A pandák olyan gyakori alkalmazások, hogy hasznosabb lehet felsorolni azokat a dolgokat, amelyeket nem tudnak megvalósítani, mintsem azokat, amelyeket meg tudnak tenni. Az Ön adatai gyakorlatilag ebben az eszközben élnek. A Pandák tisztításával, átalakításával és elemzésével segíthetnek az adatok megismerésében. A „lambda” egy alternatív módszer egy függvény definiálására hétköznapi nyelven. A „lambda” használatával közvetlenül definiálhat egy függvényt. Ez azt jelenti, hogy a Python-kód egyetlen mondatával is alkalmazhat egy függvényt bizonyos adatokra. Míg egy kifejezés egynél több paramétert is felvehet, a „lambda” függvény egyre korlátozódik. A kifejezést értékeljük, és eredményt kapunk. A Python's Pandas a „lambda” funkciót használja számos adatkutatási probléma megoldására. A pandas DataFrame-ben a „lambda” függvényt használhatjuk mind a sorokhoz, mind az oszlopokhoz.
A „Lambda” egy rendkívül méretezhető technológiai vállalaton hajtja végre a programját, és kezeli az összes számítógépes eszköz adminisztrációját. Ez magában foglalja a frissítések telepítését, a kapacitáskiépítést, az automatikus méretezést, a kódelemzést és -rögzítést, valamint a szerver- és üzemeltetési karbantartást. A Pandas „Lambda” funkciója kis kapacitású, csak egy csuklóval. A „lambda” képességek ugyanúgy működhetnek olyan helyzetekben is, ahol nem nevezik őket. A „lambda” a függvény kulcsszava. A végrehajtandó függvény törzsét a második x jelzi. A kulcsszónak „lambda”-nak kell lennie, és kötelező, de az érvek és a szöveg a körülményektől függően eltérőek lehetnek. A függvényobjektumok visszaadása lambda függvényekkel lehetséges.
A lambda függvény szintaxisa:

1. példa: DataFrame használata Lambda-módszer végrehajtásához egy új oszlophoz az assign() metódus alkalmazásával
A „Lambda” megközelítést a Pandák használják különféle információfeldolgozási problémák megoldására. Egy rövid funkció, a „Lambda” metódus névtelenül is használható, ami azt jelenti, hogy nincs szüksége névre. A „lambda” módszerrel minimális programokat írhatunk és egyszerű problémákat is megoldhatunk. A magasrendű függvényeket támogató nyelveken a „lambda” kifejezések vagy a „lambda” technikák egyszerűen olyan utasítások darabjai, amelyek változókhoz rendelhetők, argumentumként adhatók át, vagy függvényhívásból lekérhetők. Régóta a programozás részét képezik. A cikk első példájától kezdve a kód végrehajtásának alapvető feltétele a szükséges könyvtárak betöltése. A „Pandas” könyvtár az, amire szükségünk van. A betöltéshez létre kell hoznunk az „import panda as pd” sort. Most elkészítjük adatkeretünket.
Ebben a példában az adatkeretünket „tanulóknak” nevezzük. Adatkeretünk ezután két további oszlopot kap. Az első oszlop neve „Nevek”, a második pedig „Jellékek”. A két oszlop mindegyike tartalmaz bizonyos értékeket. Az első oszlopban a következő értékek találhatók: „Alvin”, „Watson”, „Thomas” és „Noah”, valamint a második „Jelek” oszlop értéke. A „400”, „360”, „430” és „290” számunk van. Most a „pd.DataFrame” használatával generálja a DataFrame-et.
Ezután elérjük a kódunk nagy részét, ahol az „assign()” metódust használjuk a „lambda”-val egy új egyetlen oszlop létrehozásához. A „Lambda” függvény csak egy oszlopra kerül alkalmazásra a „dataframe.assign()” metóduson keresztül. A lambda egy további módszer a függvények hétköznapi nyelven történő leírására. A lambda használatával közvetlenül definiálhat egy függvényt. Ez azt jelenti, hogy a Python-kód egyetlen sorát használhatja egy függvény alkalmazására bizonyos adatokra. Most hozzárendelünk egy új „Percentage” oszlopot az adatkeretünkben az „assign()” metódussal.
A „Mark” oszlopon „lambda” eljárást alkalmaztunk. A tanulók százalékos arányát a Lambda-függvény segítségével számítják ki, majd egy új oszlopban tartják, ami a „százalék”. A százalékos arány meghatározásához használt képlet a „lambda” használatával a „pontok vagy összpontszámok, ami 500 és 100-zal szorozva”, amely a tanuló pontos százalékát adja meg, és megjeleníti az adatkeret „százalék” oszlopában. A „print(dataframe)” most megjeleníti az adatkeretet a képernyőn.
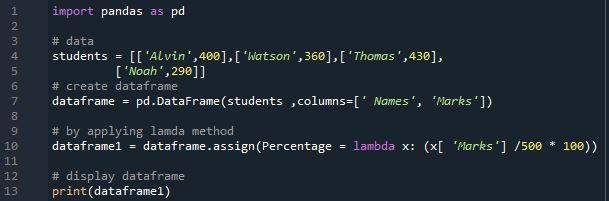
Megtekinthetjük ennek a kódnak az eredményét. Ezen a képen a három oszlopos adatkeret jelenik meg. Az első oszlop a tanuló nevét, a második oszlop pedig a tanuló érdemjegyeit tartalmazza. Az „assign()” metódus és a „lambda” függvény segítségével a harmadik oszlop „százalékának” megalkotásához meghatározhatjuk a tanuló százalékait, majd hozzáadhatjuk ezeket a százalékokat a harmadik oszlophoz, amelyet az adatkeretben „százaléknak” neveznek. . A százalékos oszlopokhoz a képlet segítségével kapott értékek a következők voltak: „80”, „72”, „86” és „58”. Az index mérete „4” ebben az adatkeretben.
2. példa: Lambda függvény megvalósítása az assign() metódus használatához több oszlopban
A Pandas DataFrame assign() technikája lehetővé teszi a Lambda függvény használatát számos oszlopon. Minden alkalommal, amikor új függvényre van szükség, például lambda függvényre vagy rendezési függvényre, szabadon hozzáadhatjuk. A Pandas adatkeret oszlopai és sorai egyaránt kezelhetők lambda függvénnyel. Ebben a forgatókönyvben egy adatkeret létrehozásával kezdjük. A „Student result” az adatkeret neve. Ebben az adatkeretben négy oszlop található. Az első oszlopunk a „Nevek”. A második oszlop a „Python”. A harmadik oszlop neve „Data_structure”. A negyedik neve „Kalculus”.
Ezekben az oszlopokban felsoroltunk néhány értéket. A „Nevek” oszlophoz néhány diák neve „Willow”, „Alice”, „Edward” és „Amelia” található. A python „96”, „40”, „98” és „98” jelöléseit a második oszlopban lévő értékek képviselik. A harmadik oszlop értékei „86”, „56”, „73” és „90”, a negyedik oszlopban pedig „90”, „33”, „88” és „78”. Most használja a „pd.DataFrame”-t az adatkeret létrehozásához.
Most új oszlopot adunk az adatkeretünkhöz a „hozzárendelés” módszerrel. Az új oszlop az „Összes pontszám” címet viseli. Az új oszlop neve „Total_marks”. Az általános pontszámok eléréséhez „Lambda” függvényt használtunk több tárgyoszlopon, beleértve a Pythont, az adatstruktúrát és a számítást. Ez a funkció összeadja mindhárom tárgy pontszámát, és megjeleníti azokat az „Összes_pontszám” oszlopban. A „print(dataframe)” végül megjeleníti az adatkeretet a képernyőn.
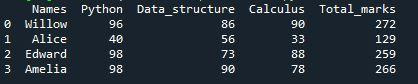
Ezúttal erre az eredményre jutottunk. A „Lambda” funkció kiváló eredményt biztosít, ha több oszlopban is használja. Új „Total_marks” oszlopot rendelünk az adatkeretünkhöz a „hozzárendelés” módszerrel, hogy a tanuló összesített eredményét megjeleníthessük ebben az oszlopban. Végül láthatjuk, hogy az „Összes pontszám” oszlopban mindhárom tárgy összesített eredménye látható. Az összesített pontszám oszlopainak számát úgy számítottuk ki, hogy három oszlopból összeadtuk az értékeket a „272”, „129”, „259” és „266” lambda használatával.
Következtetés
A Python programozási nyelvben a lambda függvény egy névtelen, egysoros függvény, amely egy argumentumot és végtelen számú paramétert vesz fel. Több érvet is felhozhatnak, de ezek közül csak egy kerül kifejtésre. A lambda-munka visszaállít egy kapacitásobjektumot, amely bármely tényezőhöz hozzárendelhető, és nem tud semmilyen állítást tartalmazni. Az első esetben a „lambdát” használták a százalékos arány meghatározásához, a második példában pedig a tanulók „összes jegyeit” számolták ki. Ez a cikk a tipikus „lambda” függvények szintaxisával, felhasználásával és példáival foglalkozik.