A SED, más néven adatfolyamszerkesztő, nagyon hasznos eszköz. Egy adott szó vagy minta megkeresésére szolgál, majd ezt követően valamit csinál a szóval vagy mintával, vagy más szóval átalakítja azt. A Windows rendszerben a SED „keresés” és „csere” funkcióként is ismert. A SED az Ubuntuval érkezik, így nem kell semmit telepíteni; csak kezdje el használni. Ebben az oktatóanyagban bemutatjuk, hogyan kell használni a SED-et vagy a streamszerkesztőt.
Az 'S' parancs
A SED vagy az adatfolyamszerkesztő parancsai közül a legfontosabb az „s” parancs. Az „s” a helyettesítőt jelenti. A szintaxis a következő:
‘s / regexp / csere / zászlókat
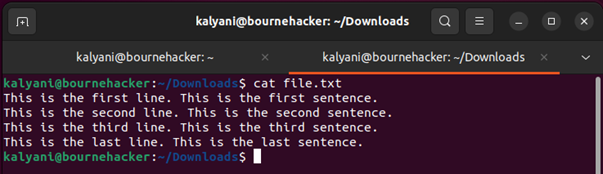
Tehát használjunk egy „file.txt” nevű fájlt a példákhoz. Így néz ki a „file.txt”, ha felveszed:
Használjunk egy példát az „s” parancs működésének bemutatására:
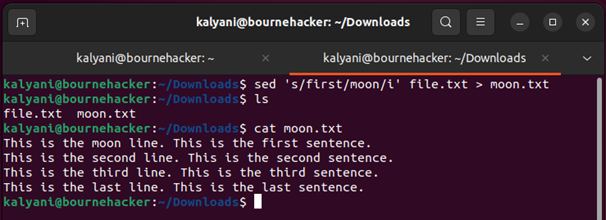
de ‘s / első / hold / i' file.txt > hold.txt
Ha ilyen kifejezést adunk, az azt jelenti:
-
- s – A helyettesítőt jelenti.
- először – A „file.txt” nevű fájlban keresendő szó.
- hold – Az „első” szót a „hold” szó váltja fel.
- i – A figyelmen kívül hagyást jelenti. Ezt a részt először figyelmen kívül hagyjuk.
- file.txt – A fájl, amelyben a SED keresni fogja a mintát vagy a szót. Ebben az esetben az „első” szó a következő lesz:
- moon.txt – Ha az „első” szót a „hold” szó váltja fel, a rendszer a „moon.txt” mappába menti.
fájl.txt fájlban keresett
Szóval, mi történik itt? A SED a „first” szót csak az első esetben helyettesíti a „hold” szóval (ez azt jelenti, hogy ha a „first” szó többször előfordul, akkor nem helyettesíti az egészet, vagy nem cseréli le többször). A keresett fájl neve „file.txt”, és amint az átalakítás vagy a csere megtörtént, a „moon.txt” alatt kerül mentésre.
Így néz ki:
Kérjük, ne felejtse el oda tenni a „/” jelet, ahol lennie kell. Ha kihagyja a „/” jelet, a SED nem fogadja el a parancsot.
Eddig csak az „első” szót cseréltük fel a „találkoztam” szóra. Most tegyük fel, hogy a „sor” szót (amely sokszor – pontosabban négyszer) szeretnénk lecserélni a harmadik sorban az „angyal” szóra.
Hogyan célozzuk meg konkrétan ezt a harmadik sort? A következő parancsot használjuk:
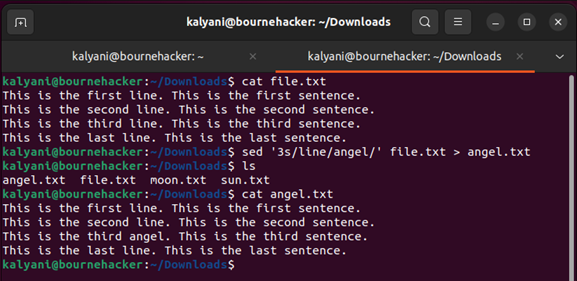
de '3s / vonal / angyal / i' file.txt > angyal.txt
Szóval, mi történt itt? Nos, a „3” a sor számát határozza meg. Ezért a harmadik sorba megy. Ezután cserélje ki a „sor” szót az „angel” szóra a „file.txt” nevű fájlban, és mentse el az átalakított fájlt „angel.txt” néven.
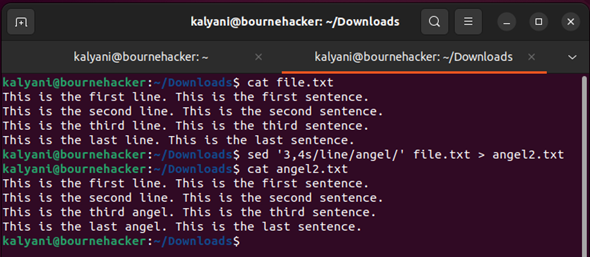
Mi van, ha le akarjuk cserélni vagy átalakítani a „3” és „4” sort?
Vegye figyelembe, hogy az előző példában az „i” jelzőt használtuk a figyelmen kívül hagyáshoz. Most a „g” jelzőt használjuk a globálisra.
Használjunk egy példát az „s” parancs működésének bemutatására:
de ‘s / vonal / nap / g’ fájl.txt > sun.txt
Ha ilyen kifejezést adunk, az azt jelenti:
A „g” a globálist jelenti. Ne feledje, hogy az első példában, amikor az „i” jelzőt használjuk, csak egyetlen csere van. Most, hogy hozzáadtunk egy „g”-t a globális helyhez, ez mindenhol helyettesítést jelent. Tehát ahelyett, hogy azt mondaná az első sor, a második sor, a harmadik sor és az utolsó sor, azt mondja, hogy első nap, második nap, harmadik nap és utolsó nap. A sor szót a teljes fájlban (mindenhol) a „sun” szóra cseréli.
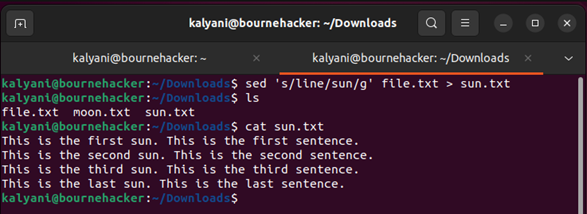
Mi van akkor, ha egyetlen sort akarunk kijelölni a benne lévő szó alapján? Nos, láthatjuk, hogy a „file.txt” utolsó sorában a „last” szó szerepel. Tegyük fel, hogy a „Ez az utolsó sor. Ez az utolsó mondat.' mondat lesz „Ez az utolsó szellem. Ez az utolsó mondat.'
A következőket írjuk:
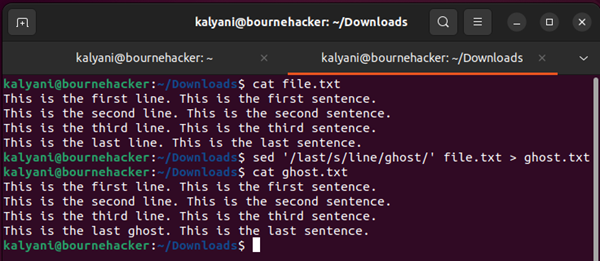
de ' / utolsó / s / vonal / szellem / ' fájl.txt > ghost.txt
Az „utolsó” itt azt utasítja a SED-re, hogy keresse meg azt a sort, amelyben az „utolsó” szó szerepel, majd cserélje ki a „sor” szót „szellem”-re a sorban.
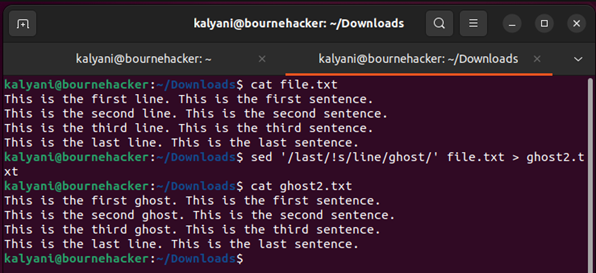
Most tegyük fel, hogy az ellenkezőjét akarjuk csinálni. Tegyük fel, hogy azt akarjuk, hogy minden „utolsó” szó nélküli sorban a „sor” szó „szellem”-re változzon. Írjuk a következőket:
Amint itt látható, minden sorban, kivéve az utolsót (amely az „utolsó” szót tartalmazza), a „sor” szó helyére a „szellem” szó lép.
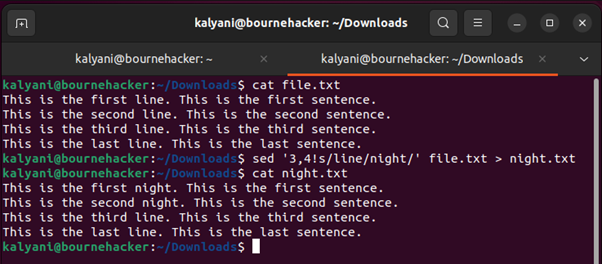
Ezt sorszámokkal is megtehetjük:
Ebben az esetben a 3. és 4. sor kimarad, de minden második sorban a „sor” szó helyébe az „éjszaka” szó lép.
Több parancs
Nos, mi van, ha több parancsod lenne? Inkább egyenként csinálnád, vagy egyszerre, és időt és munkát spórolnál magadnak?
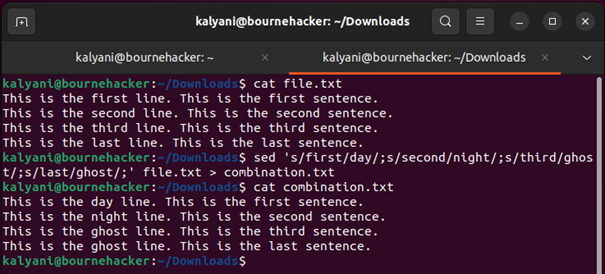
Mi van akkor, ha az „első” szót „nappal”, a „második” szót „éjszaka”-ra, a „többi” szót pedig „szellemre” akarjuk változtatni? Ehhez a pontosvesszőt használjuk. Ne felejtsd el a pontosvesszőt a végére tenni!
Kérjük, vegye figyelembe, hogy nem feltétlenül kell az „i” jelzőt vagy a „figyelmen kívül hagyni” jelzőt, hanem feltétlenül a perjelet (/) az átalakítási kifejezés után.
Most nézzük meg egy példával:
de ‘s / első / nap / ; s / második / éjszaka / ; s / harmadik / szellem / ; s / utolsó / szellem / ;' fájl.txt > kombináció.txt
Következtetés
A folyamszerkesztő vagy a SED egy szó vagy minta kiválasztásának és átalakításának módja. Valójában ez a parancssori megfelelője az ablak „keresés” és „csere” funkcióinak. A SED parancs nagyon bonyolult lehet, de ha legalább ismeri az alapokat, készen áll a betartására! A SED valójában egy nagyon hatékony eszköz, számos funkcióval. Bár nem tudjuk mindegyiket lefedni egy oktatóanyagban, bemutattuk a SED alapjait. Lényegében megtanultuk, hogyan alakíthatunk át egy adott szót az „s” paranccsal, ahol az „s” a helyettesítést jelenti. A szavakat behelyettesíthetjük más szavakkal, szelektíven kiválaszthatunk egy sort, ahol a helyettesítés megtörténik, vagy akár tagadhatjuk is. Akárhogy is, ez a legegyszerűbb része a SED-nek.
Boldog kódolást!