Adatbázis-adminisztrátorként megszállottnak kell lennünk az adatbázis teljesítményének javítására szolgáló eszközök és módszerek iránt.
A PostgreSQL-ben hozzáférhetünk az EXPLAIN ANALYZE parancshoz, amely lehetővé teszi egy adott adatbázis-lekérdezés végrehajtási tervének és teljesítményének elemzését. A parancs részletes információt ad vissza arról, hogy az adatbázismotor hogyan dolgozza fel a lekérdezést. Ez magában foglalja a végrehajtott műveletek sorrendjét, a becsült lekérdezési költségeket, a végrehajtás időzítését és még sok mást.
Ezt az információt ezután felhasználhatjuk az adatbázis-lekérdezések azonosítására, valamint a lehetséges teljesítmény szűk keresztmetszetek azonosítására és kijavítására.
Ez az oktatóanyag azt tárgyalja, hogyan használható az EXPLAIN ANALYZE parancs a PostgreSQL-ben a lekérdezés teljesítményének megtekintéséhez és optimalizálásához.
PostgreSQL EXPLAIN ANALYZE
A parancs elég egyértelmű. Először is hozzá kell fűznünk az EXPLAIN ANALYZE parancsot az elemezni kívánt lekérdezés elejére.
A parancs szintaxisa a következő:
EXPLAIN ANALYZEA parancs végrehajtása után a PostgreSQL részletes kimenetet ad vissza a megadott lekérdezésről.
Az EXPLAIN ANALYZE lekérdezés kimenet megértése
Mint már említettük, az EXPLAIN ANALYZE parancs futtatása után a PostgreSQL részletes jelentést készít a lekérdezési tervről és a végrehajtási statisztikákról.
A kimenet hasznos információkat tartalmazó oszlopokból áll. Az eredményül kapott oszlopok a képen láthatók, a megfelelő jelentésükkel:
KÉRDEZÉSI TERV – Ez az oszlop a megadott lekérdezés végrehajtási tervét jeleníti meg. A végrehajtási terv olyan műveletsorozatra vonatkozik, amelyet az adatbázis-motor hajt végre a lekérdezés sikeres befejezése érdekében.
TERV – A második oszlop a TERV oszlop. Ez tartalmazza a végrehajtási terv minden egyes műveletének vagy lépésének szöveges megjelenítését. Ismét minden művelet behúzással jelzi a műveletek hierarchiáját.
ÖSSZKÖLTSÉGE – A teljes költség oszlop a lekérdezés becsült összköltségét mutatja. A költség egy relatív mértékre vonatkozik, amelyet az adatbázis-lekérdezéstervező az optimális végrehajtási terv meghatározásához használ.
AKTUÁLIS SOROK – Ez az oszlop a lekérdezés végrehajtásának egyes lépéseiben feldolgozott sorok pontos számát mutatja.
TÉNYLEGES IDŐ – Ez az oszlop az egyes műveletek tényleges idejét mutatja, amely magában foglalja a művelet végrehajtási idejét és az erőforrásokra fordított időt is.
TERVEZÉSI IDŐ – Ez az oszlop azt az időt mutatja, amely alatt a lekérdezéstervező elkészíti a végrehajtási tervet. Ez magában foglalja a lekérdezés optimalizálásának és a terv generálásának teljes idejét.
VÉGREHAJTÁSI IDŐ – Ez az oszlop a lekérdezés végrehajtásának teljes idejét mutatja. Ez magában foglalja a tervezésre és a lekérdezések végrehajtására fordított időt is.
PostgreSQL EXPLAIN ANALYZE Példa
Nézzünk néhány alapvető példát az EXPLAIN ANALYZE utasítás használatára.
1. példa: Válassza a Nyilatkozat lehetőséget
Használjuk az EXPLAIN ANALYZE utasítást egy egyszerű select utasítás végrehajtásának bemutatására a PostgreSQL-ben.
Az előző utasítás futtatása után a következő kimenetet kell kapnunk:
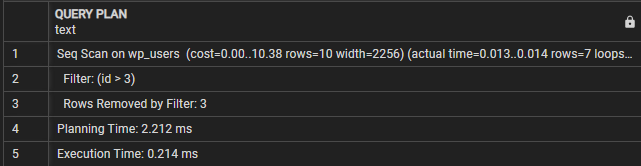
KÉRDEZÉSI TERV-------------------------------------------------- ------------------
Seq Scan on wp_users (költség=0,00..10,38 sor=10 szélesség=2256) (tényleges idő=0,009...0,010 sor=7 hurok=1)
Szűrő: (azonosító > 3)
A szűrő által eltávolított sorok: 3
Tervezési idő: 0,995 ms
Végrehajtási idő: 0,021 ms
(5 sor)
Ebben az esetben láthatjuk, hogy a Lekérdezési terv szakasz azt jelzi, hogy a lekérdezés szekvenciális vizsgálatot hajt végre a wp_users táblán. A szűrővonal azt a feltételt jelöli, amely a kapott sorok szűrésére szolgál.
Ezután megjelenik a „Szűrő által eltávolított sorok”, amely megmutatja a szűrőfeltétel által eltávolított sorok számát.
Végül a végrehajtási idő a lekérdezés teljes végrehajtási idejét mutatja. Ebben az esetben a lekérdezés 0,021 ms-t vesz igénybe.
2. példa: Csatlakozás elemzése
Vegyünk egy összetettebb lekérdezést, amely SQL csatlakozást tartalmaz. Ehhez a Pagila mintaadatbázist használjuk. Demonstrációs célból letöltheti és telepítheti a mintaadatbázist a gépére.
Futtathatunk egy egyszerű csatlakozást az alábbiak szerint:
magyarázat elemzés SELECT f.titt, c.namefilmből f
JOIN film_category fc ON f.film_id = fc.film_id
CSATLAKOZÁS a c kategóriára ON fc.kategória_azonosítója = c.kategória_azonosítója;
Miután futtattuk az adott lekérdezést, a kimenetet a következőképpen kell látnunk:
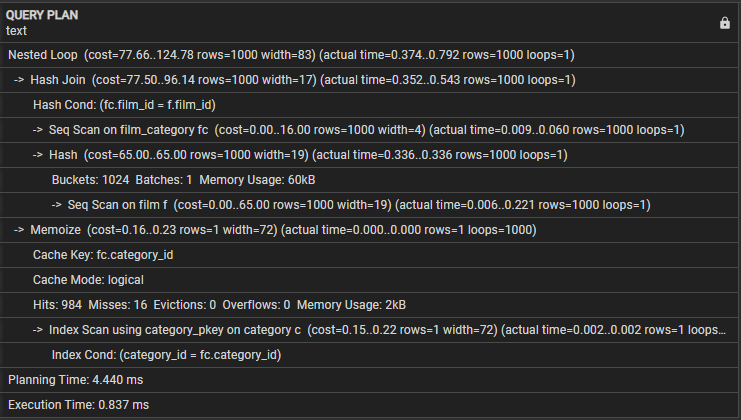
Vizsgáljuk meg a következő lekérdezési tervet:
- Beágyazott hurok – Ez azt jelzi, hogy az összekapcsolás beágyazott hurok összekapcsolási stratégiát használ.
- Hash Join – Ez a művelet összekapcsolja a film_category-t és a filmtáblázatokat egy hash-illesztési algoritmus segítségével. Ennek a műveletnek a költsége 77,50, és a becslések szerint 1000 sor. Ennek a műveletnek a tényleges ideje azonban 0,254–0,439 ezredmásodperc, és 1000 sort kér le.
- Hash Cond – Ez azt jelzi, hogy az összekapcsolási feltétel hash összekapcsolást használ a filmtáblázat film_id és film_category oszlopainak egyeztetésére.
- Seq Scan on film_category – Ez a művelet szekvenciális beolvasást hajt végre a film_category táblán 16,00 költséggel és 1000 sorral. A művelet tényleges ideje 0,008 és 0,056 milliszekundum között van, és 1000 sort kér le.
- Sorozatos szkennelés filmre – A lekérdezés szekvenciális beolvasást hajt végre a filmtáblán a művelet eredményeként kapott becsült és tényleges költségekkel és sorokkal.
- Memoize – Ez a művelet gyorsítótárazza a film_category és a filmtáblázatok összekapcsolásának eredményeit későbbi felhasználás céljából.
- Gyorsítótár kulcs – Ez azt jelzi, hogy a memorizáláshoz használt gyorsítótár kulcs a film_category kategória_id oszlopán alapul.
- Gyorsítótár mód – Ez azt jelzi, hogy a lekérdezés a logikai gyorsítótár módot használja.
- Találatok, kihagyások, kilakoltatások, túlcsordulások – A három sor statisztikai adatokat közöl a gyorsítótárról, a találatok számáról, a kihagyásokról, a kilakoltatásokról és a végrehajtás során bekövetkezett túlcsordulásokról. Ez a blokk tartalmazza a memóriahasználatot is a lekérdezés végrehajtása során.
- Indexvizsgálat a category_pkey használatával – Ez a művelet azt a műveletet mutatja, amely az elsődleges kulcsindex használatával indexvizsgálatot hajt végre a kategóriatáblázaton.
- Indexfeltétel – Ez azt mutatja, hogy az indexvizsgálat azon a feltételen alapul, amely megfelel a kategóriatáblázat kategóriaazonosítója oszlopának.
- Tervezési idő – Ez a sor a lekérdezés tervezéséhez szükséges időt mutatja, ami 3,005 ezredmásodperc.
- Végrehajtási idő – Végül ez a sor a lekérdezés teljes végrehajtási idejét mutatja, ami 0,745 ezredmásodperc.
Tessék, itt van! Részletes információ egy egyszerű csatlakozás végrehajtásáról a PostgreSQL-ben.
Következtetés
Felfedezte az EXPLAIN ANALYZE utasítás erejét és használatát a PostgreSQL-ben. Az EXPLAIN ANALYZE utasítás hatékony eszköz a lekérdezések elemzéséhez és optimalizálásához. Ezzel az eszközzel hatékony és kevésbé erőforrás-igényes lekérdezéseket hozhat létre.