Az Elasticsearch egy robusztus, közkedvelt megoldás terjedelmes, strukturálatlan és félig strukturált adatok tárolására. Ez tisztán egy NoSQL-adatbázis, és teljesen más megközelítést használ az adatok tárolására, kezelésére és lekérésére. Az adatokat JSON formátumú dokumentumban tárolja, és rest API-kat használ a tárolt adatokon végzett különböző műveletek végrehajtására.
Ebben a blogban bemutatjuk:
- Hogyan működik az Elasticsearch az adatok tárolásában és keresésében?
- Mik azok az Elasticsearch dokumentumok?
- Hogyan tárolhatunk adatokat egy Elasticsearch dokumentumban?
Hogyan működik az Elasticsearch az adatok tárolásában és keresésében?
Az alábbiakban felsoroljuk az adatok tárolására használt Elasticsearch fő összetevőit vagy hierarchiáját:
- Dokumentum: A dokumentum az Elasticsearch fő része, amely JSON formátumban tárolja az adatokat. Mint
- Indexek: Az indexeket indexeknek nevezzük. Ez egy dokumentumgyűjtemény. Az SQL-hez hasonlóan adatbázisnak nevezik.
- Fordított indexek: Támogatja a nagyon gyors teljes szöveges keresést. A szót indexként, a dokumentum nevét pedig hivatkozásként tárolja.
Mik azok az Elasticsearch dokumentumok?
Az Elasticsearch dokumentum JSON formátumú adatok tárolási egysége. A relációs adatbázisokhoz hasonlóan a dokumentumot táblának vagy adatbázissornak nevezhetjük, amelyet valamilyen indexben tárolnak. Az index több dokumentumot tartalmazhat, és több táblát tartalmazó adatbázisnak nevezik. Általában összetett adatstruktúrát tárol, és JSON formátumban sterilizálja az adatokat.
Ezenkívül minden dokumentum több mezőt is tartalmazhat, amelyek kulcs érték ” párok az adatok tárolására, mint ahogy egy táblának több oszlopa vagy mezője van egy relációs adatbázisban. Ezután ezeket a kulcs-érték párokat úgy kell indexelni, hogy meghatározzák a dokumentumleképezést. A leképezés ezután meghatározza a dokumentum adattípusát a mezőadatok szerint, például szöveg, lebegés, földrajzi pont, idő és még sok más.
Az Elasticsearch soha nem kötelezett bennünket arra, hogy előre meghatározzuk az indexmező szerkezetét, és a dokumentumok eltérő mezőszerkezettel rendelkezhetnek egy indexben. Ha azonban a mező leképezése egy adott adattípushoz van definiálva, akkor egy indexben lévő összes Elasticsearch dokumentumnak ugyanazt a leképezési típust kell követnie. Ha meg szeretné tekinteni a dokumentum működését az adatok tárolására az Elasticsearch programban, menjen végig a következő szakaszon.
Hogyan tárolhatunk adatokat egy Elasticsearch dokumentumban?
Ahhoz, hogy adatokat tároljon az Elasticsearch alkalmazásban, a felhasználónak először létre kell hoznia egy indexet. Ezután adja meg azokat a mezőket, amelyek az Elasticsearch dokumentumban tárolják az adatokat. A bemutatóhoz hajtsa végre a felsorolt lépéseket.
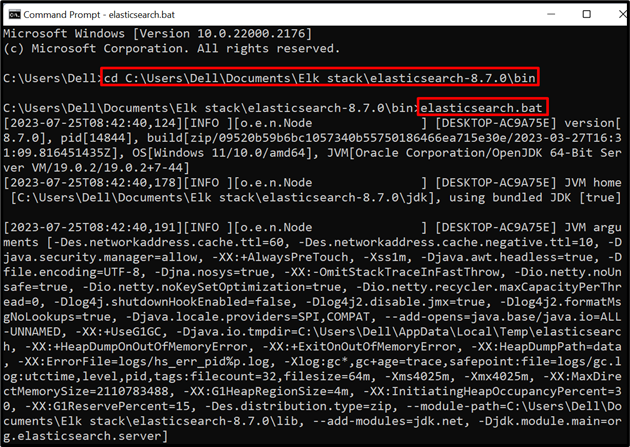
1. lépés: Indítsa el az Elasticsearch programot
Az Elasticsearch adatbázis vagy motor rendszeren való futtatásához indítsa el a rendszerterminált, például a parancssort. Ezt követően látogassa meg a ' kuka ” mappában az Elasticsearch a „ CD 'parancs:
CD C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Ezután futtassa az Elasticsearch kötegfájlját az adatbázis futtatásához a rendszeren:
elaszticsearch.bat
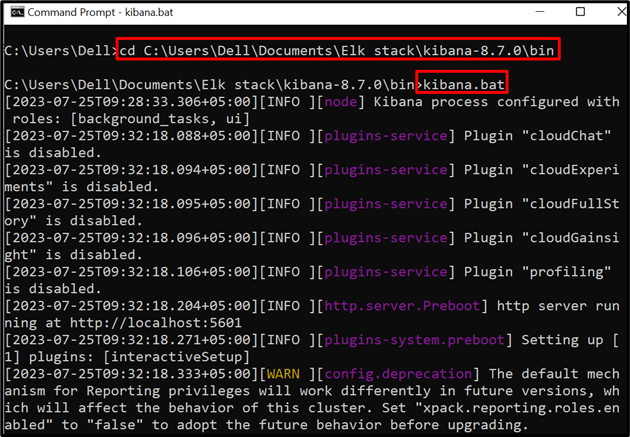
2. lépés: Indítsa el a Kibanát
Ezután futtassa a Kibanát a rendszeren. Ehhez látogassa meg a „ kuka ” mappa a parancssorból:
CD C:\Users\Dell\Documents\Elk Stack\kibana-8.7.0\bin
Ezután futtassa az alábbi parancsot a Kibana végrehajtásának elindításához:
kibana.bat
Jegyzet: Ha még nem telepítette és állította be az Elasticsearch-ot és a Kibanát a rendszeren, keresse meg bejegyzéseinket, és nézze meg a lépésről lépésre történő telepítési eljárást a rendszerre.
Az Elasticsearchért látogassa meg „ Telepítse és állítsa be az Elasticsearch .zip fájlt Windows rendszeren ” cikk. A Kibana Windows rendszeren történő beállításához kövesse a „ A Kibana beállítása az Elasticsearch számára ” cikk.
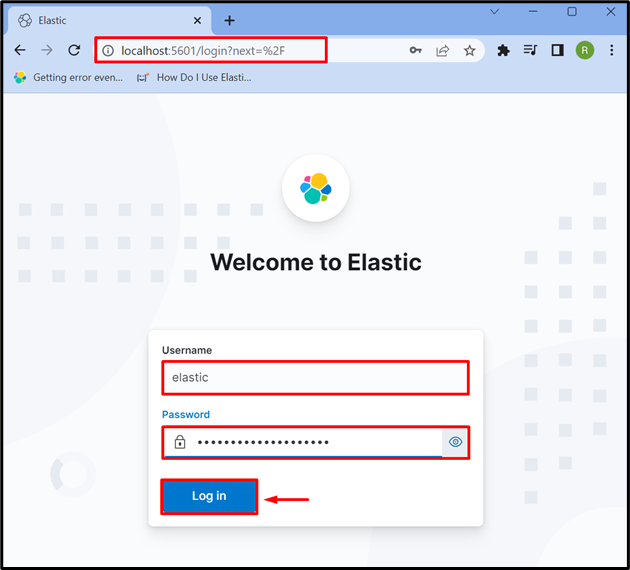
3. lépés: Jelentkezzen be a Kibanába
Miután elindította a Kibanát a rendszeren, navigáljon a Kibana alapértelmezett címére ' localhost:5601 ” a böngészőben, és adja meg az Elasticsearch bejelentkezési adatait, például „ rugalmas ” felhasználó és jelszó. Ezt követően nyomja meg a „ Belépés ” gomb:
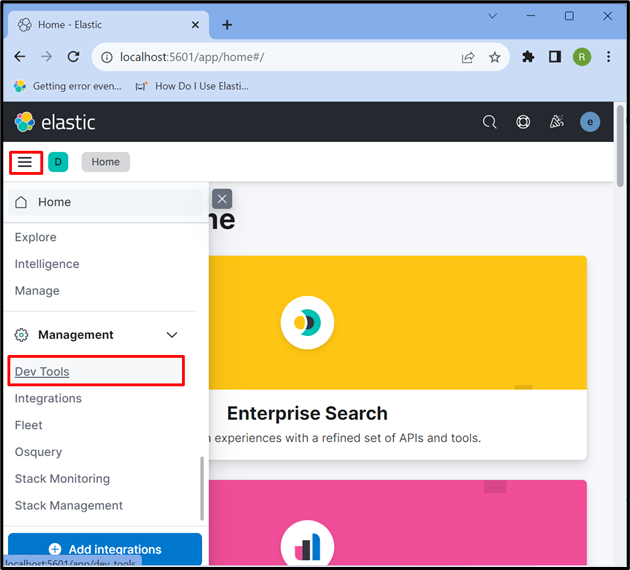
4. lépés: Nyissa meg a Kibana „fejlesztői eszközt”
Ezt követően kattintson a „ Három vízszintes sáv ' ikonra, és nyissa meg a Kibanát' Fejlesztői eszköz ” az API-k használatához az adatok tárolására, lekérésére és frissítésére:
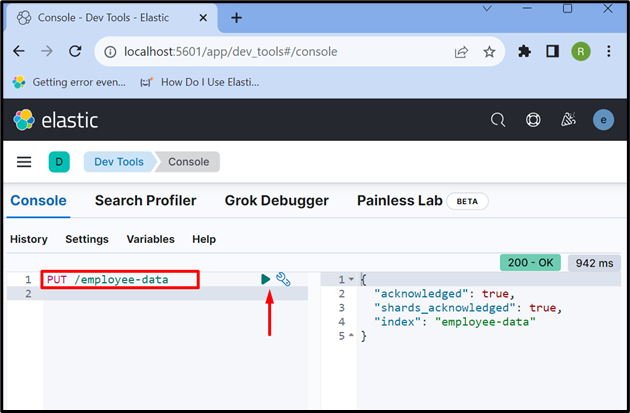
5. lépés: Index létrehozása
Most hozzon létre egy új indexet a ' PUT /
A kimenet azt mutatja, hogy a „ munkavállalói adatok ” index sikeresen létrejött:
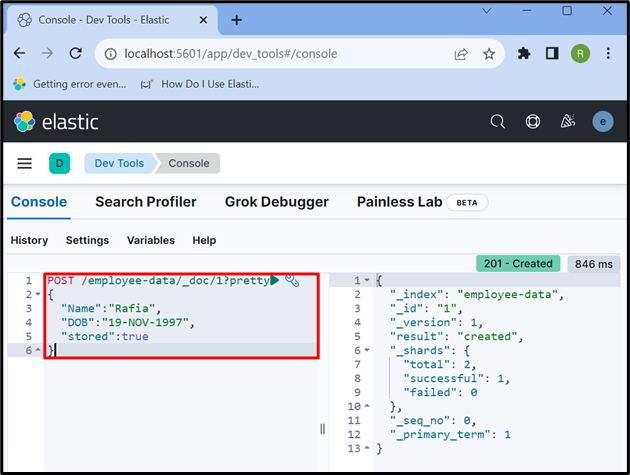
6. lépés: Adatok beszúrása a dokumentumba
Most használja a „ POST ” API az adatok indexben való tárolására. Az alábbi kérésben „ munkavállalói adatok ' az Elasticsearch indexe, ' _doc ' az Elasticsearch dokumentumban tárolt adatok tárolására szolgál, és a ' 1 ” az azonosító:
POST / munkavállalói adatok / _doc / 1 ?szép{
'Név' : 'Rafia' ,
'DOB' : '1997. NOV. 19.' ,
'tárolt' :igaz
}
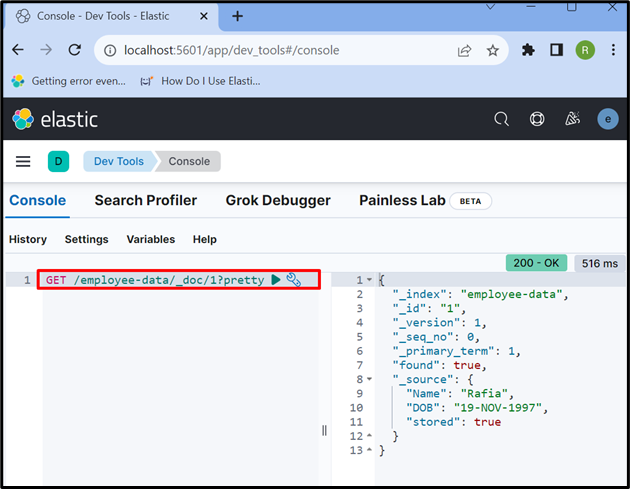
7. lépés: Adatok lekérése az Elasticsearch dokumentumból
Az index vagy az Elasticsearch dokumentum adatainak eléréséhez használja a „ KAP ” API az alábbiak szerint:
KAP / munkavállalói adatok / _doc / 1 ?szép
A kimenet azt mutatja, hogy sikeresen kinyertük az adatokat az Elasticsearch dokumentumból, amelynek azonosítója ' 1 ”:
Ennyi az Elasticsearch-dokumentumról.
Következtetés
Az Elasticsearch dokumentumot általában JSON formátumú adatok tárolására használják. A relációs adatbázisokhoz hasonlóan a dokumentumra úgy hivatkozhatunk, mint egy sorra, amelyet valamilyen indexben tárolnak. Ezek az indexek több dokumentumot is tartalmazhatnak, csakúgy, mint az adatbázisok különböző táblákat. Ezek a dokumentumok több mezőt tartalmaznak, amelyek ' kulcs érték ” párokat az adatok tárolásához. Ez a cikk bemutatja, mik azok az Elasticsearch-dokumentumok, és hogyan működnek az Elasticsearch-ben.