Pandas Set_Option Method
Ma megnézzük, hogyan használhatjuk a „pd.set_option()” függvényt a Pandas Dataframe összes oszlopának megjelenítéséhez, amikor bemutatjuk azt a Spyder eszközben. A „pd.set_option()” használatához a megadott szintaxist követjük:

Kezdjük a koncepció tanulását a Python program gyakorlati megvalósításának segítségével.
Példa: A Pandas Set_Option metódus használata az összes oszlop megjelenítéséhez
Ez a bemutató egy útmutató a DataFrame összes oszlopának megjelenítéséhez a Pandas „set_option()” használatával. Világossá tesszük a Python-módszer megvalósításának minden lépésének részleteit.
A Python-szkript gyakorlati megvalósításának első feltétele, hogy megtaláljuk a legjobb eszközt, ahol a programunkat végrehajtjuk. Az illusztrációhoz használt eszköz a „Spyder” eszköz. Elindítottuk az eszközt, és elkezdtünk dolgozni a Python szkripten.
A kóddal kezdve először importálnunk kell a programban szükséges előfeltétel-könyvtárakat. Az első könyvtár, amelyet a Python-fájlunkba betöltöttünk, a Pandas könyvtár, mivel az itt használt funkciókat a Pandas biztosítja. Ezt a könyvtárat „pd”-nek neveztük el. A második betöltött könyvtár a NumPy könyvtár. A NumPy (Numerical Python) egy numerikus számítástechnikai csomag, amelyet Python programozással fejlesztettek ki. A kód NumPy importálása szakasza arra utasítja a Pythont, hogy integrálja a NumPy modult az aktuális Python-fájlba. A szkript „as np” része ezután utasítja a Pythont, hogy rendelje hozzá a NumPy-hez az „np” rövidítést. Lehetővé teszi a NumPy metódusok használatát az „np.function_name” megadásával a NumPy helyett.
Most kezdjük a fő kóddal. A programunk legfontosabb és alapvető szükséglete a Pandas DataFrame. Tehát megjelenítjük a benne található összes oszlopot. Most már teljesen Önön múlik, hogy szeretne-e létrehozni egy DataFrame-et meghatározott értékekkel, vagy importálnia kell egy CSV-fájlt. Ehhez a példányhoz egy DataFrame létrehozását választottuk NaN értékekkel. Meghívtuk a „pd.DataFrame()” metódust egy DataFrame létrehozásához. Itt két paramétert adtunk meg - „index” és „oszlopok”. Az „index” argumentum a sorokra vonatkozik, ami azt jelenti, hogy beállítjuk a sorokat a DataFrame számára.
Az „index” paramétert és az „np.arange()” NumPy függvényt „6” értékkel rendeltük hozzá. Hat sort generál a DataFrame számára. Az összes bejegyzést NaN értékekkel tölti fel, mivel nem adtunk meg értéket. Az „oszlopok” argumentum, ahogy a név is meghatározza, a DataFrame oszlopainak beállítására szolgál. Ezenkívül hozzá van rendelve az „np.arange()” függvény is, amely „25” értékkel rendelkezik az oszlopokhoz. Így 25 oszlopot hoz létre a DataFrame számára.
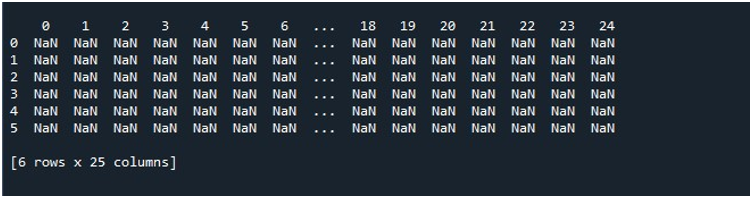
Következésképpen, amikor meghívjuk a „pd.DataFrame()” függvényt, akkor egy DataFrame-et kapunk, amely 25 oszlopot és 6 sort tartalmaz null értékekkel. A DataFrame megőrzéséhez létre kell hoznunk egy DataFrame objektumot, amely tárolja a tartalmát. Ezért létrehoztunk egy „random” DataFrame objektumot, és hozzárendeltük a „pd.DataFrame()” metódus eredményeként kapott eredményt. Most biztosan látni szeretné a DataFrame generálását. A Python egy módszert biztosít számunkra a kimenet képernyőn történő megtekintésére, ez a „print()” függvény. Ezt a metódust úgy hívtuk meg, hogy a DataFrame objektum „random” paraméterét adtuk át.
Amikor ezt a kódrészletet végrehajtjuk, megkapjuk a DataFrame-ünket NaN értékekkel a terminálon. Itt megfigyelhetjük, hogy az első oszlopok egy része, a végéről pedig csak néhány látható. Az összes köztes oszlop csonkolva van. Alapértelmezés szerint elrejti a sorok és oszlopok egy részét, hogy elkerülje a felhasználó frusztrációját a hatalmas adatkészletek megjelenítésével.
Még a DataFrame összes oszlopának számát is ellenőrizheti a Pandas „len()” funkciójával. Írja be a „len()” függvényt a „Spyder” eszköz konzoljára. Írja be a DataFrame nevét a zárójelek közé a „.columns” tulajdonsággal. Visszaadja a DataFrame oszlopainak teljes hosszát.

A DataFrame hosszát adja vissza, ami 25.
Most a következő és alapvető feladat az alapértelmezett beállítás megváltoztatása a kimenet megjelenítéséhez. Előfordulhat, hogy a teljes DataFrame-et meg szeretné tekinteni a terminálon. Az alapértelmezett értékek miatt sok bejegyzés csonkolódik, ami csalódást okoz a felhasználónak. Itt megtudhatja, hogyan lehet legyőzni ezt a problémát. A Pandas egy „pd.set_option()” függvényt biztosít számunkra az alapértelmezett megjelenítési beállítások megváltoztatásához. Közvetlenül a DataFrame konzolon való megjelenítése után meghívjuk a „pd.set_option()” metódust. Ennek a függvénynek a zárójelében adjuk meg azt a paramétert, amelyet a DataFrame összes oszlopának megjelenítéséhez használnunk kell.
Itt a „display.max_columns”-t használtuk a DataFrame-ünk maximális oszlopainak megjelenítésére. Megadhatjuk ennek a paraméternek az értékét is, azaz a megjeleníteni kívánt maximális oszlopok számát. Mi viszont a „display.max_columns” értéket „Nincs” értékre állítottuk, ami a DataFrame összes oszlopát maximális hosszúsággal jeleníti meg. Végül a „print()” függvényt alkalmaztuk az eredményül kapott DataFrame megjelenítésére, a terminálon látható összes oszloppal.
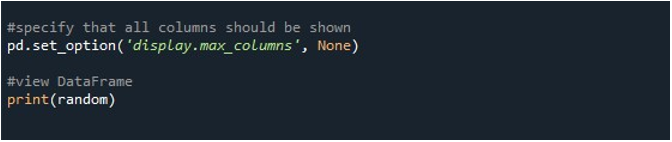
Amikor megnyomjuk a „Fájl futtatása” opciót a „Spyder” eszközön, megtekinthetjük a kiállított DataFrame-et. Ez a DataFrame hat sorból áll, és a benne lévő oszlopok száma 25. Nincsenek csonkolt oszlopok, mivel a maximális oszlophosszúságú „pd.set_option()” funkció most engedélyezett.
Még a megjelenítési beállítást is visszaállíthatjuk, mert ha a megjelenítési hosszt maximálisra állítottuk, továbbra is megjeleníti a DataFrames-eket az adott Python-fájl összes oszlopával. Ehhez a Pandas „pd.reset_option()”-ot használjuk. Meghívjuk ezt a függvényt, és a „display.max_columns” paramétert adjuk meg ennek a függvénynek.

Ezzel megkapjuk a megadott DataFrame kezdeti megjelenítési beállításait.
Következtetés
A teljes kimenet megtekintése a terminálon egy hatalmas adatkészlettel néha bajba kerül, amikor az eszköz alapértelmezett beállításai ellentétben állnak a felhasználó igényeivel. A probléma megoldására a Pandas a „pd.set_option()” metódust adja meg. Ebben a tanulási útmutatóban bemutattuk Önnek ezt a módszert és annak szükségességét. A témát a gyakorlatilag lefordított és végrehajtott Python mintakódokkal mutattuk be. A „Spyder”-en végzett illusztráció eredményeit rendereltük. Elmagyaráztuk, hogyan jelenítheti meg a DataFrame összes oszlopát a konzolon az alapértelmezett beállítások módosításával, valamint az összes beállítás kezdeti értékre való visszaállításával. Ha teljes figyelmet fordít a modul gyakorlati megvalósítására, akkor bármikor használhatja azt, amikor ilyen problémába ütközik.