„Ez a cikk bemutatja, hogyan lehet összesíteni vagy bizonyos oszlopokat egy Pandas DataFrame-ben Python használatával. Az oktatóanyag számos példájában a DataFrame.sum() függvényt néhány hasznos paraméterrel együtt fogjuk használni.
Ha ez az oktatóanyag véget ért, tudni fogja, hogyan kell:
-
- Keresse meg a Pandas adatkeret oszlopának összegét.
- Az adatkeret oszlopainak összeadása
- Adjon hozzá olyan oszlopokat egy Pandas adatkerethez, amely megfelel a megadott feltételnek.
- Határozza meg az összeget az adatkeret adatainak csoportosítása után!
Hogyan határozható meg az adatkeret oszlopok összege?
A Pandas „dataframe.sum()” függvénye a megadott tengely teljes összegét adja vissza. Ha a bemenet az index tengelye, a függvény minden oszlop értékeit külön-külön hozzáadja, majd minden oszlopnál ugyanezt teszi, visszaadva egy sorozatot, amely az egyes oszlopokban lévő adatok/értékek összegét tárolja. Ezenkívül támogatja az adatkeret összegének kiszámítását a hiányzó értékek figyelmen kívül hagyásával.
Szintaxis: DataFrame.sum(tengely = Nincs, skipna = Nincs, szint = Nincs, numeric_only = Nincs, min_count = 0, **kwargs)
Ahol,
tengely: {oszlopok (1), index (0)}
rendelés: Az eredmény kiszámításakor hagyja figyelmen kívül az NA/null értékeket.
szint: Ha a megadott tengely hierarchikus (többindex), számoljon egy adott indexszintre, mielőtt sorozattá konvertálná.
numeric_only: Csak float, int és logikai oszlopok elfogadhatók. Ha nincs, próbáljon meg mindent használni; ha nem, akkor csak számszerű adatokat. Sorozathoz, nincs implementálva.
min_count: A művelet befejezéséhez szükséges lehetséges értékek száma. Az eredmény NA lesz, ha kevesebb nem NA érték van jelen, mint a min_count.
Visszaküldések: DataFrame (ha szint van megadva) vagy Series.
01. példa: Határozza meg egy adatkeret oszlop és az összes oszlop összegét
Először egy adatkeretre van szükségünk az érvényes adattípusokkal, azaz int, float stb. oszloppal vagy oszlopokkal, amelyekre vonatkozóan megtaláljuk az adatok összegét. Az adatkeret a pd.DataFrame() függvény használatával jön létre.
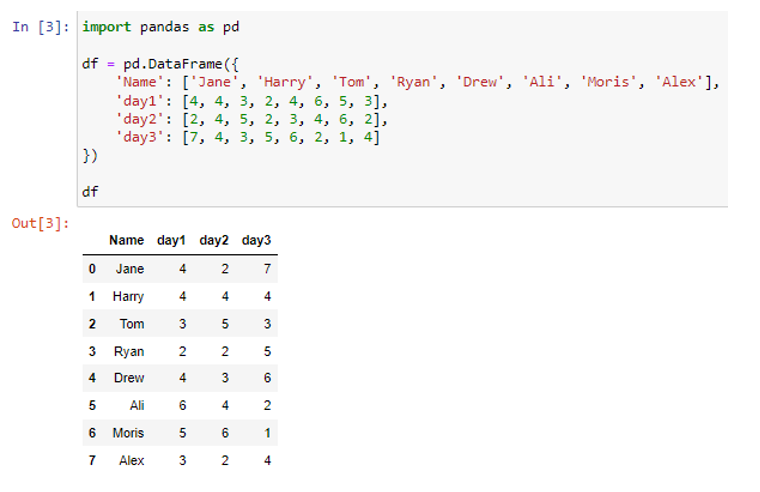
A pd.DataFrame() függvényen belül egy python szótárból hoztuk létre a szükséges adatkeretet. A fent létrehozott adatkeretben négy oszlop található: „Név”, „nap1”, „nap2” és „nap3”. A négy oszlopból a három oszlop, azaz a „nap1”, „nap2” és „nap3” numerikus oszlopok az adatértékekkel (4, 4, 3, 2, 4, 6, 5, 3), (2, 4, 5, 2, 3, 4, 6, 2), illetve (7, 4, 3, 5, 6, 2, 1, 4). Csak ennek a három oszlopnak az összegét találjuk meg. Mind a sorozat (azaz egy oszlop), mind a teljes adatkeret összege meghatározható a sum() módszerrel. Kezdjük azzal, hogy megtanítjuk, hogyan kell összegezni az összes adatot egy Panda oszlopban.
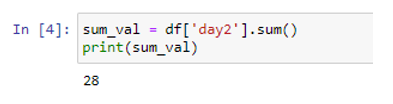
Az összeg meghatározásához a sum() metódust használtuk a „day2” oszlopban. A függvény 28-as összegértéket adott vissza. Ehhez hasonlóan meghatározhatjuk az egyes Dataframe oszlopok összegét. Egyszerűen a sum() metódus használatával a teljes adatkereten keresztül ez elérhető.
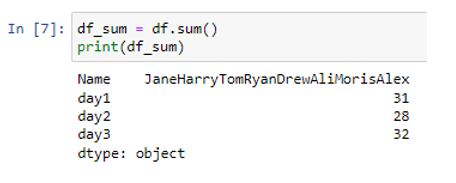
Mint látható, a „nap1” oszlop összege 31; a „day2” összeg értéke 28, míg a „day3” oszlopban az összeg értéke 32.
02. példa: A sum() függvény használata az adatkeret oszlopértékeinek összegzésére
Amint az az előző példa kimenetéből látható, a függvény nem adta vissza az összeget alkotó tényleges adatkeret oszlopadatokat. Ha azonban a „DataFrame.sum()” metódust egy DataFrame oszlophoz rendeli, elérheti a DataFrame minden oszlopát, beleértve az összeg oszlopot is. Először is létrehozunk egy másik adatkeretet ehhez a példához.
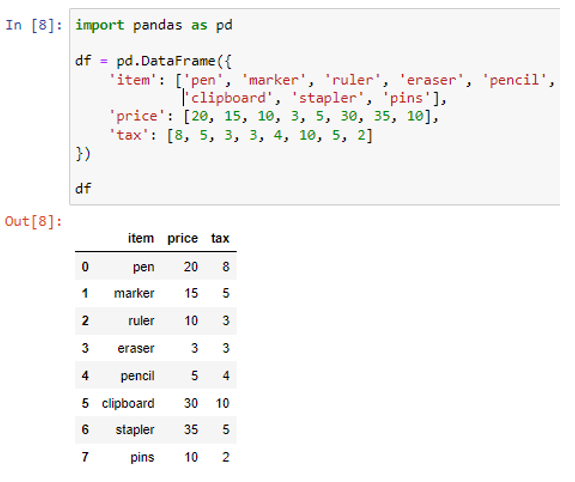
A pd.DataFrame() segítségével létrejött az adatkeretünk. Az adatkeretet három oszlopból hoztuk létre: cikk, ár és adó. A karakterlánc-értékeket tartalmazó oszloptétel („toll”, „jelölő”, „vonalzó”, „radír”, „ceruza”, „vágólap”, „tűző”, „csapok”), az értékeket tároló oszlop ára (20, 15, 10, 3, 5, 30, 35, 10), az „adó” oszlop pedig értékekből (8, 5, 3, 3, 4, 10, 5, 2) áll. Most adjuk össze az ár és az adó oszlop értékeit, és tároljuk az eredményeket egy új oszlopban úgy, hogy megtartjuk az eredeti adatkeret oszlopokat.
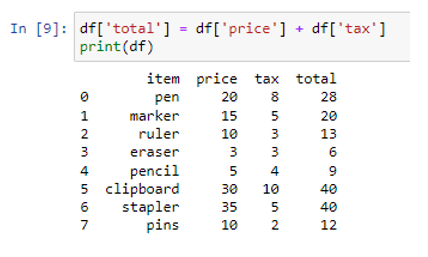
Amint az az új „összesen” oszloppal együtt észrevehető, az adott adatkeret eredeti oszlopait is visszaadja a függvény. Az „összesen” oszlop az „ár” és „adó” oszlopok értékeinek összegét tárolja az egyes „cikk” adatokkal szemben.
03. példa: A sum() függvény használata a megadott adatkeret oszlopok összegének meghatározására
Az adatkeret több oszlopának összegzéséhez megadhatunk egy listát az oszlopok címkéivel, majd a listán a sum() metódussal kereshetjük meg az összeget. Az előző példákhoz hasonlóan először létrehozzuk az adatkeretet.
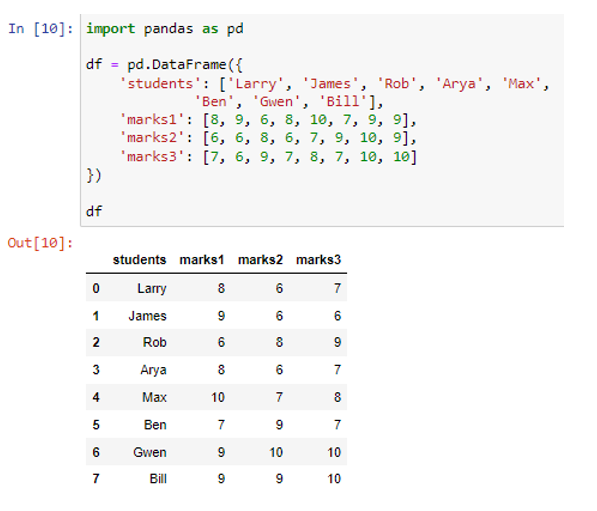
Adatkeretünket négy oszlopból, „tanulók”, „pontok1”, „jegyek2” és „jegyek3” hoztuk létre. A „diákok” oszlop tárolja az adatokat („Larry”, „James”, „Rob”, „Arya”, „Max”, „Ben”, „Gwen”, „Bill”), a „marks1” oszlop pedig a értékek (8, 9, 6, 8, 10, 7, 9, 9), míg a „marks2” és „marks3” oszlopok a számértékeket tárolják (6, 6, 8, 6, 7, 9, 10, 9). ), illetve (7, 6, 9, 7, 8, 7, 10, 10).
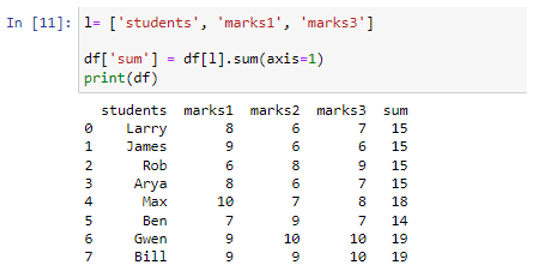
Először is létrehoztunk egy listaobjektumot „diákok”, „jelek1” és „jelek3” oszlopcímkékkel. Ezután a sum() metódus kerül alkalmazásra a listára. A függvény csak azért összegezte a marks1 és marks3 oszlopok értékeit, mert a „tanulók” oszlop nem numerikus, így a sum() függvény nem találja meg a „hallgatók” oszlop értékeinek összegét. A „marks1” és „marks3” oszlopok értékeinek összegét az „összeg” oszlopban tároltuk.
04. példa: Adjon hozzá olyan Pandas adatkeret oszlopokat, amelyek megfelelnek egy meghatározott feltételnek
Ebben a példában a megadott oszlopok értékeit adjuk hozzá, ha megfelelnek a megadott feltételnek.
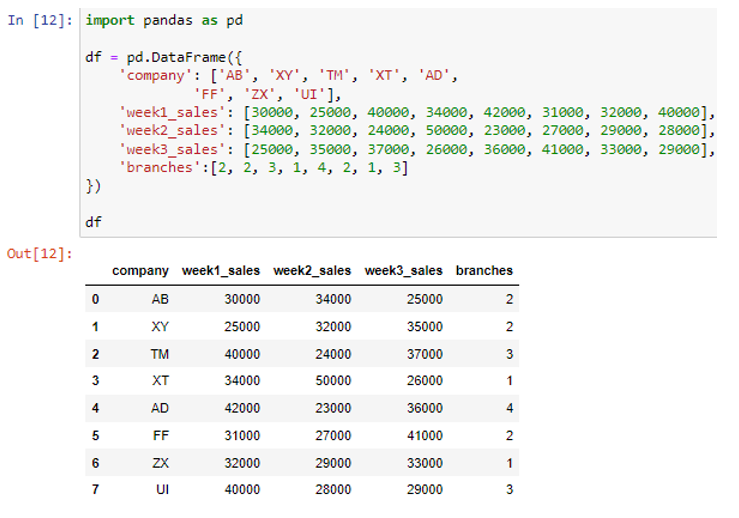
Az újonnan létrehozott adatkeretben 5 oszlop található, azaz „cég”, „week1_sales”, „week2_sales”, „week3_sales” és „branches”. Most tegyük fel, hogy nem akarjuk hozzáadni az utolsó oszlop értékét, amikor az adott adatkeret sorok értékeinek összegét adjuk össze vagy keressük meg. Tegyük fel, hogy csak a „hét” szót tartalmazó oszlopértékeket akartuk hozzáadni a címkéikhez. Létrehozható egy listaértelmezés annak meghatározására, hogy a „hét” szó szerepel-e egy oszlopcímkében vagy sem.

Most letöltöttük azokat az oszlopokat, amelyek címkéiben a „hét” szó szerepel. A „hét” szót tartalmazó oszlopokat a sum() függvény axis=1 argumentumával összegezhetjük.
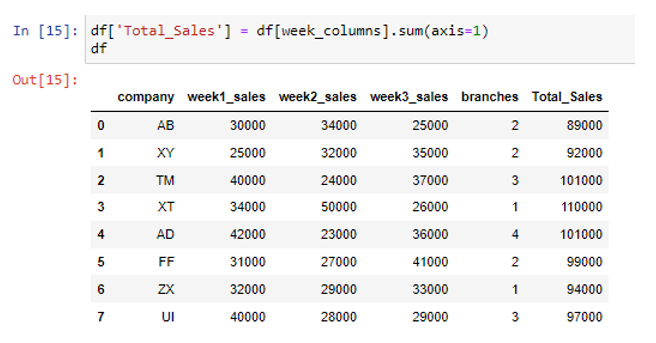
Ily módon biztonságosan összegezhetjük az adatokat az oszlopok között soronként, anélkül, hogy olyan oszlopokat vennénk fel, amelyeket nem szeretnénk.
5. példa: Határozza meg az összeget az adatkeret adatainak csoportosítása után
Az adatkeret oszlopok összegét is megtaláljuk egy vagy több oszlop adatainak csoportosítása után. A groupby() metódus az adatok oszlopon belüli kategóriákba csoportosítására szolgál. Hozzunk létre egy adatkeretet, hogy csoportosíthassuk az egyik oszlopának adatait.
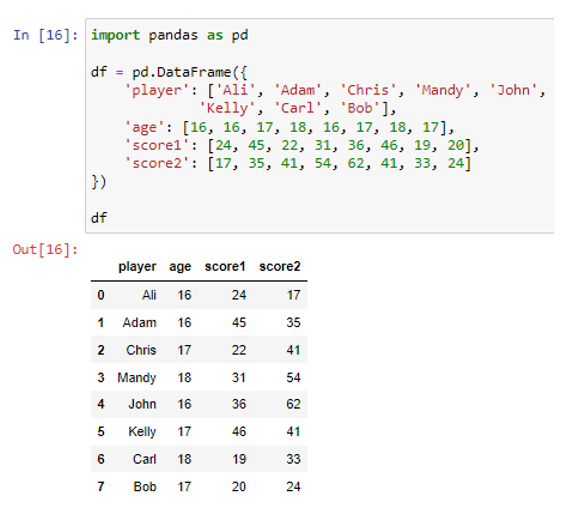
Most csoportosítjuk az adatokat az „életkor” oszlopban, és összegezzük a „score1” és „score2” oszlopok értékeit a csoport egyes kategóriáihoz.
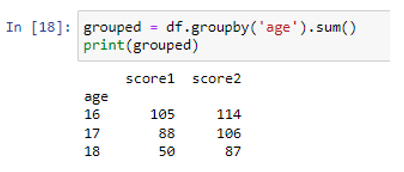
Láthatjuk, hogy az adatkeretben lévő adatok összegzése az adatértékek első kor szerinti csoportosítása után a korcsoportosítások függvényében oszloponkénti összeget eredményez.
Következtetés
Ebben az oktatóanyagban megpróbáltuk megtanítani, hogyan számíthatja ki az adatkeretek összegét a Pandas összeg módszerével. Ennek a bejegyzésnek a példáiban tárgyaltuk az értékek soronkénti és oszloponkénti hozzáadását. Ezenkívül megtanulta, hogyan lehet feltételesen hozzáadni oszlopokat, és hogyan összegezheti az értékeket az adatkeret oszlopának csoportosítása után. Most már összeadhatja az adatkeret oszlopait, vagy összeadhatja az értékeket az adatkeret oszlopon belül.