanyagnak az a célja, hogy bemutasson egy gyors és egyszerű módszert CSV-fájl importálására az Elasticsearch-fürtbe a Kibana irányítópult segítségével.
ugorjunk be.
Követelmények
Búvárkodás előtt győződjön meg arról, hogy megfelel a következő követelményeknek:
- Egy Elasticsearch klaszter zöld egészségi állapottal.
- Kibana szerver csatlakozik az Elasticsearch-fürthöz.
- Elegendő engedélyek a fürt indexeinek kezeléséhez.
Minta CSV-fájl
Mint általában, az első követelmény a forrás CSV-fájl. Érdemes megbizonyosodni arról, hogy a CSV-fájlban lévő adatok jól vannak formázva, és nem tartalmaznak hibákat.
Szemléltetés céljából egy ingyenes adatkészletet fogunk használni, amely az Amazon Prime filmjeit és TV-műsorait tartalmazza.
Nyissa meg böngészőjét, és keresse meg az alábbi forrást:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Kövesse az eljárást az adatkészlet helyi gépére való letöltéséhez. A letöltött archívumot a következő paranccsal bonthatja ki:
$ csomagolja ki a~ / Letöltések / archívum.zip
CSV-fájl importálása
Ha elkészült a forrásfájllal, folytathatjuk és megbeszélhetjük, hogyan importálhatjuk.
Kezdje azzal, hogy lépjen a Kibana főoldali irányítópultjára, és válassza a „Fájl feltöltése” lehetőséget.
Keresse meg az importálni kívánt cél CSV-fájlt az indítóablakban.
Válassza ki a forrásfájlt, és kattintson a Feltöltés gombra.
Engedélyezze az Elasticsearch és a Kibana számára a feltöltött fájl elemzését. Ez elemzi a CSV-fájlt, és meghatározza az adatformátumot, a mezőket, az adattípusokat stb.
MEGJEGYZÉS: A fürt konfigurációjától és az adatmérettől függően ez a folyamat eltarthat egy ideig. Az időtúllépések elkerülése érdekében győződjön meg arról, hogy a fő csomópont válaszol.
A folyamat befejezése után mintát kell kapnia a fájl tartalmából és az Elastic által elemzett fájlstatisztikákból.
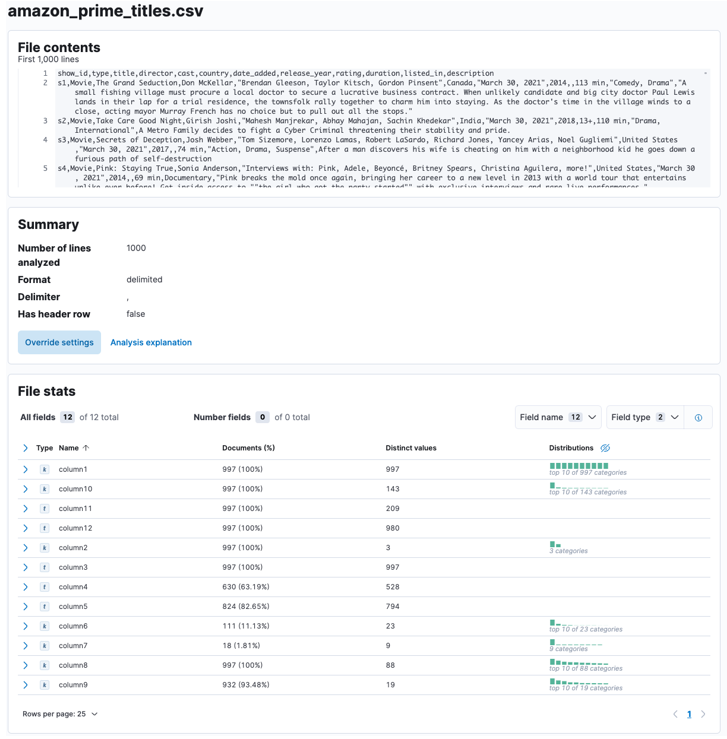
Számos paramétert személyre szabhat, például a határolót, a fejlécsorokat stb. Például testreszabhatjuk a fenti kimenetet, hogy jelezze az Elasticnak, hogy a CSV-fájlunk fejlécfájlokat tartalmaz.
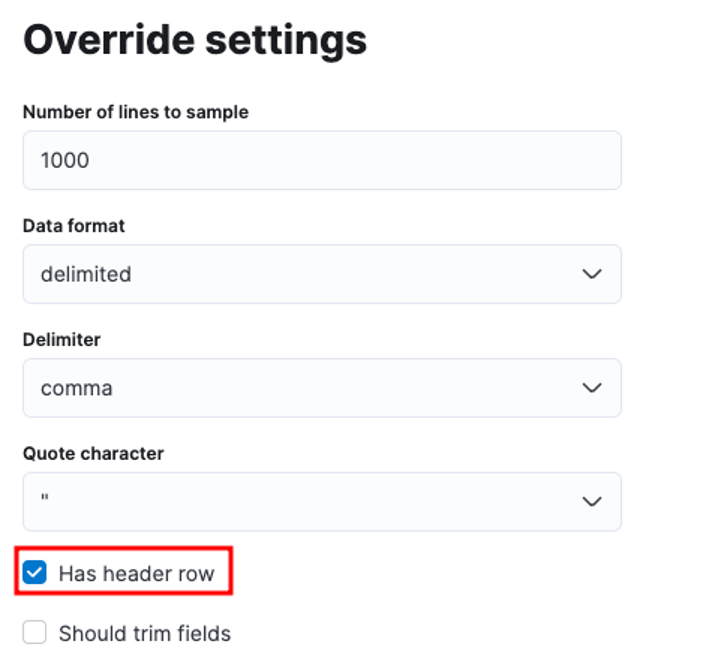
Ezután rákattinthatunk az Alkalmaz gombra, és újra elemezhetjük az adatokat. Ennek megfelelően kell formázni az adatokat, beleértve a mezőket is.
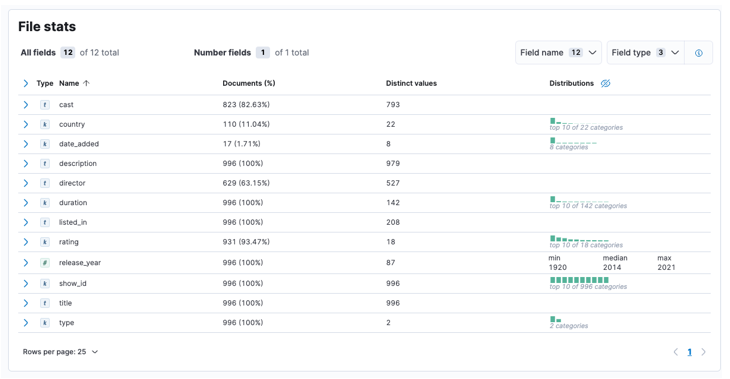
Ezután az importálás gombra kattintva továbbléphetünk az importált irányítópultra.
Itt létre kell hoznunk egy indexet, amelyben a CSV-adatokat tároljuk. Bármilyen támogatott nevet hozzárendelhet indexéhez.
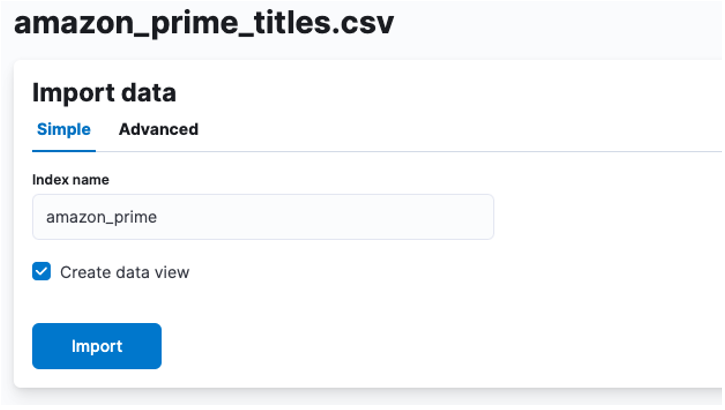
Ha testre szeretné szabni az index tulajdonságait, például a szilánkok, replikák, leképezések stb. számát. Válassza a speciális lehetőséget, és ízlése szerint módosítsa a beállításokat.
Végül kattintson az importálásra, és nézze meg, ahogy a Kibana végzi a „varázslatát”. Ha elkészült, elérheti indexét az Elasticsearch API-n keresztül vagy a Kibana irányítópultján keresztül.
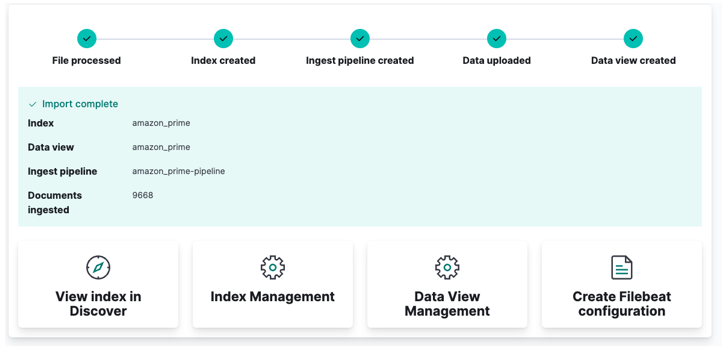
És kész!!
Következtetés
Ebben a bejegyzésben a CSV-adatkészlet lekérésének és az Elasticsearch-fürtbe történő importálásának folyamatát ismertettük a Kibana irányítópult segítségével.
Köszönöm az olvasást és jó kódolást!!