Hogyan működik a csoport aggregáció a MongoDB-ben?
A $group operátort kell használni a bemeneti dokumentumok csoportosítására a megadott _id kifejezés szerint. Ezután egyetlen dokumentumot kell visszaadnia az egyes csoportok összértékével. A megvalósítás kezdetén létrehoztuk a „Könyvek” gyűjteményt a MongoDB-ben. A „Könyvek” gyűjtemény létrehozása után beiktattuk azokat a dokumentumokat, amelyek a különböző mezőkhöz kapcsolódnak. A dokumentumok az insertMany() metódussal kerülnek be a gyűjteménybe, ahogy az alábbiakban látható a végrehajtandó lekérdezés.
>db.Books.insertMany([{
_id:1,
cím: 'Anna Karenina',
ár: 290,-
év: 1879,
order_status: 'Raktáron',
szerző: {
'név': 'Leo Tolsztoj'
}
},
{
_id:2,
cím: 'Kill a Mockingbird',
ár: 500,
év: 1960,
order_status: 'nincs raktáron',
szerző: {
'név': 'Harper Lee'
}
},
{
_id:3,
cím: 'Láthatatlan ember',
ár: 312,-
év: 1953,
order_status: 'Raktáron',
szerző: {
'név': 'Ralph Ellison'
}
},
{
_id:4,
cím: 'Szeretett',
ár: 370,-
év: 1873,
order_status: 'out_of_stock',
szerző: {
'név': 'Toni Morrison'
}
},
{
_id:5,
cím: 'A dolgok szétesnek',
ár: 200,
év: 1958,
order_status: 'Raktáron',
szerző: {
'név': 'Chinua Achebe'
}
},
{
_id:6,
cím: 'A lila szín',
ár: 510,-
év: 1982,
order_status: 'nincs raktáron',
szerző: {
'név': 'Alice Walker'
}
}
])
A dokumentumok sikeresen tárolódnak a „Könyvek” gyűjteményben hiba nélkül, mert a kimenet „igaz”-ként nyugtázza. Most a „Könyvek” gyűjtemény ezen dokumentumait fogjuk felhasználni a „$csoport” aggregáció végrehajtására.

1. példa: $group aggregáció használata
Itt bemutatjuk a $group aggregáció egyszerű használatát. Az összesített lekérdezés először a „$group” operátort adja meg, majd a „$group” operátor veszi át a kifejezéseket a csoportosított dokumentumok létrehozásához.
>db.Books.aggregate([
{ $group:{ _id:'$author.name'} }
])
A $group operátor fenti lekérdezése az „_id” mezővel van megadva az összes bemeneti dokumentum összértékének kiszámításához. Ezután a „_id” mezőhöz a „$author.name” tartozik, amely egy másik csoportot alkot az „_id” mezőben. A $author.name külön értékei lesznek visszaadva, mert nem számítunk ki semmilyen halmozott értéket. A $group aggregate lekérdezés végrehajtása a következő kimenettel rendelkezik. Az _id mező a author.names értékeit tartalmazza.

2. példa: $group aggregáció használata a $push Akkumulátorral
A $group aggregáció példája minden fentebb említett gyűjtőt használ. De használhatjuk az akkumulátorokat a $group aggregációban. Az akkumulátor-operátorok azok, amelyeket a beviteli dokumentummezőkben használnak, kivéve azokat, amelyek „_id” alatt vannak „csoportosítva”. Tegyük fel, hogy a kifejezés mezőit egy tömbbe szeretnénk tolni, majd a „$push” akkumulátort a „$group” operátor hívja elő. A példa segít jobban megérteni a „$csoport” „$push” akkumulátorát.
>db.Books.aggregate([
{ $group : { _id : '$_id', év: { $push: '$year' } } }
]
).szép();
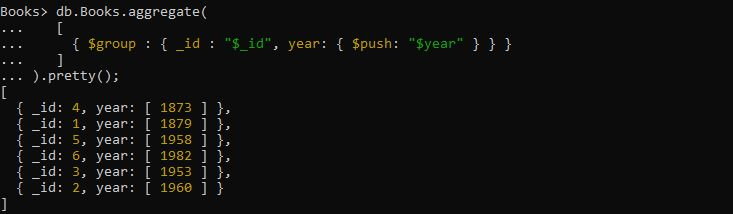
Itt szeretnénk csoportosítani a tömbben az adott könyvek kiadási évszámát. Ennek megvalósításához a fenti lekérdezést kell alkalmazni. Az összesítési lekérdezés egy olyan kifejezéssel van ellátva, ahol a „$group” operátor a „_id” mezőkifejezést és az „év” mezőkifejezést veszi fel, hogy megkapja a csoport évét a $push akkumulátor használatával. Az ebből a konkrét lekérdezésből leolvasott kimenet létrehozza az évmezők tömbjét, és abban tárolja a visszaküldött csoportosított dokumentumot.
3. példa: $group aggregáció használata a „$min” akkumulátorral
Ezután megkapjuk a „$min” gyűjtőt, amelyet a $group összesítésben használunk, hogy a gyűjtemény minden dokumentumából megkapjuk a minimális egyező értéket. A $min akkumulátor lekérdezési kifejezése alább látható.
>db.Books.aggregate([{
$group:{
_id:{
cím: '$title',
order_status: '$order_status'
},
minPrice:{$min: '$price'}
}
}
])
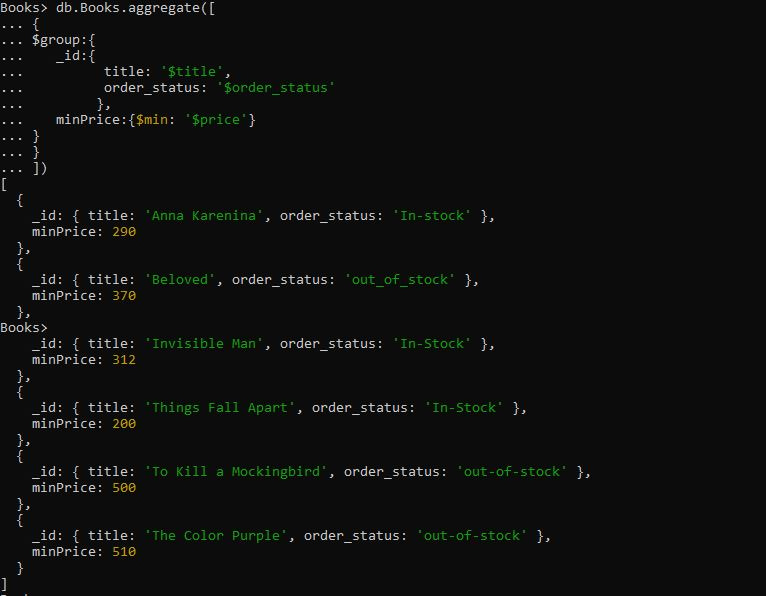
A lekérdezés tartalmazza a „$group” összesítő kifejezést, ahol a „title” és „order_status” mezőkhöz csoportosítottuk a dokumentumot. Ezután megadtuk a $min gyűjtőt, amely csoportosította a dokumentumokat úgy, hogy a minimális árértékeket a nem csoportosított mezőkből kapta meg. Amikor az alábbi $min akkumulátor lekérdezést futtatjuk, akkor a cím és a order_status alapján csoportosított dokumentumokat adja vissza sorrendben. A minimális ár jelenik meg először, a dokumentum legmagasabb ára pedig az utolsó helyen.
4. példa: Használja a $group aggregációt a $sum Akkumulátorral
Az összes numerikus mező összegének kiszámításához a $group operátor használatával a $sum akkumulátor művelet kerül telepítésre. A gyűjteményekben lévő nem numerikus értékeket ez az akkumulátor veszi figyelembe. Ezenkívül itt a $match aggregációt használjuk a $group aggregációval. A $match összesítés elfogadja a dokumentumban megadott lekérdezési feltételeket, és átadja az egyező dokumentumot a $group aggregációnak, amely azután visszaadja az egyes csoportok dokumentumának összegét. A $sum akkumulátor esetében a lekérdezés az alábbiakban látható.
>db.Books.aggregate([{ $match:{ order_status:'Raktáron'}},
{ $group:{ _id:'$author.name', totalBooks: { $sum:1 } }
}])
A fenti összesítési lekérdezés a $match operátorral kezdődik, amely megfelel az összes „order_status”-nak, amelynek állapota „Raktáron”, és bemenetként kerül át a $csoportba. Ezután a $group operátor rendelkezik a $sum akkumulátor kifejezéssel, amely a készletben lévő összes könyv összegét adja ki. Vegye figyelembe, hogy a „$sum:1” 1-et ad minden olyan dokumentumhoz, amely ugyanabba a csoportba tartozik. A kimenet itt csak két olyan csoportosított dokumentumot jelenített meg, amelyeknél az „order_status” a „Raktáron”-hoz van társítva.

5. példa: Használja a $group aggregációt a $sort aggregációval
A $group operátor itt a „$sort” operátorral együtt használatos, amely a csoportosított dokumentumok rendezésére szolgál. A következő lekérdezés három lépésből áll a rendezési művelethez. Először a $match szakasz, majd a $group szakasz, az utolsó pedig a $sort szakasz, amely a csoportosított dokumentumot rendezi.
>db.Books.aggregate([{ $match:{ order_status:'out-of-stock'}},
{ $group:{ _id:{ authorName :'$author.name'}, totalBooks: { $sum:1} } },
{ $sort:{ szerzőnév:1}}
])
Itt letöltöttük az egyező dokumentumot, amelynek az „order_status” elfogyott. Ezután az egyező dokumentumot be kell vinni a $group szakaszba, amely a dokumentumot az „authorName” és a „totalBooks” mezőkkel csoportosította. A $group kifejezés a $sum akkumulátorhoz van társítva a „kifogyott” könyvek teljes számához. A csoportosított dokumentumokat a rendszer a $sort kifejezéssel növekvő sorrendbe rendezi, mivel az „1” itt a növekvő sorrendet jelzi. A megadott sorrendben rendezett csoportbizonylatot a következő kimenetben kapjuk meg.

6. példa: Használja a $group aggregációt a megkülönböztető értékhez
Az összesítési eljárás a dokumentumokat tételenként is csoportosítja a $group operátor segítségével a különálló tételértékek kinyeréséhez. Nézzük meg ennek az utasításnak a lekérdezési kifejezését a MongoDB-ben.
>db.Books.aggregate( [ { $group : { _id : '$title' } } ] ).pretty();Az összesítési lekérdezést a rendszer a Könyvek gyűjteményre alkalmazza, hogy megkapja a csoportdokumentum egyedi értékét. A $csoport itt az _id kifejezést veszi, amely a különböző értékeket adja ki, ahogyan bevittük a „title” mezőt. A csoportdokumentum kimenete ennek a lekérdezésnek a futtatásakor érhető el, amely a címnevek csoportját az _id mezőben tartalmazza.

Következtetés
Az útmutató célja a $group aggregációs operátor fogalmának tisztázása a dokumentumok MongoDB adatbázisban való csoportosításához. A MongoDB aggregált megközelítés javítja a csoportosítási jelenségeket. A $group operátor szintaktikai felépítését a példaprogramok mutatják be. A $group operátorok alappéldáján kívül ezt az operátort is alkalmaztuk néhány gyűjtővel, mint például $push, $min, $sum, és olyan operátorokkal, mint a $match és $sort.