Szintaxis
df [ ( cond_1 ) & ( cond_2 ) ]01. példa
Ezeket a kódokat a „Spyder” alkalmazásban végezzük, és az „AND” operátort használjuk az itteni „pandák” feltételeiben. Miközben a pandák kódjait készítjük, először importálnunk kell a „pandákat pd-ként”, és a metódusát úgy kapjuk meg, hogy csak „pd”-t teszünk a kódunkba. Ezután létrehozunk egy szótárt „Cond” néven, és az itt beszúrt adatok az „A1”, „A2” és „A3” az oszlopnevek, és hozzáadjuk az „1, 2 és 3”-at a „ A1”, az „A2”-ban „2, 6 és 4”, az utolsó „A3” pedig „3, 4 és 5”-et tartalmaz.
Ezután a szótár DataFrame-jét készítjük el a „pd.DataFrame” használatával. Ez visszaadja a fenti szótári adatok DataFrame-jét. Itt is megjelenítjük a „print ()” megadásával, majd ezt követően bizonyos feltételeket alkalmazunk, és ebben a feltételben használjuk az „&” operátort is. Az első feltétel itt az, hogy „A1 >= 1”, majd betesszük az „&” operátort és egy másik feltételt, amely „A2 < 5”. Amikor ezt végrehajtjuk, akkor az eredményt adja vissza, ha „A1 >=1” és „A2 < 5” is. Ha itt mindkét feltétel teljesül, akkor az eredményt jeleníti meg, ha pedig itt valamelyik nem teljesül, akkor nem jelenít meg semmilyen adatot.
Ellenőrzi a DataFrame „A1” és „A2” oszlopát, majd visszaadja az eredményt. Az eredmény megjelenik a képernyőn, mert a „print ()” utasítást használjuk.
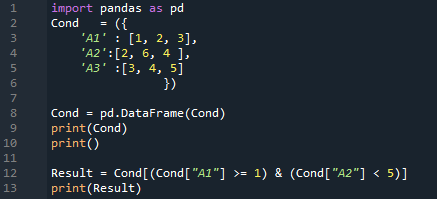
Az eredmény itt van. Megjeleníti az összes adatot, amelyet beszúrtunk a DataFrame-be, majd mindkét feltételt ellenőrzi. Azokat a sorokat adja vissza, amelyekben „A1 >=1” és „A2 < 5”. Ebben a kimenetben két sort kapunk, mert két sorban mindkét feltétel teljesül.
02. példa
Ebben a példában közvetlenül hozzuk létre a DataFrame-et a „pandas pd-ként” importálása után. Itt jön létre a „Team” DataFrame, amelyben az adatok négy oszlopot tartalmaznak. Az első oszlop itt a „csapatok” oszlop, amelybe az „A, A, B, B, B, B, C, C”-t tesszük. Ezután a „csapatok” melletti oszlop a „pontszám”, amelybe beszúrjuk a „25, 12, 15, 14, 19, 23, 25 és 29” számokat. Ezek után a rendelkezésünkre álló oszlop a „Ki”, és ehhez adunk hozzá adatokat „5, 7, 7, 9, 12, 9, 9 és 4”-ként. Utolsó oszlopunk itt a „lepattanók” oszlop, amely néhány numerikus adatot is tartalmaz, azaz „11, 8, 10, 6, 6, 5, 9 és 12”.
A DataFrame itt elkészült, és most ezt a DataFrame-et kell kinyomtatnunk, ezért ehhez itt helyezzük el a „print ()”-t. Néhány konkrét adatot szeretnénk beszerezni ebből a DataFrame-ből, ezért itt szabunk meg néhány feltételt. Itt két feltételünk van, és ezek közé adjuk az „ÉS” operátort, így csak azokat a feltételeket adja vissza, amelyek mindkét feltételnek megfelelnek. Az első feltétel, amelyet itt hozzáadtunk, a „pontszám > 20”, majd helyezze el az „&” operátort és a másik feltételt, amely az „Out == 9”.
Tehát kiszűri azokat az adatokat, ahol a csapat pontszáma kevesebb, mint 20, és a kieséseik is 9. Ezeket kiszűri, és figyelmen kívül hagyja a maradékot, amely nem felel meg mindkét feltételnek vagy egyiknek sem. Megjelenítjük azokat az adatokat is, amelyek mindkét feltételnek megfelelnek, ezért a „print ()” módszert alkalmaztuk.
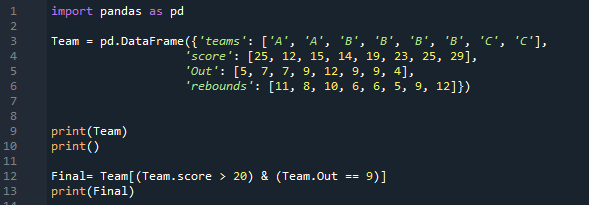
Csak két sor felel meg mindkét feltételnek, amelyeket erre a DataFrame-re alkalmaztunk. Csak azokat a sorokat szűri ki, amelyekben a pontszám nagyobb, mint 20, valamint a kimeneteik 9-esek, és itt jelenítik meg őket.
03. példa
A fenti kódjainkban csak a numerikus adatokat helyezzük be a DataFrame-ünkbe. Most néhány karakterlánc adatot helyezünk el ebbe a kódba. Miután importáltuk a „pandákat pd-ként”, egy „Member” DataFrame felépítésére lépünk. Négy egyedi oszlopot tartalmaz. Az első oszlop neve itt: „Név”, és beillesztjük a tagok nevét, amelyek a következők: „Allies, Bills, Charles, David, Ethen, George és Henry”. A következő oszlop neve „Hely” van, és az „Amerika”. Kanada, Európa, Kanada, Németország, Dubai és Kanada”. A „Kód” oszlop a „W, W, W, E, E, E és E” szavakat tartalmazza. A tagok „pontjait” is hozzáadjuk ide: „11, 6, 10, 8, 6, 5 és 12”. A „Member” DataFrame-et a „print ()” metódussal jelenítjük meg. Meghatároztunk néhány feltételt ebben a DataFrame-ben.
Itt két feltételünk van, és ha közéjük hozzáadjuk az „ÉS” operátort, akkor csak olyan feltételeket ad vissza, amelyek mindkét feltételnek megfelelnek. Itt az első bevezetett feltétel a „Location == Canada”, ezt követi az „&” operátor, és a második feltétel, a „pontok <= 9”. A DataFrame-ből megkapja azokat az adatokat, amelyekben mindkét feltétel teljesül, majd elhelyeztük a „print ()”-t, amely azokat az adatokat jeleníti meg, amelyekben mindkét feltétel igaz.
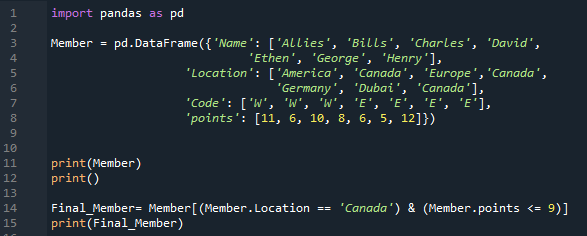
Alább láthatja, hogy a DataFrame-ből két sort nyer ki és jelenít meg. Mindkét sorban a hely „Kanada”, és a pontok kevesebb, mint 9.
04. példa
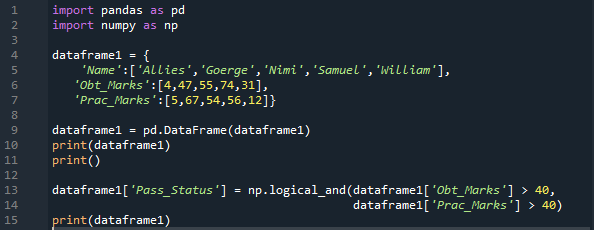
Ide importáljuk a „pandát” és a „numpy”-t is „pd” és „np” néven. A „pandas” metódusokat a „pd”, a „numpy” metódusokat pedig az „np” elhelyezésével kapjuk meg. Ekkor az itt készített szótár három oszlopot tartalmaz. A „Név” oszlopba beszúrjuk a „Szövetségesek, George, Nimi, Samuel és William” szavakat. Ezután van az „Obt_Marks” oszlop, amely a tanulók által szerzett jegyeket tartalmazza, és ezek a „4, 47, 55, 74 és 31” jegyek.
Itt is létrehozunk egy oszlopot a „Prac_Marks”-hoz, amely tartalmazza a tanuló gyakorlati jegyeit. Az általunk hozzáadott jelek: „5, 67, 54, 56 és 12”. Elkészítjük ennek a szótárnak a DataFrame-jét, majd kinyomtatjuk. Itt alkalmazzuk az „np.Logical_and”-t, amely „Igaz” vagy „Hamis” formában adja vissza az eredményt. Az eredményt mindkét feltétel ellenőrzése után egy új oszlopban is tároljuk, amit itt hoztunk létre „Pass_Status” néven.
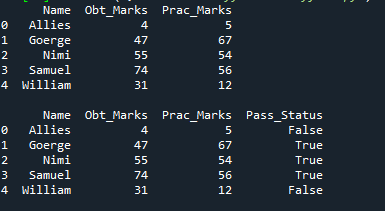
Ellenőrzi, hogy az „Obt_Marks” nagyobb-e, mint „40”, a „Prac_Marks” pedig nagyobb-e, mint „40”. Ha mindkettő igaz, akkor az új oszlopban igaz lesz; ellenkező esetben hamisat ad vissza.
Az új oszlop a „Pass_Status” névvel egészül ki, és ez az oszlop csak a „True” és „False” elemekből áll. Igaz, ahol a kapott pontszámok és a gyakorlati jegyek nagyobbak 40-nél, és hamis a többi sornál.
Következtetés
Ennek az oktatóanyagnak az a fő célja, hogy elmagyarázza az „és állapot” fogalmát a „pandákban”. Beszéltünk arról, hogyan lehet megszerezni azokat a sorokat, ahol mindkét feltétel teljesül, vagy igazat kapunk azokra is, ahol minden feltétel teljesül, és hamis a többire. Négy példát vizsgáltunk meg itt. Az oktatóanyagban bemutatott mind a négy példa végigment ezen a folyamaton. Az ebben az oktatóanyagban található példák mind átgondoltan kerültek bemutatásra az Ön javára. Ennek az oktatóanyagnak segítenie kell a gondolat pontosabb megértésében.