A mesterséges intelligencia az egyik leggyorsabban növekvő technológia, amely gépi tanulási algoritmusokat használ a modellek betanítására és tesztelésére hatalmas adatok felhasználásával. Az adatok különböző formátumokban tárolhatók, de a LangChain használatával nagy nyelvi modellek készítéséhez a leggyakrabban használt típus a JSON. A betanítási és tesztelési adatoknak világosnak és teljesnek kell lenniük minden félreérthetőség nélkül, hogy a modell hatékonyan működhessen.
Ez az útmutató bemutatja a pydantikus JSON-elemző használatának folyamatát a LangChainben.
Hogyan kell használni a Pydantic (JSON) elemzőt a LangChainben?
A JSON-adatok az adatok szöveges formátumát tartalmazzák, amelyek webes lekaparással és sok más forrásból, például naplókból stb. gyűjthetők össze. Az adatok pontosságának ellenőrzésére a LangChain a Python pydantikus könyvtárát használja a folyamat egyszerűsítésére. A pydantikus JSON-elemző használatához a LangChainben egyszerűen kövesse ezt az útmutatót:
1. lépés: Modulok telepítése
A folyamat megkezdéséhez egyszerűen telepítse a LangChain modult, hogy a könyvtárait használja a LangChain elemző használatához:
csipog telepítés langchain
Most használja a „ pip telepítés ” parancs az OpenAI keretrendszer beszerzéséhez és erőforrásainak használatához:
csipog telepítés openai
A modulok telepítése után egyszerűen csatlakozzon az OpenAI környezethez az API kulcs megadásával a „ te ” és „ getpass ” könyvtárak:
importálni minketimport getpass
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API kulcs:' )

2. lépés: Könyvtárak importálása
A LangChain modul segítségével importálhatja a szükséges könyvtárakat, amelyek segítségével sablont hozhat létre a prompthoz. A prompt sablonja leírja a természetes nyelvű kérdések feltevésének módszerét, hogy a modell hatékonyan megértse a promptot. Ezenkívül importáljon könyvtárakat, például az OpenAI-t és a ChatOpenAI-t, hogy LLM-eket használva láncokat hozzon létre egy chatbot felépítéséhez:
a langchain.prompts importból (PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
a langchain.llms-ből importálja az OpenAI-t
a langchain.chat_models webhelyről importálja a ChatOpenAI-t
Ezt követően importáljon pydantikus könyvtárakat, például a BaseModelt, a Field-et és a validátort a JSON-elemző használatához a LangChainben:
a langchain.output_parsers webhelyről importálja a PydanticOutputParser-tpydantic importból BaseModel, Field, validator
az importlista beírásából
3. lépés: Modell készítése
Miután megszerezte a pydantic JSON-elemző használatához szükséges összes könyvtárat, egyszerűen szerezze be az előre megtervezett tesztelt modellt az OpenAI() metódussal:
modell_neve = 'text-davinci-003'hőmérséklet = 0.0
modell = OpenAI ( modell név =modell_neve, hőfok = hőmérséklet )
4. lépés: Az Actor BaseModel konfigurálása
Készítsen egy másik modellt, hogy válaszokat kapjon a színészekre, például a nevükre és a filmjeikre, ha elkéri a színész filmográfiáját:
osztályú Színész ( BaseModel ) :név: str = Mező ( leírás = 'A főszereplő neve' )
film_names: Lista [ str ] = Mező ( leírás = 'Filmek, amelyekben a színész szerepelt' )
színész_lekérdezés = 'Bármelyik színész filmográfiáját szeretném látni'
parser = PydanticOutputParser ( pydantic_object = Színész )
prompt = PromptTemplate (
sablon = 'Válaszoljon a felhasználó kérdésére. \n {formátum_utasítások} \n {lekérdezés} \n ' ,
bemeneti_változók = [ 'lekérdezés' ] ,
részleges_változók = { 'formátum_utasítások' : parser.get_format_instructions ( ) } ,
)
5. lépés: Az alapmodell tesztelése
Egyszerűen szerezze be a kimenetet a parse() függvény segítségével a prompthoz generált eredményeket tartalmazó kimeneti változóval:
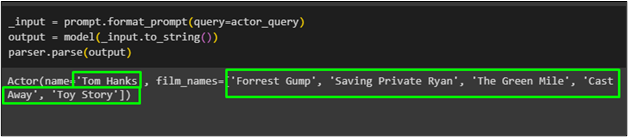
_input = prompt.format_prompt ( lekérdezés =színész_lekérdezés )kimenet = modell ( _input.to_string ( ) )
elemző.elemzés ( Kimenet )
A színész, akit ' Tom Hanks ” filmjei listájával a pydantic függvény segítségével lett lekérve a modellből:
Ez minden a pydantikus JSON-elemző használatáról szól a LangChainben.
Következtetés
A pydantikus JSON-elemző használatához a LangChainben egyszerűen telepítse a LangChain és az OpenAI modulokat, hogy csatlakozzon az erőforrásokhoz és a könyvtárakhoz. Ezután importáljon könyvtárakat, például az OpenAI-t és a pydantic-ot, hogy létrehozzon egy alapmodellt, és ellenőrizze az adatokat JSON-formátumban. Az alapmodell felépítése után futtassa a parse() függvényt, és az visszaadja a prompt válaszait. Ez a bejegyzés bemutatta a pydantic JSON-elemző használatának folyamatát a LangChainben.