Az R-ben az oszlopok számának megszerzése alapvető művelet, amelyre sok esetben szükség van a DataFrames-ekkel való munka során. Az adatok részhalmaza, elemzése, manipulálása, közzététele és megjelenítése során az oszlopok száma kulcsfontosságú tudnivaló. Ezért az R különböző megközelítéseket kínál a megadott DataFrame oszlopainak összegének kiszámításához. Ebben a cikkben bemutatunk néhány olyan megközelítést, amelyek segítenek a DataFrame oszlopainak számának meghatározásában.
1. példa: Az Ncol() függvény használata
Az ncol() a leggyakrabban használt függvény a DataFrames oszlopok összegének lekérésére.
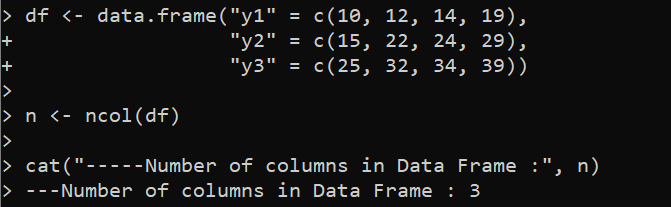
df <- data.frame('y1' = c(10, 12, 14, 19),
'y2' = c(15, 22, 24, 29),
'y3' = c(25, 32, 34, 39))
n <- ncol(df)
cat('-----Oszlopok száma az adatkeretben :', n)
Ebben a példában először létrehozunk egy „df” DataFrame-et három oszlopból, amelyek „y1”, „y2” és „y3” címkével vannak ellátva az R-ben található data.frame() függvény használatával. Az egyes oszlopok elemei a következővel vannak megadva. a c() függvény, amely elemvektort hoz létre. Ezután az „n” változó használatával az ncol() függvényt használjuk a „df” DataFrame oszlopok összességének meghatározására. Végül a leíró üzenettel és az „n” változóval a megadott cat() függvény kinyomtatja az eredményeket a konzolon.
Ahogy az várható volt, a letöltött kimenet azt jelzi, hogy a megadott DataFrame-nek három oszlopa van:
2. példa: Számolja meg az üres adatkeret összes oszlopát
Ezután az ncol() függvényt alkalmazzuk az üres DataFrame-re, amely szintén megkapja az összes oszlop értékét, de ez az érték nulla.
üres_df <- data.frame()n <- ncol(üres_df)
cat('---Oszlopok az adatkeretben :', n)
Ebben a példában az üres DataFrame-et ('empty_df') állítjuk elő a data.frame() meghívásával, oszlopok vagy sorok megadása nélkül. Ezután az ncol() függvényt használjuk, amely a DataFrame oszlopok számának meghatározására szolgál. Az ncol() függvény az „empty_df” DataFrame-mel van beállítva, hogy megkapja az összes oszlopot. Mivel az „empty_df” DataFrame üres, nem tartalmaz oszlopokat. Tehát az ncol(empty_df) kimenete 0. Az eredményeket az itt telepített cat() függvény jeleníti meg.
A kimenet a várt módon a „0” értéket mutatja, mert a DataFrame üres.

3. példa: A Select_If() függvény használata a Length() függvénnyel
Ha egy adott típusú oszlopok számát szeretnénk lekérni, akkor a select_if() függvényt használjuk az R long() függvényével együtt. Ezeket a függvényeket kombináljuk, hogy megkapjuk az egyes típusok oszlopainak összegét. . A függvények használatához szükséges kód a következőkben valósul meg:
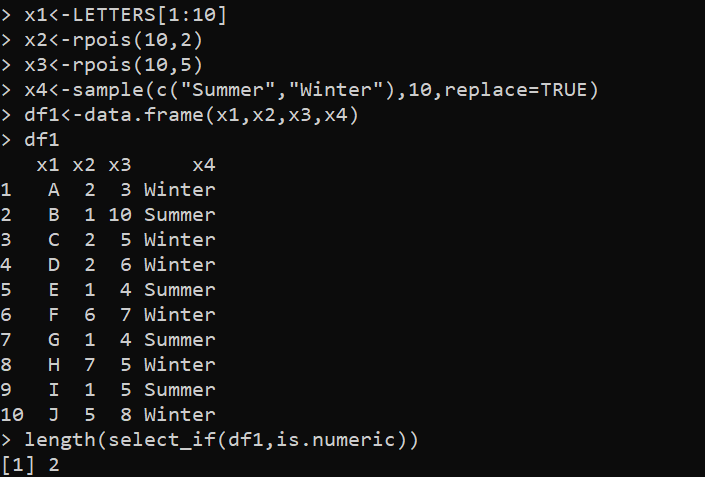
könyvtár (dplyr)x1<-LETTERS[1:10]
x2<-rpois(10,2)
x3<-rpois(10,5)
x4<-minta(c('Nyár','Tél'),10,replace=TRUE)
df1<-data.frame(x1,x2,x3,x4)
df1
hossz(select_if(df1,is.numeric))
Ebben a példában először a dplyr csomagot töltjük be, hogy elérjük a select_if() függvényt és a length() függvényt. Ezután létrehozzuk a négy változót – „x1”, „x2”, „x3” és „x4”. Itt az „x1” az angol ábécé első 10 nagybetűjét tartalmazza. Az „x2” és „x3” változókat az rpois() függvény segítségével állítjuk elő, hogy két különálló, 10 véletlenszámból álló vektort hozzunk létre 2-es, illetve 5-ös paraméterekkel. Az „x4” változó egy 10 elemből álló faktorvektor, amelyek véletlenszerűen a c vektorból vannak mintavételre („nyár”, „tél”).
Ezután megpróbáljuk létrehozni a „df1” DataFrame-et, ahol az összes változót átadjuk a data.frame() függvényben. Végül meghívjuk a length() függvényt, hogy meghatározzuk a „df1” DataFrame hosszát, amely a dplyr csomag select_if() függvényével jön létre. A select_if() függvény a „df1” DataFrame oszlopait választja ki argumentumként, az is.numeric() függvény pedig csak azokat az oszlopokat jelöli ki, amelyek számértékeket tartalmaznak. Ezután a long() függvény megkapja a select_if() által kiválasztott oszlopok összességét, amely a teljes kód kimenete.
Az oszlop hossza a következő kimeneten látható, amely a DataFrame összes oszlopát jelzi:
4. példa: A Sapply() függvény használata
Ezzel szemben, ha csak az oszlopok hiányzó értékeit akarjuk megszámolni, akkor az saply() függvényünk van. Az apply() függvény a DataFrame minden oszlopában iterál, hogy specifikusan működjön. Az apply() függvényt először a DataFrame argumentumként adja át. Ezután az adott DataFrame-en végre kell hajtani a műveletet. Az sapply() függvény megvalósítása a DataFrame oszlopokban lévő NA értékek számának lekéréséhez a következőképpen történik:
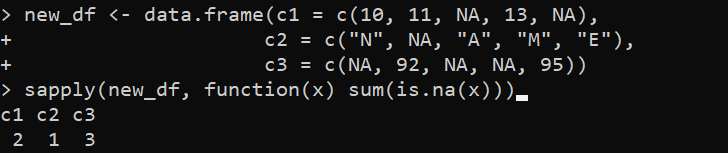
new_df <- data.frame(c1 = c(10, 11, NA, 13, NA),c2 = c('N', NA, 'A', 'M', 'E'),
c3 = c(NA, 92, NA, NA, 95))
sapply(new_df, function(x) sum(is.na(x)))
Ebben a példában létrehozzuk a „new_df” DataFrame-et három oszloppal – „c1”, „c2” és „c3”. Az első oszlopok, a „c1” és „c3”, a numerikus értékeket tartalmazzák, beleértve néhány hiányzó értéket is, amelyeket NA képvisel. A második oszlop, a „c2”, tartalmazza a karaktereket, köztük néhány hiányzó értéket, amelyet szintén NA képvisel. Ezután alkalmazzuk az saply() függvényt a „new_df” DataFrame-re, és kiszámítjuk az egyes oszlopokban a hiányzó értékek számát az saply() függvényen belüli sum() kifejezés segítségével.
Az is.na() függvény az a kifejezés, amely a sum() függvényben van megadva, és egy logikai vektort ad vissza, jelezve, hogy az oszlop minden eleme hiányzik-e vagy sem. A sum() függvény összeadja a TRUE értékeket, hogy megszámolja a hiányzó értékek számát az egyes oszlopokban.
Ezért a kimenet a teljes NA-értéket jeleníti meg az egyes oszlopokban:
5. példa: A Dim() függvény használata
Ezenkívül szeretnénk megkapni az összes oszlopot a DataFrame soraival együtt. Ezután a dim() függvény megadja a DataFrame méreteit. A dim() függvény argumentumként veszi az objektumot, amelynek a méreteit szeretnénk lekérni. Íme a kód a dim() függvény használatához:
d1 <- data.frame(team=c('t1', 't2', 't3', 't4'),pontok=c(8, 10, 7, 4))
halvány (d1)
Ebben a példában először definiáljuk a „d1” DataFrame-et, amelyet a data.frame() függvény segítségével állítunk elő, ahol két oszlop van beállítva: „team” és „points”. Ezt követően meghívjuk a dim() függvényt a „d1” DataFrame-en keresztül. A dim() függvény a DataFrame sorainak és oszlopainak számát adja vissza. Ezért a dim(d1) futtatásakor egy két elemből álló vektort ad vissza – amelyek közül az első a „d1” DataFrame-ben lévő sorok számát tükrözi, a második pedig az oszlopok számát.
A kimenet a DataFrame méreteit jelöli, ahol a „4” az összes oszlopot, a „2” pedig a sorokat jelöli:

Következtetés
Most megtudtuk, hogy az R oszlopok számának megszámlálása egy egyszerű és fontos művelet, amelyet a DataFrame-en lehet végrehajtani. Az összes függvény közül az ncol() függvény a legkényelmesebb módja. Most már ismerjük a különböző módokat, hogy az adott DataFrame-ből hány oszlopot kapjunk.