Szintaxis
A „read_json()” metódus teljes szintaxisa alább látható.
pandák. read_json ( pálya , hajnal = Érték , típus = 'keret' , dtype = Érték , tengelyek konvertálása = Érték , konvert_dátumok = Igaz , az alapértelmezett_dátumok megtartása = Igaz , zsibbadt = Hamis , pontos_úszó = Hamis , dátum_egység = Érték , kódolás = Érték , kódolási_hibák = 'szigorú' , vonalak = Hamis , darab méretű = Érték , tömörítés = 'következtet' , nrows = Érték , tárolási_beállítások = Érték )01. példa
Ezek az útmutatóban bemutatott példák a „Spyder” alkalmazásban kerülnek végrehajtásra. A „read_json()” metódus használata előtt először generáljuk a JSON-fájlt, amelynek adatait a „read_json()” metódussal olvassuk be. Azt is megvitattuk itt, hogyan lehet létrehozni a JSON-fájlt a „pandas”-ban. Itt láthatja, hogy először létrehozzuk a DataFrame-et a „pd.DataFrame()” metódussal.
Ezután hozzáadjuk a „Név, Szám_1, Szám_2, Num_3, Num_4 és Num_5” oszlopot ennek a DataFrame-nek az oszlopaként, és néhány adatot is beillesztünk ezekbe az oszlopokba. Ezt követően a „to_json()” metódust használjuk, amely segít a DataFrame JSON-ba konvertálásában. Beírjuk azt a nevet, amelyet a „JSON” fájlnak szeretnénk adni, amelyben a JSON-adatokat tároljuk. Az itt megadott név „Marks.json”. Tehát a kód végrehajtása után a JSON fájl „Marks.json” néven jön létre, és az itt megadott JSON-ban tárolja az adatokat.
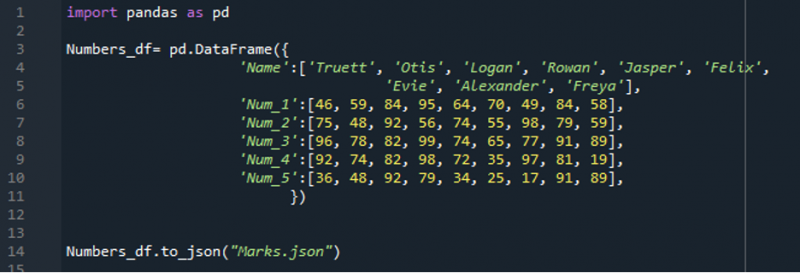
A kód „Shift+Enter” lenyomásával történő végrehajtása után létrejön a JSON fájl, és itt a JSON fájl is látható alább. Ez az a JSON-fájl, amelyet a fenti kód végrehajtása után kapunk. Most továbblépünk, és ezt a JSON-fájlt a „read_json()” metódus segítségével olvassuk be.

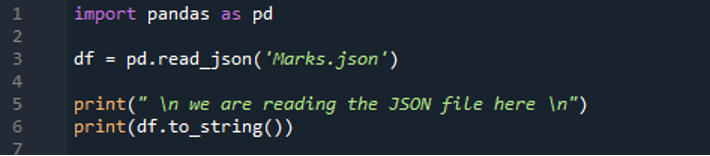
Most először „importáljuk” a „pandas” könyvtárat, mert itt a „read_json()” metódust kell használnunk, ami a „pandas” metódusa. A „pandákat pd-ként importáljuk”. Az alábbiakban a „read_json()” metódust használjuk, és megadjuk annak a fájlnak a nevét, amelynek adatait olvasni szeretnénk. Ide kerül a fent létrehozott fájl, így annak a JSON fájlnak az adatait fogjuk kiolvasni. Ebben a „read_json()” metódusban adjuk át a fájl elérési útját, ami a „Marks.json”, és ezt a függvényt is hozzárendeljük a „df” változóhoz. Tehát a JSON-fájl elolvasása után a JSON-fájl adatai ebben a „df” változóban tárolódnak. Most kinyomtatjuk ezeket az adatokat a „print()” használatával, és hozzáadjuk a „to_string()” metódust is a „df” változóval. Ez a „to_string()” metódus segít nekünk a DataFrame kinyomtatásában. Kinyomtatja a JSON-fájl adatait DataFrame formátumban.
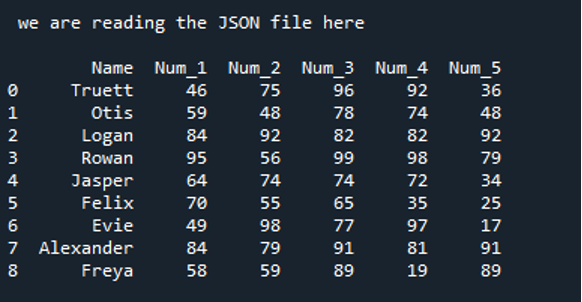
A fenti JSON-fájlban tárolt adatok itt DataFrame-ként jelennek meg az alábbiakban. Megjegyzendő, hogy a JSON-fájl összes adata DataFrame-be konvertálódik, és megjelenik a kimenetben.
02. példa
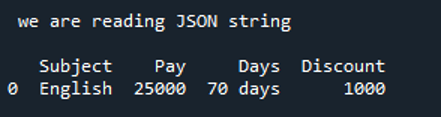
A JSON karakterláncot a „read_json()” metódus segítségével is beolvashatjuk. A „pandák” importálása után itt generálunk egy karakterláncot, és elmentjük a „my_str” változóba. Az itt létrehozott karakterlánc olyan adatokat tartalmaz, amelyek a „Tárgy”, és elhelyezzük az alany nevét, amely „angol”. Ezután hozzáadjuk a „Pay”-t, ami itt „25000”, valamint a „Napokat”, amelyek „70 nap”. Mindezek után hozzáadjuk a „Kedvezményt” is, ami itt „1000”. A JSON karakterlánc itt befejeződött.
Most ezt a JSON-karakterláncot olvassuk a „pandas” „read_json()” metódusával, és elhelyezzük annak a változónak a nevét, amelyben a karakterlánc tárolva van. Ennek a változónak a neve „my_str”, és ide adjuk hozzá a „read_json()” metódus első paramétereként. Ezek után hozzáadunk egy másik paramétert, ami itt az „orient” paraméter, és azt „records”-ra állítjuk. Ezután hozzáadjuk ezt a „my_df”-et a „print()” metódushoz, így ez a kód futtatásakor megjelenik a terminálon.

Az alábbiakban láthatók azok az adatok, amelyeket a JSON karakterlánc elolvasása után kapunk. Itt az adatok a DataFrame-ben jelennek meg, amelyet JSON karakterláncként adtunk meg a kódunkban.
03. példa
Itt létrehozunk egy másik JSON-karakterláncot. Ne feledje, hogy a karakterláncot csak egy sorban kell elhelyeznie. Ha a karakterlánc fennmaradó adatait hozzáadjuk az új sorban, akkor megjelenik a hibaüzenet. Tehát az egész karakterláncot csak egy sorba kell írni. Itt létrejön a JSON karakterlánc, és a „string” változóban tároljuk. Ezután egy JSON-karakterláncot olvasunk a „read_json()” metódus használatával. Ebben a „read_json()” metódusban hozzáadjuk a „karakterláncot”, amelyben a JSON karakterlánc tárolva van. Az olvasás után ezt a karakterláncot a „JSON_Data” változóban tároljuk. Ezt követően a „print()”-t használjuk, és hozzáadjuk a „JSON_Data”-t, ami segít a megjelenítésben.

Az alábbiakban a DataFrame jelenik meg, és ezt a DataFrame-et a JSON-karakterlánc beolvasása után kaptuk meg. A dátum, amelyet a kódunkban JSON-karakterláncként adtunk meg, itt DataFrame-ként jelenik meg.
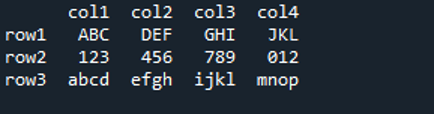
04. példa
Ez a mi JSON-fájlunk, és a „read_json()” metódust alkalmazzuk erre a JSON-fájlra. Beolvassa az ebben a JSON-fájlban található adatokat, és megjeleníti a DataFrame-ben.

Most, mivel a „pandas” könyvtár „read_json()” metódusát kell használnunk, először „importálnunk” kell a könyvtárat. A pandákat „pd” néven importálják. A fent bemutatott fájlt elhelyeztük, hogy ki tudjuk olvasni az adatokat abból a JSON-fájlból. A „Company.json” fájl elérési útja a „read_json()” metódusnak van átadva, és ez a függvény is hozzá van rendelve a „JSON_Rec” változóhoz. A JSON-fájlból származó információk így beolvasás után a „JSON_Rec” változóba kerülnek. Most betesszük a „print()”-et, és hozzáadjuk a „JSON_Rec”-t.
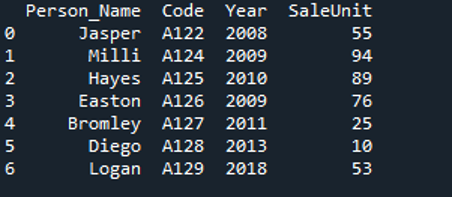
A fent említett JSON-fájlban található adatok az alábbiakban DataFrame-ként jelennek meg. Láthatja, hogy a kimenet egy DataFrame-et jelenít meg, amelybe a JSON-fájlból származó összes adatot konvertálták.
Következtetés
Ebben az útmutatóban részletesen elmagyaráztuk a „pandas” „read_json()” metódusát. Itt bemutattuk a „read_json()” metódus szintaxisát, és ezt a „read_json()” metódust is felhasználtuk a „pandas” kódunkban. Itt elolvastuk a JSON-karakterláncot és a JSON-fájlt a „read_json()” metódus segítségével, és elmagyaráztuk, hogyan hozhat létre JSON-fájlt, majd hogyan olvashatja el a JSON-fájlt. Ebben az útmutatóban azt is elmagyaráztuk, hogyan kell létrehozni a JSON-karakterláncot, és hogyan kell beolvasni a JSON-karakterláncot a „read_json()” metódus segítségével.