A pandák az adatkutatók által manapság a táblázatos adatok elemzésére használt legnépszerűbb eszközök közé tartoznak. A táblázatos tartalom kezeléséhez gyorsabb és hatékonyabb API-t kínál. Amikor az elemzés során adatkereteket nézünk, a Pandas automatikusan alapértelmezett értékekre állítja be a különféle megjelenítési viselkedéseket. Ezek a megjelenítési viselkedések magukban foglalják a megjelenítendő sorok és oszlopok számát, a lebegtetések pontosságát az egyes adatkeretekben, az oszlopok méretét stb. A követelményektől függően előfordulhat, hogy időnként módosítanunk kell ezeket az alapértelmezett értékeket. A pandák számos megközelítést kínálnak az alapértelmezett viselkedés megváltoztatására. A pandák „opciók” attribútumának kihasználása lehetővé tette számunkra, hogy megváltoztassuk ezt a viselkedést.
A Pandák maximális sorokat jelenítenek meg
Amikor olyan hatalmas adatkeretet próbál meg nyomtatni, amely az előre meghatározott küszöbértéknél több sort és oszlopot tartalmaz, a kimenet levágásra kerül. A DataFrame összes sorának megjelenítéséhez ebben az oktatóanyagban megtudhatja, hogyan módosíthatja a Pandák megjelenítési beállításait. A pandák alapértelmezés szerint korlátozzák a megjelenített oszlopok és sorok számát. Bár ez hasznos lehet a tartalom olvasásához, gyakran frusztrációt okoz, ha a megtekinteni kívánt információ nem jelenik meg. Itt az alábbiakban megadott módszereket fogjuk használni a szintaxisukkal az adatkeret összes oszlopának megjelenítéséhez.
to_string()

set_option()

option_context()

Megtanuljuk mindezen módszerek felhasználását gyakorlati megvalósítással a maximális sorok megjelenítésére a megadott adatkeretben.
1. példa: A Pandas to_string() metódus használata
Ez a bemutató megtanít minket arra, hogy a terminálon a maximális sorokat jelenítsük meg egy adatkeretben a pandas „to_string()” metódussal.
A mintaprogramok összeállításához és végrehajtásához a „Spyder” eszközt választottuk. Ebben az útmutatóban ezt az eszközt fogjuk használni az összes példánk végrehajtásához. Elindítottuk a „Spyder” eszközt a python szkript írásának megkezdéséhez. A kóddal kezdve először be kell töltenünk a szükséges könyvtárakat a python fájlunkba, hogy használhatjuk a funkcióit. Az itt szükséges modulkönyvtár a „Pandas”. Tehát importáltuk a python fájlunkba, és „pd”-re álneveztük.
Mivel a cikk fő művelete egy adatkeret maximális sorainak megjelenítése, először szükségünk van egy adatkeretre. Most már Önön múlik, hogy adatkeretet szeretne-e létrehozni, vagy CSV-fájlt importálni. Importáltunk egy minta CSV-fájlt. A CSV-fájl python programba való beolvasásához a pandas „pd.read_csv()” függvényt használtuk. Ennek a függvénynek a zárójelei között megadtuk azt a CSV-fájlt, amelyet be szeretnénk olvasni a kijelzőn, ez az „industry.csv”. Létrehoztunk egy „df” változót a mellékelt CSV-fájl olvasásából származó kimenet tárolására. Ezután a „print()” metódust hívtuk meg az adatkeret megjelenítéséhez.
Amikor ezt a python programot a „Fájl futtatása” opció megnyomásával futtatjuk, egy adatkeret jelenik meg a konzolon. Megfigyelheti, hogy az alábbi eredményben 43 sor van, de csak tíz jelenik meg. Ennek az az oka, hogy a Pandas könyvtár alapértelmezett értéke csak 10 sor.
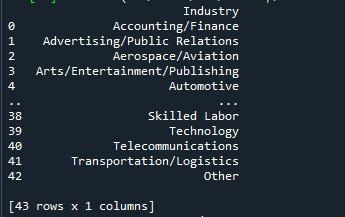
A „to_string” pandas metódust fogjuk használni az összes sor megjelenítéséhez. Ezzel a technikával a legegyszerűbb módja annak, hogy egy adatkeretből a maximális sorokat jelenítsük meg. Mivel azonban a teljes adatkeretet egyetlen karakterláncba alakítja, nem ajánlott nagyon nagy adathalmazokhoz (milliókban). Mindazonáltal ez hatékonyan működik olyan adatkészleteknél, amelyek több ezer hosszúságúak.
A fenti szintaxist követtük a „to_string()” függvényhez. Egyszerűen meghívtuk a „to_string()” metódust az adatkeretünk nevével. Ezután ezt a metódust a „print()” függvénybe helyeztük, hogy meghívásra megjelenjen.

A kimeneti pillanatkép egy adatkeretet mutat, amelyben az összes sor megjelenik a terminálon.
2. példa: A Pandas set_option metódus használata
A második módszer, amelyet ebben az útmutatóban fogunk gyakorolni, a panda „set_option()” a megadott adatkeret maximális sorainak megjelenítésére.
A python fájlba importáltuk a pandas könyvtárat, hogy elérjük a fent említett funkciót. A „pd.read_csv()” pandákat használtuk a mellékelt CSV-fájl olvasásához. Meghívtuk a „pd.read_CSV()” függvényt a használni kívánt CSV fájl nevével a zárójelben, ami „Sampledata.csv”. A CSV-fájl importálásakor tartsa szem előtt a Python program aktuális munkakönyvtárát. A CSV-fájlt ugyanabban a könyvtárban kell elhelyezni; ellenkező esetben a „fájl nem található” hibaüzenetet kap. Létrehoztunk egy „sample” változót a CSV fájl adatkeretének tárolására. Meghívtuk a „print()” metódust, hogy megjelenítsük ezt az adatkeretet.
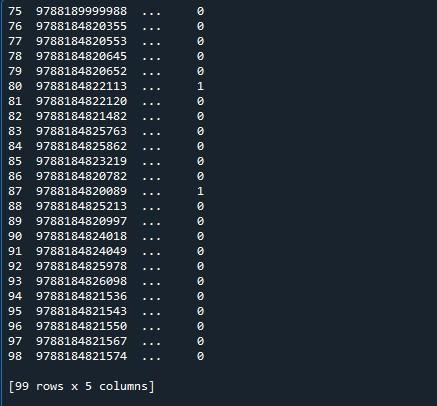
Itt van a kimenetünk, ahol csak tíz sor jelenik meg. A feltüntetett sorok maximális száma 99. Az első 5 és az utolsó öt sor közötti összes többi sor csonkolva van.

Az ehhez az adatkerethez tartozó maximális sorok 99 megjelenítéséhez a pandas modul „set_option()” függvényét használjuk. A Pandák olyan operációs rendszerrel rendelkeznek, amely lehetővé teszi a viselkedés és a megjelenítés megváltoztatását. Ez a módszer lehetővé teszi, hogy a kijelzőt úgy állítsuk be, hogy egy teljes adatkeretet mutasson a csonka helyett. A pandák a „set_ option()” függvényt biztosítják az adatkeret összes sorának megjelenítéséhez.
Meghívtuk a „pd.set_option()”-t. Ennek a függvénynek a „display.max_rows” paraméterei vannak. A „display.max_rows” az adatkeret megjelenítésekor megjelenített sorok maximális számát adja meg. A „max_sorok” értéke alapértelmezés szerint 10. Ha a „Nincs” lehetőséget választja, az az adatkeret összes sorát jelöli. Mivel az összes sort meg akarjuk jeleníteni, ezért „Nincs”-ra állítottuk. Végül a „print()” függvényt használtuk az adatkeret megjelenítésére maximum sorokkal.

Ez az alábbi pillanatképen látható eredményt adja.
3. példa: A Pandas option_context() metódus használata
Az itt tárgyalt utolsó módszer az „option_context()” az adatkeret összes sorának megjelenítéséhez. Ehhez importáltuk a pandas csomagot a python fájlba, és elkezdtük írni a kódot. A „pd.read_csv()” függvényt használtuk az általunk megadott CSV-fájl olvasásához. Létrehoztunk egy „dalta” változót az adatkeret tárolására a megadott CSV fájlból. Ezután egyszerűen kinyomtattuk az adatkeretet a „print()” metódussal.
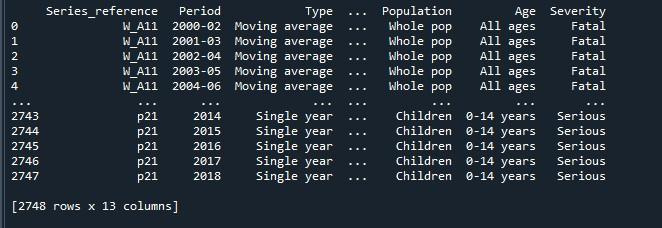
A fenti kód végrehajtásával kapott eredmény egy csonka sorokat tartalmazó adatkeretet mutat.
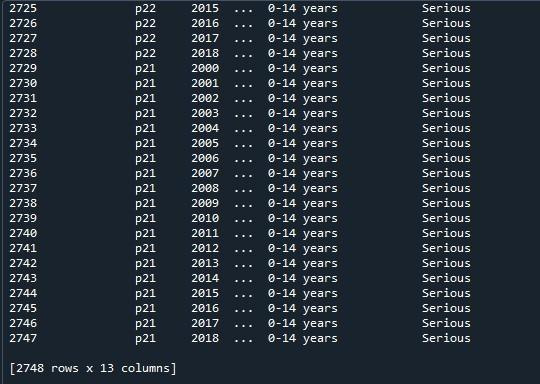
Most alkalmazzuk a pandák „pd.option_context()”-ét ezen az adatkereten. Ez a függvény megegyezik a „set_option()”-val. Az egyetlen különbség a két megközelítés között az, hogy a „set_option()” véglegesen megváltoztatja a beállításokat, míg az „option _context()” csak a hatókörén belül változtatta meg azokat. Ez a metódus a display.max rows paramétert is veszi, amit a „Nincs” értékre állítunk az adatkeret összes sorának megjelenítéséhez. A függvény meghívása után csak megjelenítettük a „print()” metóduson keresztül.

Itt megtekinthetjük a teljes adatkeretet a maximális sorokkal, amelyek 2747.
Következtetés
Ez a cikk a pandák megjelenítési lehetőségeire összpontosít. Előfordulhat, hogy néha meg kell néznünk a teljes adatkeretet a terminálon. A pandák számos lehetőséget kínálnak erre a célra. Ebben az útmutatóban ezek közül a stratégiák közül hármat használtunk. Az első példa a „to_string()” metóduson alapult. Második példányunk a „set_option()” megvalósítását tanítja meg, míg az utolsó illusztráció az „option_context()” metódust hajtja végre. Mindezeket a technikákat bemutattuk, hogy megismertesse Önt a pandák által kínált alternatív módokkal a kívánt eredmény elérése érdekében.