„A „pandák”-ban a „panda” metódus segítségével könnyen beolvashatjuk a szöveges fájlt. A „Pandas” lehetőséget biztosít számunkra a szövegfájl olvasására. A „Pandas” különféle beépített módszereket ad a szövegfájl olvasásához. Ebben az oktatóanyagban az összes módszert megvitatjuk az összes paraméterrel együtt, és részletesen elmagyarázzuk őket. Ezenkívül a „pandák” szövegfájlt is be fogjuk olvasni az itt található „panda” metódusok használatával.
A szöveges fájl olvasásának módszerei „pandákban”
A „pandákban” három módszerünk van, amelyek segítenek a szövegfájl olvasásakor. Néhány példát is készítettünk itt, amelyekben a szövegfájlt olvastuk. A „pandák” által kínált módszereket az alábbiakban tárgyaljuk:
-
- A pd.read_csv() metódus használatával.
- A pd.read_table() metódus használatával.
- A pd.read_fwf() metódus használatával.
Most elmagyarázzuk mindezen módszerek szintaxisát, és részletesen megvitatjuk az összes módszer paramétereit ebben az oktatóanyagban.
A read_csv() szintaxisa
pd.read_csv ( 'fájlnév.txt', szept ='', fejléc = Nincs, neveket = [ „Col_name1”, „Col_name2”, „Col_name2”, ………….. ] )
Ennél a metódusnál először annak a szöveges fájlnak a nevét adjuk hozzá, amelynek az adatait ki szeretnénk olvasni, és ez a metódus első paramétere. Ezután helyezzük el a „sep”-et, amely ebben a módszerben elválasztó, és itt helyezzük el a szóközt karakterként, így a szóközt fogja elválasztónak tekinteni. Ezek után megvan a fejléc paraméter, és ennek a paraméternek a „Nincs” értéke kerül felhasználásra, így létrehozza az alapértelmezett fejlécet, és ha nem adjuk hozzá, akkor a szövegfájl első sorát veszi figyelembe. mint a fejléc. A „names” paraméterben felvehetjük az oszlopneveket, amelyeket fejlécként kell hozzáadnunk.
A read_table() szintaxisa
pd.read_table ( 'fájlnév.txt' , határoló = '' )
Ebben a módszerben a szövegfájl fájlnevét adjuk meg első paraméterként. Ha a határolóban „ ”-t teszünk, akkor a szóköz karaktert fogja használni elválasztóként.
A read_fwf() szintaxisa
pd.read_fwf ( 'fájlnév.txt' )
Ez a módszer csak egy paramétert vesz igénybe, ez a szövegfájl neve.
Most ezeket a módszereket fogjuk használni a „pandas” kódokban lévő szövegfájlok olvasására és a szövegfájl adatainak a terminálon való megjelenítésére.
Példa # 01
Itt található a „Spyder” alkalmazás, amelyben elvégeztük az oktatóanyagban bemutatott összes kódot. Az alábbiakban látható az a szövegfájl, amelynek adatait ki szeretnénk olvasni. A „read_csv()” metódust fogjuk használni ennek a szöveges fájlnak a „pandas” nyelven történő olvasásához.
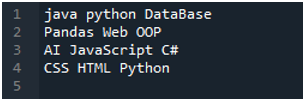
Először a „pandas” könyvtárat importáljuk, mert a „read_csv()” metódust akarjuk használni, és ez a „pandas” metódusa. Ezt a módszert csak akkor érjük el, ha importáltuk a „pandák” könyvtárát. Itt a „pandas pd-ként” említjük, ezért ez a „pd” a használatához használt metódus nevével együtt kerül elhelyezésre. Ezek után itt létrehozunk egy „df” változót, amely a szöveges fájl adatainak tárolására szolgál kiolvasás után. Ide helyezzük a „pd.read_csv()” metódust, amely segít a szövegfájl beolvasásában és a szöveges fájl adatainak DataFrame-be való konvertálásában és a „df” változóban való tárolásában.
Itt átadtuk a fájlnevet, ami „sajatAdat.txt”, majd a „sep”-t használjuk, és ehhez a „sep”-hez rendeljük az üres karaktert. Tehát ez az üres karakter elválasztóként működik a szövegfájlban. Ezután az alábbi „print()”-et használtuk, amely a szöveges fájl adatainak kinyomtatására szolgál. A szöveges fájl adatait DataFrame formában jeleníti meg.
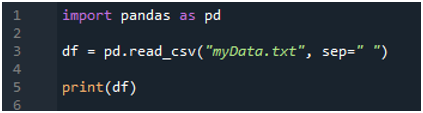
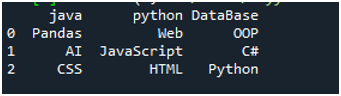
A kód végrehajtásához le kell nyomnunk a „Shift+Enter” billentyűket, és a kimenet a „Spyder’s” terminálon jelenik meg. A fenti kód eredménye az adott képernyőképen jelenik meg, és látható, hogy a szöveges fájl adatai DataFrame-ként, a szöveges fájlunk első sora pedig az adott DataFrame oszlopneveiként jelennek meg. Ezenkívül elválasztja azokat az adatokat, ahol a szóköz szerepel a szövegfájlban.
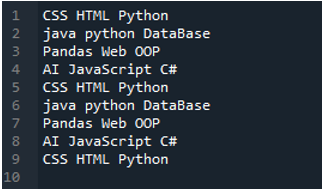
02. példa
Itt látható a szövegfájl, amelyet ebben a példában olvasunk, és ismét a „read_csv()” metódust fogjuk használni, de más paraméterekkel.
A „pd.read_csv()” „pandas” metódust használjuk, és itt három paramétert adunk át. Először elhelyezzük a fájlnevet, ami „Record.txt”. A második paraméter a 'sep' paraméter és hozzárendeli az üres karaktert, majd a harmadik paraméterünk van, amiben beállítjuk a 'fejlécet' és 'Nincs'-re állítjuk, így ez hozza létre a DataFrame alapértelmezett fejlécét. amikor ezt a kódot végrehajtjuk. Mindezt a „My_Record” változóba mentettük, és a „print()” függvénybe a „My_Record”-ot is hozzáadtuk a nyomtatáshoz.

Minden adat a DataFrame-be kerül mentésre, és elválasztja azokat az adatokat, ahol a szóköz szerepel a szövegfájl adataiban. Ezenkívül itt hozta létre a DataFrame alapértelmezett fejlécét, mivel a „fejléc” paramétert „Nincs” értékre állítottuk.
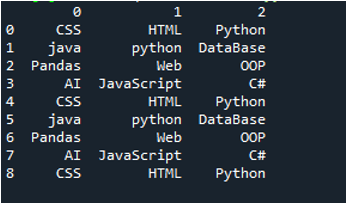
03. példa
Megjelenik a példa szöveges fájlja, és ismét a „read_csv()” metódust használjuk módosított paraméterekkel.
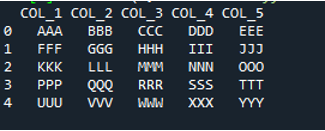
Ebben a kódban négy paramétert adunk át a „pandas” metódusnak, a „pd.read_csv()”. A szövegfájl neve az első paraméter. A „sep” paraméter üres karaktert kap a második paraméterben. A harmadik argumentumban a „header” paraméter „None”-ra van állítva, negyedik paraméterként pedig a „names”-et állítottuk be, amelyek a DataFrame oszlopneveiként jelennek meg a szöveges fájl elolvasása után, és ezek az oszlopnevek „COL_1, COL_2, COL_3, COL_4 és COL_5”. Mindezek az információk a „My_Record” változóba kerültek, és a „My_Record” is hozzá lett adva a „print()” metódushoz, így az ki fog nyomtatni a terminálon.

A szöveges fájl összes információja itt DataFrame-ként jelenik meg, és különválasztja azokat az adatokat, ahol a szövegfájlban szóközök vannak hozzáadva. Ennek megfelelően hozzáadja az oszlopneveket is, amelyeket fentebb hozzáadtunk a kódhoz.
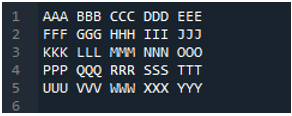
04. példa
Ez az a szövegfájl, amelyet ebben a példában egy másik módszer, a „pd.read_table()” metódus használatával fogunk olvasni.
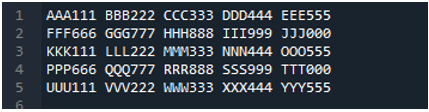
A „pd.read_table()” metódus hozzáadásra kerül a szövegfájl olvasásához, és hozzáadjuk az „ABC.txt”-t, amely a szövegfájl neve. Ez a módszer segít a szöveges fájl beolvasásában, valamint a „határoló” paramétert a szóköz karakterre állítottuk, így az elválasztóhoz hasonlóan fog működni, amit fentebb ismertettünk. Ezután a szöveges fájl összes adata a „My_Data” változóba kerül, és ide is kinyomtatható.

Szövegfájlunk kezdősora itt a DataFrame oszlopneveiként jelenik meg, a szövegfájl adatai pedig DataFrame-ként kerülnek kinyomtatásra. Ezenkívül elválasztja a szövegfájl adatait, ahol a szóköz van benne.
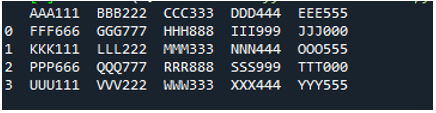
05. példa
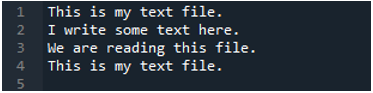
Most a szöveges fájl tartalmazza az adatokat, amelyek lent láthatók. Ezúttal a „read_fwf()”-t alkalmazzuk, és megmutatjuk, hogyan jeleníti meg az adatokat a szövegfájl elolvasása után.
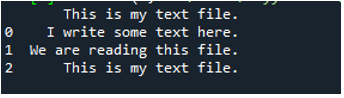
Mint tudjuk, ez a 'read_fwf()' metódus csak egy paramétert vesz igénybe, ez az a fájlnév, amelyet olvasni akarunk. Ide hozzáadjuk a „textfile.txt”-t, ami a szövegfájlunk neve, és ezt a pandas metódust hozzárendeljük a „File_Data” változóhoz, amely ennek a szöveges fájlnak az adatait tárolja. Ezután betesszük a „print(File_Data)” parancsot, így ki is nyomtatja ezeket az adatokat.

Itt a szöveges fájl összes adata látható. Nem választotta el azokat az adatokat, ahol szóköz van, mert ebben a függvényben nincs olyan paraméter, mint a „Sep” vagy a „határoló”.
Következtetés
Ez az oktatóanyag elmagyarázza, hogyan kell olvasni a szövegfájlt „pandákban”, és hogy milyen módszereket használunk a szövegfájl olvasásához „pandában”. Megbeszéltünk minden olyan módszert, amely segít a szövegfájl „pandákban” történő olvasásakor. Ebben az oktatóanyagban a „pandák” három különböző módszerét vizsgáltuk meg szövegfájljaink „pandában” történő olvasásához. Itt részletesen elmagyaráztuk az összes metódus szintaxisát, valamint az összes metódus paramétereit, és számos szövegfájlt elolvastunk, különböző módszereket alkalmazva az összes lehetséges paraméterrel ebben az oktatóanyagban.