„A Pythonban egy szótárnak nevezett adatszerkezetet használnak az információk kulcs-érték párokkénti tárolására. A szótárobjektumok optimalizálva vannak az adatok/értékek kinyerésére, ha a kulcs vagy kulcsok ismertek. Ne feledje, hogy a szótárak duplikált kulcsokat tartalmazhatnak. Ahhoz, hogy a kapcsolódó index segítségével hatékonyan megtaláljuk az értékeket, átalakíthatunk egy releváns indexet tartalmazó pandas sorozatot vagy adatkeretet „index: érték” kulcs-érték párokkal rendelkező szótárobjektummá. Ennek a feladatnak a megvalósításához a „to_dict()” metódus használható. Ez a funkció a panda modul Series osztályában található beépített funkció. Az adatkeret a pandas.to_dict() metódussal python listaszerű adatszótárrá konvertálódik, az orient paraméter megadott értékétől függően.
Hogyan lehet a pandákat Python szótárrá alakítani?
Számos módszer létezik a pandák szótárrá alakítására. Ahhoz azonban, hogy egy Pandas adatkeretet Python szótárrá alakítsunk át, a to_dict() metódust használjuk a Pandasban. A visszaadott szótár kulcs-érték párjait többféleképpen orientálhatjuk a to_dict() függvény segítségével. A függvény szintaxisa a következő:
Szintaxis
pandas.to_dict ( kelet = „dikt”, -ba = )
Paraméterek
hajnal: Azt, hogy az oszlopokat (sorokat) melyik adattípusba kell konvertálni, a karakterlánc értéke határozza meg („dict”, „list”, „records”, „index”, „series”, „split”). Például a „lista” kulcsszó a listaobjektumok Python szótárát adná meg kimenetként az „Oszlopnév” és a „Lista” (konvertált sorozat) kulcsokkal.
ba: osztály, példányként vagy tényleges osztályként is átadható. Például egy osztálypéldány átadható alapértelmezett diktatúra esetén. A paraméter alapértelmezett értéke dict.
Visszaküldés típusa: Adatkeretből vagy sorozatból konvertált szótár.
01. példa: A Pandas Dataframe átalakítása szótárrá
A pd.DataFrame() függvény listáinak használatával létrehozunk egy alapvető adatkeretet néhány oszlopból és sorból, hogy később python szótárrá alakíthassuk.
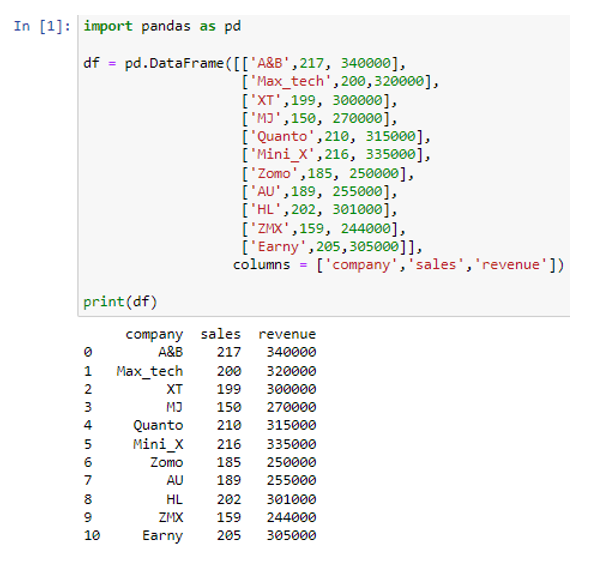
Adatkeretünket úgy hoztuk létre, hogy a listát a pd.DataFrame() függvényen belül átadtuk. A fenti adatkeretben három oszlop található: „vállalat”, „értékesítés” és „bevétel”. A cég oszlopban véletlenszerű cégek neveit tároltuk ('A&B', 'Max_tech', 'XT', 'MJ', 'Quanto', 'Mini_X', 'Zomo', 'AU', 'HL') , „ZMX”, „Earny”), az „értékesítés” oszlop az egyes vállalatok eladásait jelöli („217”, „200”, „199”, „150”, „210”, „216”, „185”). ”, „189”, „202”, „159”, „205”), és a „bevétel” oszlop az egyes vállalatok bevételeit és a megfelelő értékesítéseket reprezentáló értékeket tárolja (340000 320000 300000 270000 315000 0 315000 335000 50 040 305000). Most a „df” adatkeretünket python szótárrá alakítjuk.
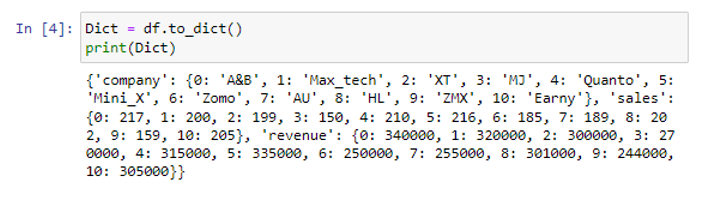
A to_dict() metódus df dataframe-re történő alkalmazásával egy pandas adatkeretet szótárrá alakítottunk át.
02. példa: A CSV-fájlból létrehozott Pandas adatkeret átalakítása szótárrá
Az 1. példában létrehoztunk egy adatkeretet a listán belüli sorok használatával. Most egy CSV-fájl segítségével készítünk egy adatkeretet, majd a to_dict() függvény segítségével szótárrá alakítjuk.
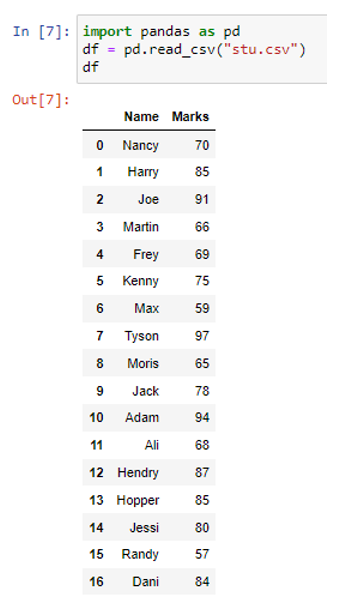
Egy fájl adatkeretként való olvasásához a pd.read_csv() függvényt használtuk. A fenti adatkeretben két oszlop (Név és Jelek) és tizenhét sor (0-tól 16-ig) található. Most a to_dict() metódust fogjuk használni.
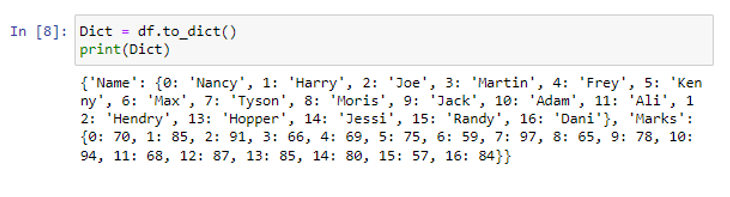
A függvény a „df” adatkeretünket python szótárrá alakította át.
03. példa: A Pandas Dataframe konvertálása az értéklistákat tartalmazó szótárba
A korábbi példákban a pandákat több szótárat tartalmazó python szótárrá alakítottuk át. Amikor egy adatkeretet szótárobjektummá konvertál, az oszlopcímkéknek a szótár kulcsaiként kell szolgálniuk, és az oszlopok összes adatát vagy értékét hozzá kell adni a szótárhoz az egyes kulcsokhoz tartozó értéklistaként.
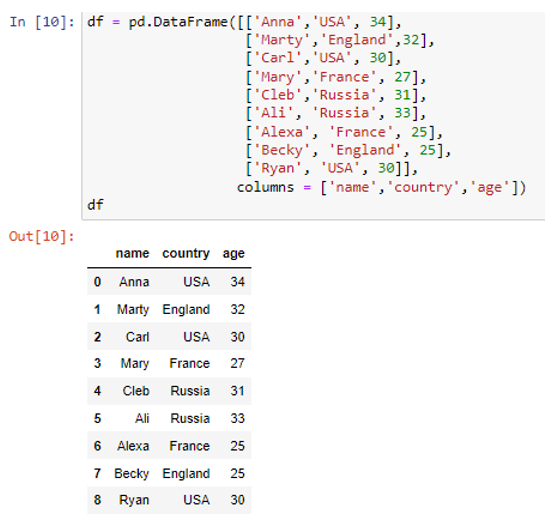
Létrehoztuk a három oszlopból álló adatkeretet: „név”, „ország” és „életkor”. A „név” oszlopban tároltuk az adatértékeket („Anna”, „Marty”, „Carl”, „Mary”, „Cleb”, „Ali”, „Alexa”, „Becky”, „Ryan”). . Míg a többi oszlop ország és életkor erős értékek ('USA', 'Anglia', 'USA', 'Franciaország', 'Oroszország', 'Oroszország', 'Franciaország', 'Anglia', 'USA') és ( 34, 32, 30, 27, 31, 33, 35, 25, 30). Létrehozunk egy szótárt, amely tartalmazza a listákat a to_dict() metóduson belüli „list” paraméter használatával.
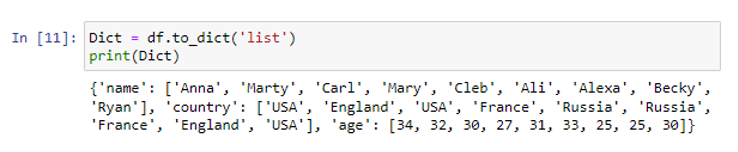
A list paramétert a to_list() függvényen belül argumentumként használva létrehoztunk egy több listát tartalmazó szótárat.
03. példa: A Pandas Dataframe konvertálása az értékek sorozatát tartalmazó szótárrá
Ha egy DataFrame-et szótárrá kell alakítani, az oszlop neve a szótár kulcsaként, a sorindex és az oszlopban lévő adatok pedig a szótár megfelelő kulcsainak értékeként szolgál.
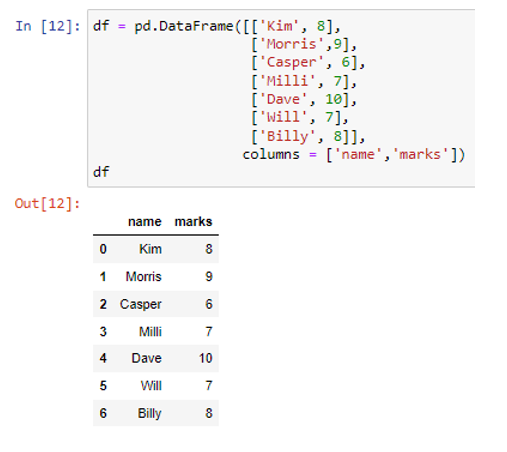
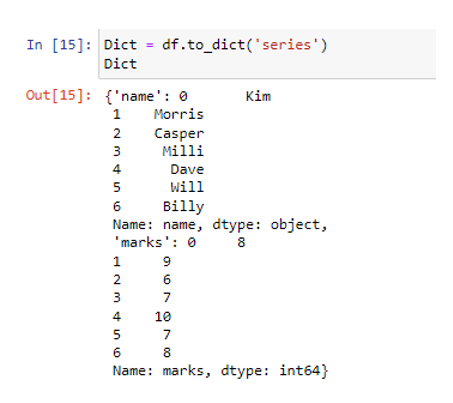
Létrehoztuk a szükséges adatkeretet a pd.DataFrame() metódussal. A nemrég létrehozott adatkeretben két oszlop található. A név oszlop az adatértékeket karakterláncként tárolja („Kim”, „Morris”, „Casper”, „Milli”, „Dave”, „Will”, „Billy”), míg a jelölések oszlopai numerikus adatokból állnak, mint ( 8, 9, 6, 7, 10, 7, 8). A „series” paramétert karakterláncként fogjuk használni a to_dict() függvényen belül.
04. példa: A Pandas Dataframe konvertálása szótárrá index és fejléc nélkül
A to_dict() függvény „split” paramétere felhasználható adatok kinyerésére egy DataFrame-ből az oszlopok fejlécei nélkül, vagy amikor el kell távolítanunk a fejlécet és a sorindexet az adatokból. Az oszlopcímkék, a sorindex és a tényleges adatok három összetevőre oszthatók fel ezzel a paraméterrel. Hozzunk létre egy adatkeretet, így azt három részre bonthatjuk, miközben szótárba konvertáljuk.
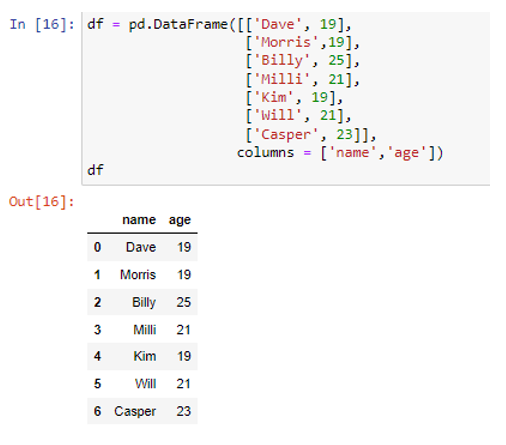
Létrehoztunk két oszlopot „név” és „életkor” címkékkel, amelyek értékeket tartalmaznak („Dave”, „Morris”, „Billy”, „Milli”, „Kim”, „Will”, „Casper”) és (19, 19). , 25, 21, 19, 21, 23) ill. Alakítsuk át őket python szótárakká.

Az „adat” kulcs használatával az eredményül kapott szótárból index és fejléc nélkül is lekérhetjük az adatokat.

05. példa: A Pandas Dataframe konvertálása a szótárba sor és sorindex alapján
A „record” paraméter használható a to_dict() függvényen belül, hogy az egyes adatkeret-sorok adatait több különálló szótárobjektumban tároljuk egy listán belül, vagy ha soronkénti adatokra van szükség. A szótárobjektumokat tartalmazó lista jelenik meg. Egy szótár, amelynek kulcsa oszlopcímke, értéke pedig minden sor oszlopadata.
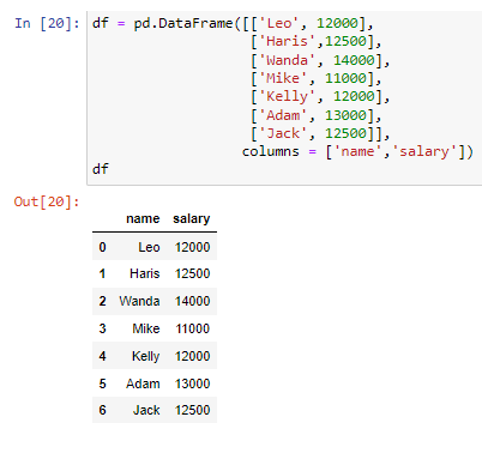
Létrehoztunk egy adatkeretet „név” és „fizetés” oszlopokkal. A „név” oszlop tartalmazza az adatértékeket („Leo”, „Haris”, „Wanda”, „Mike”, „Kelly”, „Adam”, „Jack”), a fizetés oszlop pedig az értékeket (12000, 12500). , 14000, 11000, 12000, 13000, 12500). Most hozzunk létre egy listát több python szótárral, amelyek az egyes sorok adatait tartalmazzák.

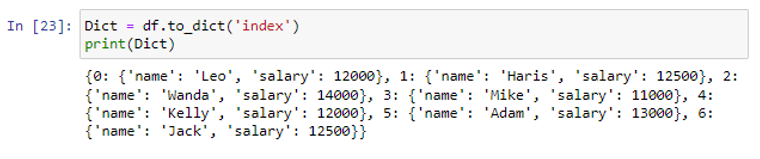
Az index paraméter arra is használható, hogy az egyes sorok adatait adatkeretből szótárba konvertálja. A szótárelemeket tartalmazó lista jelenik meg. Minden sor létrehoz egy szótárt. Ahol a sorindex lesz a kulcs, az érték pedig az adatszótár és az oszlopcímke.
Következtetés
Ebben az oktatóanyagban megvitattuk, hogyan alakíthatjuk át az adatkeretet vagy a pandas objektumokat python szótárrá. Láttuk a to_dict() függvény szintaxisát, hogy megértsük ennek a függvénynek a paramétereit, és hogyan módosíthatjuk a függvény kimenetét a függvény különböző paraméterekkel történő megadásával. Ennek az oktatóanyagnak a példáiban a to_dict() metódust, egy beépített pandas függvényt használtuk, hogy a pandas objektumokat a python szótárba cseréljük.