Ez az útmutató bemutatja a VectorStoreRetrieverMemory használatát a LangChain keretrendszer használatával.
Hogyan használjuk a VectorStoreRetrieverMemory-t a LangChainben?
A VectorStoreRetrieverMemory a LangChain könyvtára, amely felhasználható információk/adatok kinyerésére a memóriából a vektortárak segítségével. A vektortárak használhatók adatok tárolására és kezelésére, hogy hatékonyan kinyerhessük az információkat a prompt vagy lekérdezés szerint.
Ha meg szeretné tanulni a VectorStoreRetrieverMemory használatának folyamatát a LangChainben, egyszerűen kövesse az alábbi útmutatót:
1. lépés: Modulok telepítése
Indítsa el a memória-visszakereső használatának folyamatát a LangChain telepítésével a pip paranccsal:
pip install langchain
Telepítse a FAISS modulokat az adatok lekéréséhez a szemantikai hasonlósági keresés segítségével:
pip telepítse a faiss-gpu-t 
Telepítse a chromadb modult a Chroma adatbázis használatához. Vektortárként működik a retriever memóriájának felépítéséhez:
pip install chromadb 
Egy másik tiktoken modul telepítése szükséges, amely felhasználható tokenek létrehozására az adatok kisebb darabokra való konvertálásával:
pip install tiktoken 
Telepítse az OpenAI modult, hogy a könyvtárait LLM-ek vagy chatbotok létrehozására használja a környezet használatával:
pip install openai 
Állítsa be a környezetet Python IDE-n vagy notebookon az OpenAI-fiók API-kulcsával:
import teimport getpass
te . hozzávetőlegesen, körülbelül [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API kulcs:' )
2. lépés: Könyvtárak importálása
A következő lépés a könyvtárak beszerzése ezekből a modulokból a memória-visszakereső használatához a LangChainben:
tól től langchain. felszólítja import PromptTemplatetól től dátum idő import dátum idő
tól től langchain. llms import OpenAI
tól től langchain. beágyazások . openai import OpenAIEMbeddings
tól től langchain. láncok import Beszélgetési lánc
tól től langchain. memória import VectorStoreRetrieverMemory
3. lépés: A Vector Store inicializálása
Ez az útmutató a Chroma adatbázist használja a FAISS könyvtár importálása után az adatok kinyerésére a bemeneti paranccsal:
import faisstól től langchain. orvosi boltban import InMemoryDocstore
#könyvtárak importálása az adatbázisok vagy vektortárolók konfigurálásához
tól től langchain. vektortárak import FAISS
#hozzon létre beágyazásokat és szövegeket, hogy tárolja őket a vektortárolókban
beágyazási_méret = 1536
index = faiss. IndexFlatL2 ( beágyazási_méret )
beágyazás_fn = OpenAIEMbeddings ( ) . embed_query
vektortár = FAISS ( beágyazás_fn , index , InMemoryDocstore ( { } ) , { } )
4. lépés: Retriever építése Vector Store által támogatott
Építsd fel a memóriát a beszélgetés legfrissebb üzeneteinek tárolására, valamint a csevegés kontextusának lekérésére:
vizsla = vektortár. mint_retriever ( search_kwargs = diktálja ( k = 1 ) )memória = VectorStoreRetrieverMemory ( vizsla = vizsla )
memória. save_context ( { 'bemenet' : 'Szeretek pizzát enni' } , { 'Kimenet' : 'fantasztikus' } )
memória. save_context ( { 'bemenet' : 'Jó vagyok a fociban' } , { 'Kimenet' : 'rendben' } )
memória. save_context ( { 'bemenet' : 'Nem szeretem a politikát' } , { 'Kimenet' : 'biztos' } )
Tesztelje a modell memóriáját a felhasználó által az előzményeket tartalmazó bemenet segítségével:
nyomtatás ( memória. load_memory_variables ( { 'gyors' : 'milyen sportot nézzek?' } ) [ 'történelem' ] ) 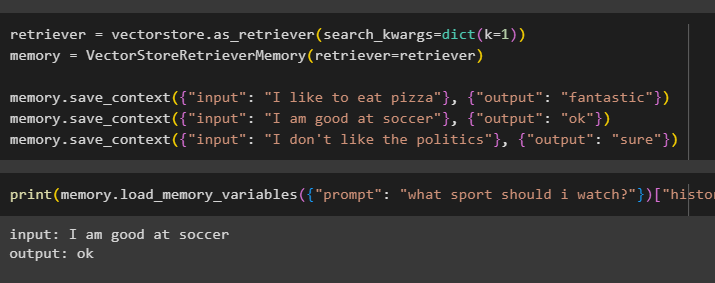
5. lépés: Retriever használata láncban
A következő lépés egy memória-visszakereső használata a láncokkal az LLM OpenAI() metódussal történő felépítésével és a prompt sablon konfigurálásával:
llm = OpenAI ( hőfok = 0 )_DEFAULT_TEMPLATE = '''Ember és gép interakciója
A rendszer a kontextus felhasználásával hasznos információkat állít elő részletekkel
Ha a rendszer nem tudja meg a választ, egyszerűen azt mondja, hogy nincs válaszom
Fontos információk a beszélgetésből:
{történelem}
(ha a szöveg nem releváns, ne használja)
Jelenlegi chat:
Ember: {input}
AI: '''
GYORS = PromptTemplate (
bemeneti_változók = [ 'történelem' , 'bemenet' ] , sablon = _DEFAULT_TEMPLATE
)
#configure a ConversationChain()-t a paraméterei értékeinek használatával
beszélgetés_összefoglalóval = Beszélgetési lánc (
llm = llm ,
gyors = GYORS ,
memória = memória ,
bőbeszédű = Igaz
)
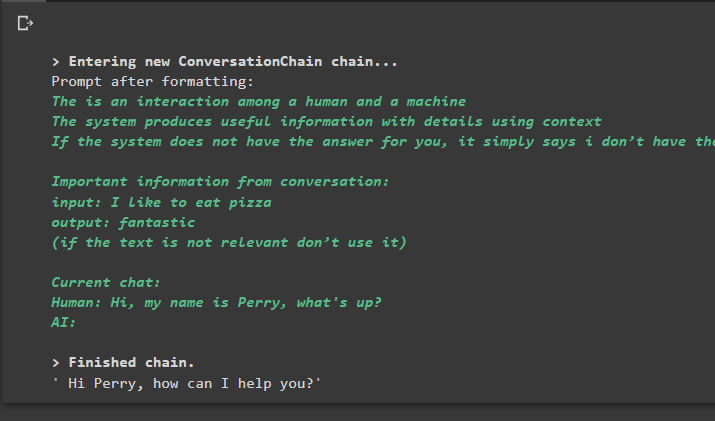
beszélgetés_összefoglalóval. megjósolni ( bemenet = 'Szia, a nevem Perry, mi újság?' )
Kimenet
A parancs végrehajtása elindítja a láncot, és megjeleníti a modell vagy az LLM által adott választ:
Folytassa a beszélgetést a vektortárban tárolt adatokon alapuló prompt használatával:
beszélgetés_összefoglalóval. megjósolni ( bemenet = 'mi a kedvenc sportom?' ) 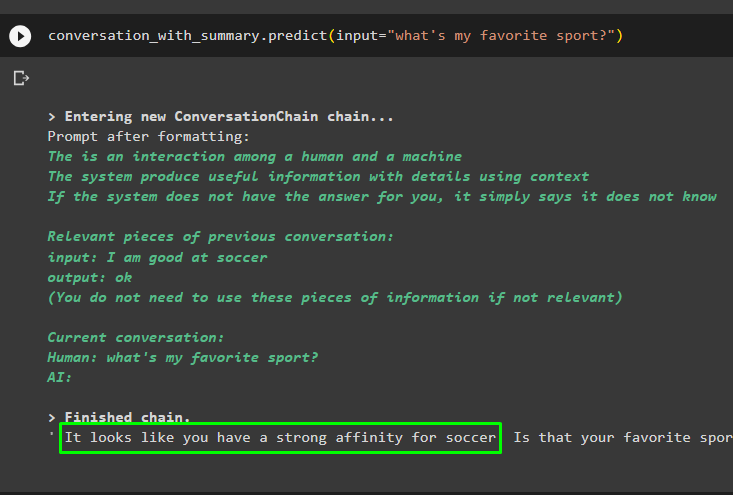
A korábbi üzenetek a modell memóriájában tárolódnak, amelyet a modell felhasználhat az üzenet kontextusának megértésére:
beszélgetés_összefoglalóval. megjósolni ( bemenet = 'Mi a kedvenc ételem' ) 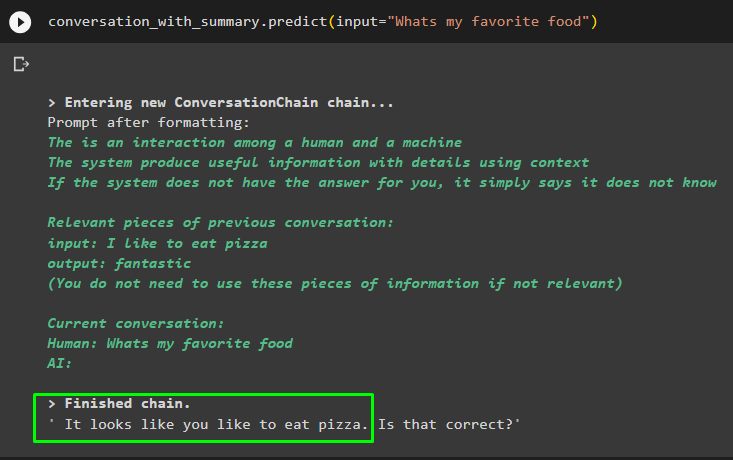
Olvassa el a modellre adott választ az előző üzenetek egyikében, hogy ellenőrizze, hogyan működik a memória-visszakereső a csevegési modellel:
beszélgetés_összefoglalóval. megjósolni ( bemenet = 'Mi a nevem?' )A modell helyesen jelenítette meg a kimenetet a memóriában tárolt adatok hasonlósági keresésével:
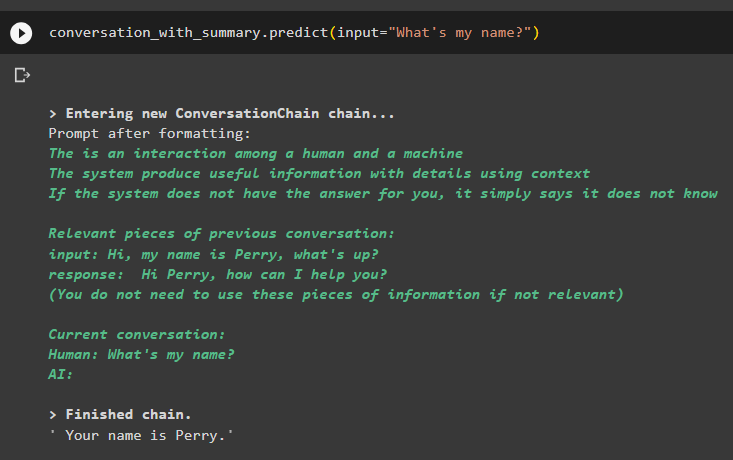
Ez minden a vektortároló retriever használatáról szól a LangChainben.
Következtetés
A LangChain vektortárolóján alapuló memória-visszakereső használatához egyszerűen telepítse a modulokat és a keretrendszereket, és állítsa be a környezetet. Ezt követően importálja a könyvtárakat a modulokból az adatbázis Chroma használatával való felépítéséhez, majd állítsa be a prompt sablont. Tesztelje a retrievert az adatok memóriában való tárolása után a beszélgetés kezdeményezésével és az előző üzenetekhez kapcsolódó kérdések feltevésével. Ez az útmutató részletesen bemutatja a VectorStoreRetrieverMemory könyvtár LangChainben való használatának folyamatát.