„A Python adatstruktúrák és műveletek széles skáláját kínálja a numerikus és idősoros adatok kezelésére. Az általunk létrehozott vagy a Pandasba importált DataFrame számos célra felhasználható. Az adatkeret oszlopai is módosíthatók, az adatforrással együtt. A pandák leegyszerűsítik az adatok kezelésével kapcsolatos unalmas, időigényes feladatokat. Négyféleképpen adhat hozzá oszlopot egy DataFrame-hez a Pandákban, de ebben a cikkben a panda oszlop „insert()” funkcióját használjuk.
Miután elkészítettük vagy betöltöttük a dataFrame-et a Pandasban, számos dolgot szeretnénk megvalósítani. Például folytathatjuk az adatok manipulálását, például az adatkeret oszlopainak megváltoztatásával. Ezt követően meg kell értenünk, hogyan kell oszlopokat beilleszteni egy adatkeretbe, ha az adatok többsége az egyik adatszolgáltatótól érkezik, de bizonyos adatok egy másiktól. Egy oszlop könnyen hozzáadható egy Pandas adatkerethez.”
Panda insert() Metódus
Az adatkeret utolsó oszlopát egy másik függvény hozza létre. A DataFrame „insert()” metódusának használatával oszlopokat vehet fel az aktuális oszlopok közé, nem pedig a panda DataFrame aljára. Lehetőséget kínál arra, hogy tetszőlegesen adjunk hozzá egy oszlopot, nem pedig egyszerűen a befejezéshez. Ezenkívül számos módot kínál az oszlopok értékeinek hozzáadására. Ha egy oszlopot kell hozzáadnia egy megadott pozícióhoz vagy indexhez, a panda „insert()” funkciója hasznos.
A Pandas insert() oszlop szintaxisa

1. példa: Oszlop beszúrása adatkeretbe a Pandas insert() metódussal
Kezdje a cikk első példájával, amelyben elmagyarázzuk, hogyan lehet oszlopot beszúrni egy adatkeretbe. Ezt a kódot a „spyder” eszközzel tudjuk bizonyítani. Először generálunk egy „kurzus” nevű adatkeretet. Ebben az adatkeretben két oszlop található: „course_title” és „fee”. A „course_title” oszlopban található a „python”, „java”, „object_oriented” és „PHP” kurzusok listája. A második „díj” oszlopban található a tanfolyami díjak listája, amely „30000”, „25000”, „15000” és „22000”. DataFrame, „kurzus” megjelenítése a „pd. DataFrame”.
Ezután megvitatjuk a kód fő funkcióját, amely a panda „insert() oszlop”. Hatékony módszer egy új lista felvétele az adatkeretbe. Az új oszlopot bármely megadott helyre felveheti a beszúrási módszerrel. Ez a módszer lehetővé teszi egy oszlop manuális hozzáadását is egy adatkerethez, de kisebb az adaptálhatóság.
Az egész beillesztés azt jelenti, hogy a forrás DataFrame közvetlenül frissül a folyamat során, és nem jön létre új DataFrame. Ebben az esetben az „insert()” függvény segítségével új oszlopot adtunk az adatkeretünkhöz „Time_duration” néven. Az ebben az oszlopban található értékek listája a következő: „6_months”, „3_months”, „3months” és „6_months”. Van egy „Time_duration” oszlopunk, amelynek indexe „2”-ként van definiálva az alábbi programban. A megadott index óta a DataFrame egy 0-val kezdődő tartományt kap, amely lépésenként növekszik, tehát ez azt jelenti, hogy ez az oszlop harmadik oszlopként jelenik meg az adatkeretben. A DataFrame a „pd.insert()” függvény használatával új oszlopot ad hozzá „Time _duration” néven.
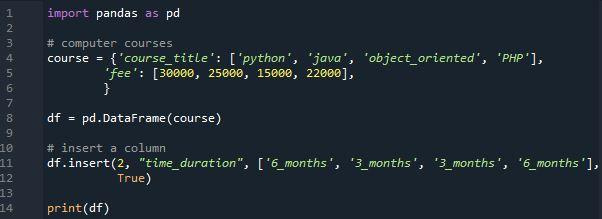
És most beszéljük meg felülről a program kimenetét. A kimenete egy három oszlopból álló adatkeretet mutat. A további oszlop az adatkeret végéhez kerül hozzáadásra. A „pd.DataFrame.insert()” metódus használatával hozzáadhat egy oszlopot a többi oszlophoz, ahelyett, hogy a pandák DataFrame végére adná őket. A Time_ duration” egy új oszlop, amelyet a „beszúrás” segítségével adtunk hozzá. funkció. A „2” pozíció a DataFrame harmadik oszlopára vonatkozik, mivel a pozíció 0-val kezdődik. Az oszlop az adatkeret utolsó helyére kerül hozzáadásra.
2. példa: Oszlopok hozzáadása egy adatkerethez Pandas insert() függvény használatával
Az „insert()” metódust használjuk új oszlopok hozzáadásához az adatkerethez. Ahelyett, hogy további oszlopokat adna hozzá a pandák végéhez, beillesztheti őket a meglévő oszlopok közé. Az előző példához hasonló adatkeret létrehozásához három oszlopot vettünk, és értékeket rendeltünk hozzájuk. Az első, „Név” oszlopban van egy névlista, amely tartalmazza az „Emma”, „Ella”, „Smith” és „Maxwell” nevet. A második „Kor” oszlopban az értékek listája található: „29”, „36”, „39” és „33”.
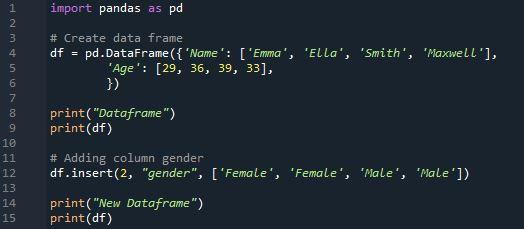
Ezt követően nyomtatunk egy „DataFrame” utasítást. Az adatkeretet az „adatkeret” utasítás alatt fogjuk megjeleníteni. Újabb oszlopot hozunk létre a Pandas adatkerethez az „insert()” függvény használatával. Létre kell hozni egy listát, hogy új oszlopként hozzáadhassuk adott adatkészletünkhöz. A pandas DataFrame „assign()” metódusa további oszlopok hozzáadására is használható. Új oszlopot szúrunk be a „df. beillesztés”. A „Nem” nevű további oszlop a nemet „Férfi” vagy „Nő” formában jeleníti meg.
Nyomtassunk ki egy másik kijelentést: „Új adatkeret”. Most egy új adatkeret jelenik meg az „Új adatkeret” utasítás alatt, amely tartalmazza azt a további oszlopot, amelyet hozzáadtunk a „pd. insert()” függvény. A hasonló nevű oszlop nem adható hozzá az „insert()” függvénnyel. Abban az esetben, ha egy oszlop már létezik az adatkeretben, alapértelmezés szerint Értékhiba jelenik meg.
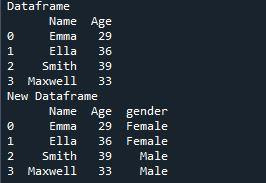
Ebben a kimenetben az az oszlop, amelyet az „insert()” függvény használatával készítettünk, hozzáadódik az adatkerethez. Kimenete két adatkeretet jelenít meg; az első dataFrame a „pd.data frame” használatával jött létre, amelyben két oszlop található, a „Név” és az „Életkor”. Az „insert()” függvény segítségével hozzáadott új „gender” oszlop az alább látható második adatkeretben látható. Ez az adatkeret azt mutatja, hogy három oszlop van néhány adattal. Az index „2” méretű, ami azt jelenti, hogy „0” és „3” közötti bejegyzéseket tartalmaz. Az új oszlop, amelyet ehhez az adatkerethez rendeltünk, indexpozíciója „3”.
Következtetés
Egy gyakran használt adatelemzési és frissítési művelet az oszlopok hozzáadása a DataFrame-hez. A Pandas azonban számos lehetőséget kínál a feladat elvégzésére, négy különböző módszert kínálva; cikkünkben azonban csak egy technikát alkalmazunk, ez a panadas „insert()” oszlop. A DataFrame új oszlopokkal való bővítésének egyik legnehezebb része az indexelés. Röviden írjuk le mindkét példát. Először létrehoztunk egy kurzus című adatkeretet, hozzáadtuk a „kurzus címe” és „díj” oszlopokat, és értékeket rendeltünk ehhez az oszlophoz. Az „insert()” függvény segítségével ezután egy új oszlopot adunk ugyanahhoz az adatkerethez, amely a „2” pozícióját jelzi az indexben. A második példában két dataFrame látható. Létrehoztunk két oszlopot, és felsoroltunk néhány értéket az első adatkeretben. Ezután az insert() függvénnyel új oszlopot szúrtunk be az adatkeretbe „Gender” néven, és ez szintén „2”-ként került az indexbe; most ismét megjelenítette a táblázatot, ahogy a fenti második példában is látható.
A fenti technikák elsajátítása után könnyedén hozzáadhatunk új oszlopokat a DataFrame-hez.