1. példa: Szerezze meg a minta pozícióját a karakterláncból az R Grep() függvényével
A megadott minta pozíciójának kivonásához a karakterláncból az R grep() függvényét használjuk.
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=TRUE, value=FALSE)Itt a grep() függvényt használjuk, ahol a „+i” minta argumentumként van megadva, amelyet a karakterláncok vektorán belül kell egyeztetni. Beállítjuk a négy karakterláncot tartalmazó karaktervektorokat. Ezután a „perl” argumentumot TRUE értékkel állítjuk be, ami azt jelzi, hogy az R perl-kompatibilis reguláris kifejezés-könyvtárat használ, a „value” paramétert pedig „FALSE” értékkel adjuk meg, amely az elemek indexeinek lekérésére szolgál. a mintának megfelelő vektorban.
A „+i” minta pozíciója minden egyes vektorkarakter-sorozatból a következő kimenetben jelenik meg:

2. példa: Párosítsa a mintát az R Gregexpr() függvényével
Ezután a gregexpr() függvény segítségével lekérjük az index pozícióját az adott karakterlánc hosszával együtt az R-ben.
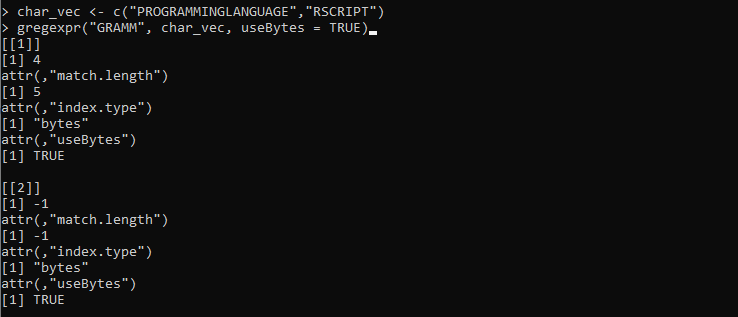
char_vec <- c('PROGRAMOZÁSI NYELV','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = IGAZ)
Itt beállítjuk a „char_vect” változót, ahol a karakterláncok különböző karakterekkel vannak ellátva. Ezt követően definiáljuk a gregexpr() függvényt, amely a „GRAMM” karakterlánc-mintát veszi, hogy illeszkedjen a „char_vec”-ben tárolt karakterláncokhoz. Ezután a useBytes paramétert a „TRUE” értékkel állítjuk be. Ez a paraméter azt jelzi, hogy az illesztést bájtonként kell elérni, nem pedig karakterenként.
A következő kimenet, amely a gregexpr() függvényből származik, mindkét vektor karakterlánc indexét és hosszát reprezentálja:
3. példa: Számolja meg az összes karaktert a stringben az Nchar() függvény segítségével
Az nchar() metódus, amelyet a következőkben implementálunk, azt is lehetővé teszi, hogy meghatározzuk, hány karakter van a karakterláncban:
Res <- nchar('Minden karakter megszámolása')nyomtatás (felbontás)
Itt az nchar() metódust hívjuk, amely a „Res” változóban van beállítva. Az nchar() metódus egy hosszú karaktersorozattal van ellátva, amelyet az nchar() metódus számol, és megadja a számlálókarakterek számát a megadott karakterláncban. Ezután átadjuk a „Res” változót a print() metódusnak, hogy megnézzük az nchar() metódus eredményeit.
Az eredmény a következő kimenetben érkezik, amely azt mutatja, hogy a megadott karakterlánc 20 karakterből áll:

4. példa: Kivonja a részstringet a karakterláncból az R Substring() függvényével
A substring() metódust használjuk a „start” és „stop” argumentumokkal, hogy kivonjuk a karakterláncból az adott részkarakterláncot.
str <- substring('REGGEL', 2, 4)print (str)
Itt van egy „str” változónk, ahol a substring() metódus hívódik meg. A substring() metódus a „MORNING” karakterláncot veszi első argumentumként, és a „2” értékét második argumentumként, ami azt jelzi, hogy a karakterlánc második karakterét kell kivonni, a „4” argumentum értéke pedig azt jelzi, hogy a negyedik karaktert kell kinyerni. A substring() metódus kivonja a karaktereket a karakterláncból a megadott pozíciók között.
A következő kimenet megjeleníti a kivont részkarakterláncot, amely a karakterlánc második és negyedik pozíciója között helyezkedik el:

5. példa: A karakterlánc összefűzése a Paste() függvény segítségével R-ben
A paste() függvényt az R-ben a karakterlánc-manipulációra is használják, amely összefűzi a megadott karakterláncokat a határolók elválasztásával.
msg1 <- 'Tartalom'msg2 <- 'Írás'
beillesztés (üzenet1, üzenet2)
Itt adjuk meg az „msg1” és „msg2” változókhoz tartozó karakterláncokat. Ezután az R paste() metódusát használjuk, hogy a megadott karakterláncot egyetlen karakterláncba fűzzük össze. A paste() metódus a strings változót veszi argumentumként, és az egyetlen karakterláncot adja vissza, a karakterláncok között az alapértelmezett szóközzel.
A paste() metódus végrehajtásakor a kimenet az egyetlen karakterláncot reprezentálja a benne lévő szóközzel.

6. példa: Módosítsa a karakterláncot a Substring() függvény segítségével az R-ben
Továbbá frissíthetjük a karakterláncot úgy is, hogy hozzáadjuk az alkarakterláncot vagy bármilyen karaktert a string() függvény segítségével a következő szkript segítségével:
str1 <- 'Hősök'alstring(str1, 5, 6) <- 'ic'
cat(' Módosított karakterlánc:', str1)
A „Heroes” karakterláncot az „str1” változón belül állítjuk be. Ezután telepítjük a substring() metódust, ahol az „str1” meg van adva az alkarakterlánc „start” és „stop” indexértékeivel együtt. A substring() metódus hozzá van rendelve az „iz” részkarakterlánchoz, amely az adott karakterlánc függvényében megadott pozícióba kerül. Ezt követően az R cat() függvényét használjuk, amely a frissített karakterlánc értékét reprezentálja.
A karakterláncot megjelenítő kimenet az alstring () metódussal frissül az újjal:

7. példa: Formázza meg a karakterláncot az R Format() függvényével
Az R karakterlánc-kezelési művelete azonban magában foglalja a karakterlánc megfelelő formázását is. Ehhez a format() függvényt használjuk, ahol a karakterláncot igazíthatjuk, és beállíthatjuk az adott karakterlánc szélességét.
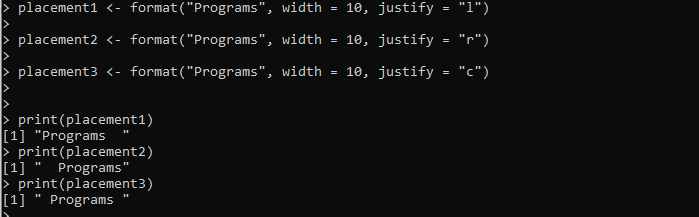
elhelyezés1 <- formátum('Programok', szélesség = 10, sorkizárás = 'l')elhelyezés2 <- formátum('Programok', szélesség = 10, justify = 'r')
placement3 <- format('Programok', szélesség = 10, justify = 'c')
nyomtatás (elhelyezés1)
nyomtatás (elhelyezés2)
nyomtatás (elhelyezés3)
Itt beállítjuk a „placement1” változót, amelyet a format() metódus biztosít. A formázandó „programs” karakterláncot átadjuk a format() metódusnak. A szélesség be van állítva, és a karakterlánc igazítása balra van állítva az „justify” argumentum segítségével. Hasonlóképpen létrehozunk még két változót, a „placement2” és a „placement2”, és a format() metódust alkalmazzuk a megadott karakterlánc megfelelő formázásához.
A kimenet három formázási stílust jelenít meg ugyanahhoz a karakterlánchoz a következő képen, beleértve a balra, jobbra és középre igazítást:
8. példa: A karakterlánc átalakítása kis- és nagybetűkre az R-ben
Ezenkívül a karakterláncot kis- és nagybetűsre is átalakíthatjuk a tolower() és toupper() függvények segítségével az alábbiak szerint:
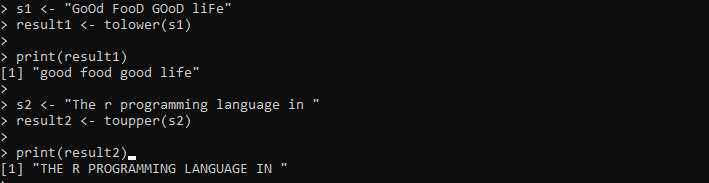
s1 <- 'JÓ ÉTEL JÓ ÉLET'Eredmény1 <- tolower(s1)
nyomtatás (eredmény1)
s2 <- 'Az r programozási nyelv a '
2. eredmény <- toupper(s2)
nyomtatás (eredmény2)
Itt megadjuk a nagy- és kisbetűket tartalmazó karakterláncot. Ezt követően a karakterlánc az „s1” változóban marad. Ezután meghívjuk a tolower() metódust, és átadjuk benne az „s1” karakterláncot, hogy a karakterláncon belüli összes karaktert kisbetűsre alakítsuk. Ezután kinyomtatjuk a tolower() metódus eredményeit, amelyet az „eredmény1” változóban tárolunk. Ezután beállítunk egy másik karakterláncot az „s2” változóban, amely az összes karaktert kisbetűvel tartalmazza. Erre az „s2” karakterláncra a toupper() metódust alkalmazzuk, hogy a meglévő karakterláncot nagybetűssé alakítsuk.
A kimenet mindkét karakterláncot megjeleníti a megadott esetben a következő képen:
Következtetés
Megtanultuk a karakterláncok kezelésének és elemzésének különféle módjait, amelyeket karakterlánc-manipulációnak neveznek. Kivontuk a karakter pozícióját a karakterláncból, összefűztük a különböző karakterláncokat, és a karakterláncot a megadott kis- és nagybetűvé alakítottuk. Ezenkívül formáztuk a karakterláncot, módosítottuk a karakterláncot, és számos egyéb műveletet hajtunk végre itt a karakterlánc manipulálására.