Panda Fill NaN Values
Ha az adatkeretben egy oszlop NaN vagy None értékekkel rendelkezik, akkor a „fillna()” vagy a „replace()” függvényekkel töltheti ki őket nullával (0).
tölt()
Az NA/NaN értékeket a megadott megközelítéssel tölti ki a „fillna()” függvény segítségével. A következő szintaxis figyelembevételével használható:
Ha egyetlen oszlopra szeretné kitölteni a NaN értékeket, akkor a szintaxis a következő:

Ha a teljes DataFrame-hez ki kell töltenie a NaN-értékeket, a szintaxis a következő:

Csere()
A NaN értékek egyetlen oszlopának cseréjéhez a megadott szintaxis a következő:

Míg a teljes DataFrame NaN értékeinek lecseréléséhez a következő említett szintaxist kell használnunk:

Ebben az írásban most feltárjuk és megtanuljuk mindkét módszer gyakorlati megvalósítását a Pandas DataFrame-ünkben található NaN értékek kitöltésére.
1. példa: NaN értékek kitöltése Pandas „Fillna()” módszerrel
Ez az ábra a Pandas „DataFrame.fillna()” függvény alkalmazását mutatja be az adott DataFrame-ben lévő NaN értékek 0-val való kitöltésére. A hiányzó értékeket vagy egyetlen oszlopban töltheti ki, vagy kitöltheti a teljes DataFrame-re. Itt látni fogjuk mindkét technikát.
Ezen stratégiák gyakorlatba ültetéséhez megfelelő platformot kell szereznünk a program végrehajtásához. Ezért úgy döntöttünk, hogy a „Spyder” eszközt használjuk. A Python-kódunkat úgy indítottuk el, hogy importáltuk a „pandas” eszközkészletet a programba, mert a Pandas funkciót kell használnunk a DataFrame létrehozásához, valamint a hiányzó értékek kitöltéséhez a DataFrame-ben. A „pd” a „pandák” álneve az egész programban.
Mostantól hozzáférhetünk a Panda funkciókhoz. Először a „pd.DataFrame()” függvényét használjuk a DataFrame létrehozásához. Meghívtuk ezt a módszert, és három oszloppal inicializáltuk. Ezen oszlopok címei: „M1”, „M2” és „M3”. Az „M1” oszlopban szereplő értékek: „1”, „Nincs”, „5”, „9” és „3”. Az „M2” bejegyzések a következők: „Nincs”, „3”, „8”, „4” és „6”. Míg az „M3” az adatokat „1”, „2”, „3”, „5” és „Nincs” formában tárolja. Szükségünk van egy DataFrame objektumra, amelyben tárolhatjuk ezt a DataFrame-et a „pd.DataFrame()” metódus meghívásakor. Létrehoztunk egy „hiányzó” DataFrame objektumot, és hozzárendeltük a „pd.DataFrame()” függvényből kapott eredmény alapján. Ezután a Python „print()” metódusát alkalmaztuk a DataFrame megjelenítésére a Python konzolon.
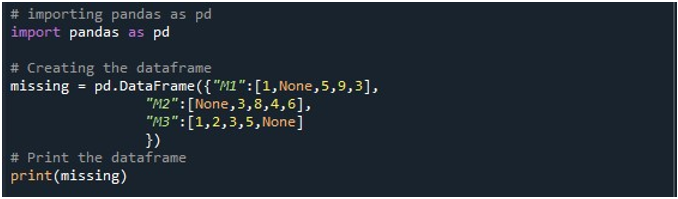
Amikor ezt a kódrészletet futtatjuk, egy három oszlopos DataFrame látható a terminálon. Itt megfigyelhetjük, hogy mind a három oszlop tartalmazza a null értékeket.
Létrehoztunk egy DataFrame-et néhány null értékkel, hogy a Pandas 'fillna()' függvényét alkalmazzuk a hiányzó értékek 0-val való kitöltéséhez. Tanuljuk meg, hogyan tehetjük ezt meg.
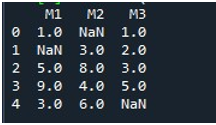
A DataFrame megjelenítése után meghívtuk a Pandas „fillna()” függvényét. Itt megtanuljuk a hiányzó értékeket egyetlen oszlopban kitölteni. Ennek szintaxisát már az oktatóanyag elején említettük. Megadtuk a DataFrame nevét, és megadtuk az adott oszlop címét a „.fillna()” függvénnyel. Ennek a módszernek a zárójelei között megadtuk azt az értéket, amely a nulla helyekre kerül. A DataFrame neve „hiányzik”, az itt kiválasztott oszlop pedig „M2”. A „fillna()” kapcsos zárójelei között megadott érték „0”. Végül a „print()” függvényt hívtuk meg a frissített DataFrame megtekintéséhez.

Itt látható, hogy a DataFrame „M2” oszlopa most nem tartalmaz hiányzó értékeket, mert a NaN érték 0-val van kitöltve.
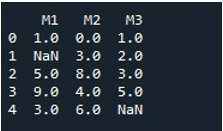
A teljes DataFrame NaN-értékeinek ugyanazzal a módszerrel való kitöltéséhez a „fillna()”-nak neveztük el. Ez nagyon egyszerű. A DataFrame nevet a „fillna()” függvénnyel adtuk meg, a zárójelek közé pedig a „0” függvényértéket rendeltük. Végül a “print()” függvény megmutatta nekünk a kitöltött DataFrame-et.

Ezzel egy DataFrame-et kapunk, amelyben nincsenek NaN-értékek, mivel az összes érték 0-val van feltöltve.
2. példa: Töltse ki a NaN értékeket a Pandas „Replace()” módszerrel
A cikk ezen része egy másik módszert mutat be a NaN értékek DataFrame-ben való kitöltésére. A Pandas „replace()” funkcióját fogjuk használni, hogy az értékeket egyetlen oszlopban és egy teljes DataFrame-ben töltsük ki.
Elkezdjük írni a kódot a „Spyder” eszközben. Először importáltuk a szükséges könyvtárakat. Itt betöltöttük a Pandas könyvtárat, hogy lehetővé tegyük a Python program számára a Pandas metódusok használatát. A második betöltött könyvtár a NumPy, és álneve „np”. A NumPy a hiányzó adatokat a „replace()” metódussal kezeli.
Ezután létrehoztunk egy DataFrame-et, amely három oszlopból áll – „csavar”, „szeg” és „fúró”. Az egyes oszlopokban az értékek megfelelően vannak megadva. A „csavar” oszlop „112”, „234”, „Nincs” és „650” értékeket tartalmaz. A „szög” oszlopban a „123”, „145”, „Nincs” és „711” szerepel. Végül a „drill” oszlop „312”, „Nincs”, „500” és „Nincs” értékeket tartalmaz. A DataFrame a „tool” DataFrame objektumban tárolódik, és a „print()” metódussal jelenik meg.
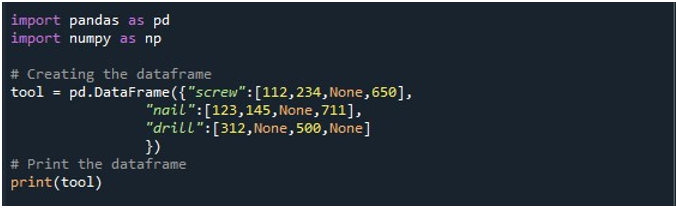
A DataFrame négy NaN értékkel a rekordban látható a következő kimeneti képen:
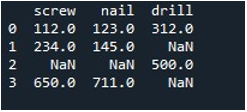
Most a Pandas „replace()” metódusát használjuk a null értékek kitöltésére a DataFrame egyetlen oszlopában. A feladathoz a „replace()” függvényt hívtuk meg. A DataFrame nevet a „tool” és a „screw” oszlopot a „.replace()” metódussal láttuk el. Kapcsos zárójelei között a DataFrame „np.nan” bejegyzéseinek „0” értékét állítjuk be. A „print()” metódus a kimenet megjelenítésére szolgál.

Az eredményül kapott DataFrame az első oszlopot mutatja, amelyben a NaN bejegyzések 0-ra vannak cserélve a „csavar” oszlopban.
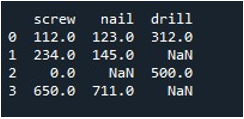
Most megtanuljuk kitölteni az értékeket a teljes DataFrame-ben. Meghívtuk a „replace()” metódust a DataFrame nevével, és megadtuk azt az értéket, amelyet np.nan bejegyzésekkel szeretnénk lecserélni. Végül kinyomtattuk a frissített DataFrame-et a “print()” függvénnyel.

Ezzel megkapjuk az eredményül kapott DataFrame-et hiányzó rekordok nélkül.
Következtetés
A DataFrame hiányzó bejegyzéseinek kezelése alapvető és szükséges követelmény a bonyolultság csökkentése és az adatok kihívó kezelése érdekében az adatelemzési folyamatban. A Pandas néhány lehetőséget kínál a probléma megoldására. Ebben az útmutatóban két praktikus stratégiát mutattunk be. Mindkét technikát a gyakorlatba ültetjük a „Spyder” eszköz segítségével a mintakódok végrehajtására, hogy egy kicsit érthetővé és könnyebbé tegyük a dolgokat az Ön számára. E funkciók ismeretének elsajátítása fejleszti a Pandák képességeit.