Naponta hatalmas számban gyűjtenek adatokat, és a big data kezelése az Elasticsearch motor legfontosabb használati esete. Az adatok valós időben tárolódnak az analitikai adatbázisban, és a felhasználó lekérdezések segítségével adatokat nyerhet ki, hogy hasznos ismereteket szerezzen belőlük. A felhasználó lekérdezéseket alkalmazhat több indexből származó adatok megkeresésére, és a relációs adatbázis egyetlen vödörében való megjelenítésére.
Ez az útmutató elmagyarázza az Elasticsearch aggregációkat különböző aggregációkat használó példákkal.
Mi az az Elasticsearch aggregáció?
Az Elasticsearch alkalmazásban az aggregáció a mezők kombinálásának vagy csoportosításának folyamata, hogy információkat nyerjünk ki a relációs adatbázisból. Az Elasticsearch-beli aggregációt úgy tekinthetjük, mint a CSOPORTOSÍTÁS ZÁRADÉK SZERINT vagy ÖSSZESÍTÉS() függvény SQL nyelven.
Hogyan használjuk az Elasticsearch aggregációt?
Az Elasticsearch összesítésének használatához a felhasználónak alapvető ismeretekkel kell rendelkeznie az adatbázisáról. Vizsgáljuk meg a szintaxist és gyakorlati megvalósítását:
Szintaxis
Az adatbázisból való adatok megkereséséhez az Elasticsearch motorban az aggregáció szintaxisát az alábbiak szerint:
'aggs' : {'összesítés_neve' : {
'összesítés_típusa' : {
'terület' : 'document_field_name'
}
A fenti töredékek:
-
- Ez a „ aggs ” kulcsszó, amely elmagyarázza az összesítés használatát a lekérdezésben.
- A aggregáció_neve a felhasználó állítja be a szükséges információknak megfelelően.
- Ezt követően a aggregáció_típusa adatgyűjtésre szolgál.
- Az utolsó sor a terület kulcsszó, amelyet a dokumentumból származó attribútum neve követ.
1. példa: Aggregáció a Kibana mintaadatokban
Ez a rész egy példa segítségével magyarázza az aggregációt a Kibana mintaadatainak felhasználásával, először ahhoz csatlakozva. Ezután egyszerűen lépjen be a „ Fejlesztői eszközök ” keressen rá a keresősávból, és kattintson rá:
Adatok lehívása mintaadatokból
Egyszerűen használja a következő parancsot az adatok lekéréséhez a ' kibana_sample_data_logs ” index a Dev Tools konzolon:
KAP / kibana_sample_data_logs / _keresés
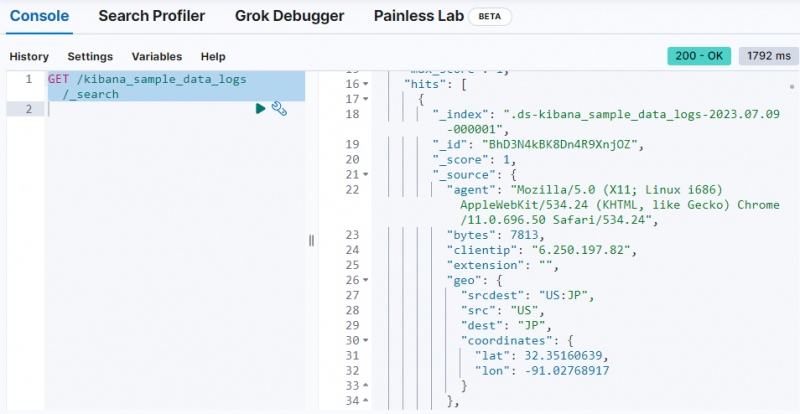
A kimenet azt mutatja, hogy az adatok a „ kibana_sample_data_logs ” index.
A következő kód a KAP kérés a ' kibana_sample_data_log ', hogy keressen belőle a value_count összesítés használatával a ' clientip ' terület:
KAP / kibana_sample_data_logs / _keresés{ 'méret' : 0 ,
'aggs' : {
'ip_count' : {
'érték_szám' : {
'terület' : 'kliens'
}
}
}
}
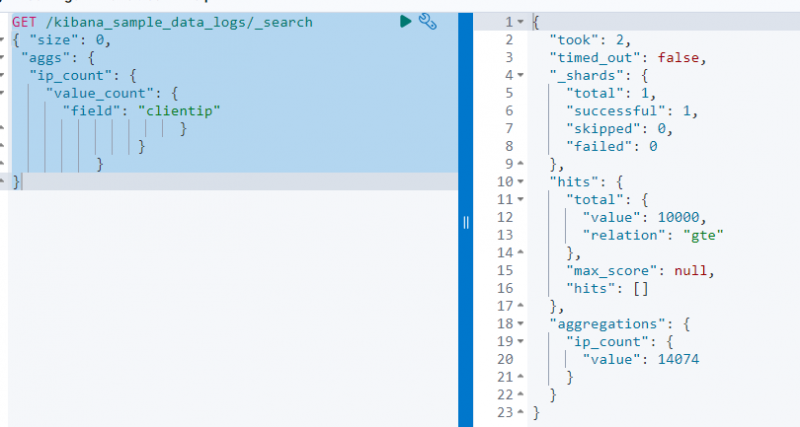
A fenti képernyőképen látható az összesítés a clientip mezőben az értékkel 14074 .
Fontos összesítések
Az alábbiakban megemlítünk néhány fontos aggregációt, amelyeket az adatok hatékony megtalálásához használnak az adatbázisból:
A következő példák a fent említett aggregációkat magyarázzák a KAP kérés a ' kibana_sample_data_ecommerce ” index:
Cardinality Aggregation
A következő kód a ' kardinalitás ' összesítés a ' sku ” mezőbe az e-kereskedelmi adatokból. Ennek a kódnak a futtatása egyértékű összesítést kap az egyedi cikkszámok beszerzéséhez az Elasticsearch adatbázisból:
KAP / kibana_sample_data_ecommerce / _keresés{
'méret' : 0 ,
'aggs' : {
'egyedi_skus' : {
'sokszínűség' : {
'terület' : 'sku'
}
}
}
}
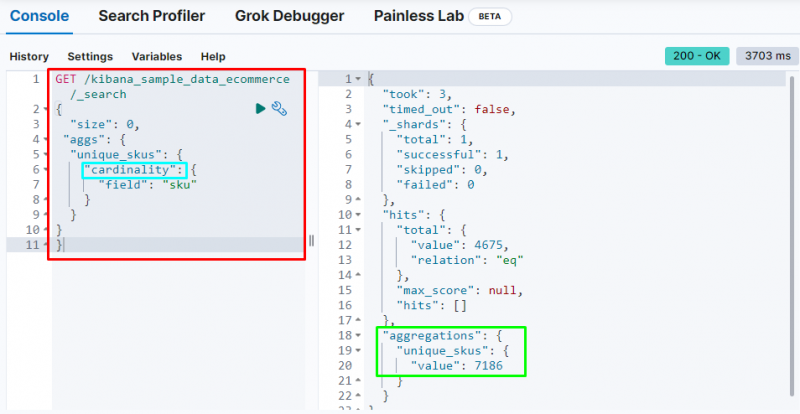
Megjeleníti a kardinalitás összesítés megtalálása a 7186 érték az indexből.
Statisztikák összesítése
Egy másik fontos aggregáció a „ statisztika ' összesítés, amelyet a ' számol ”, „ min ”, „ max ”, „ átl ”, és „ összeg ' statisztika a ' teljes mennyiség ' terület:
KAP / kibana_sample_data_ecommerce / _keresés{
'méret' : 0 ,
'aggs' : {
'mennyiség_statisztikák' : {
'statisztika' : {
'terület' : 'teljes mennyiség'
}
}
}
}
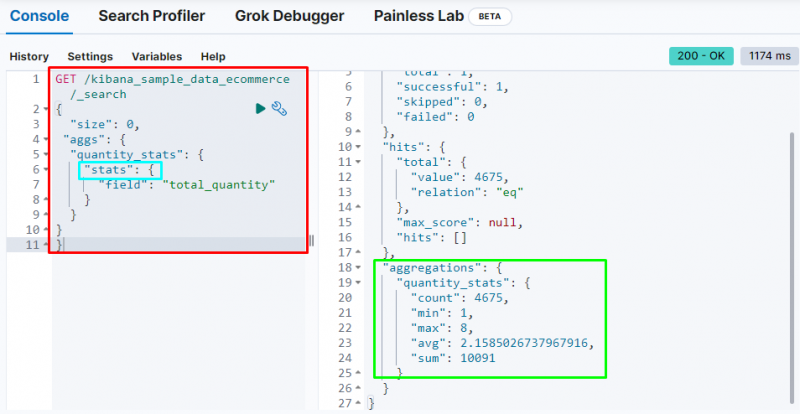
A fenti képernyőkép a statisztikát jeleníti meg a „ teljes mennyiség ' terület.
Szűrő-összesítés
A szűrőösszesítés az adatok kiszűrésére szolgál egy kifejezés vagy kifejezés alapján az adatbázisból, mivel azt a következő kód tartalmazza:
KAP / kibana_sample_data_ecommerce / _keresés{ 'méret' : 0 ,
'aggs' : {
'filter_aggregation' : {
'szűrő' : {
'kifejezés' : {
'felhasználó' : 'eddie' } } ,
'aggs' : {
'price_avg' : {
'átl.' : {
'terület' : 'termékek.ár' } }
} } } }
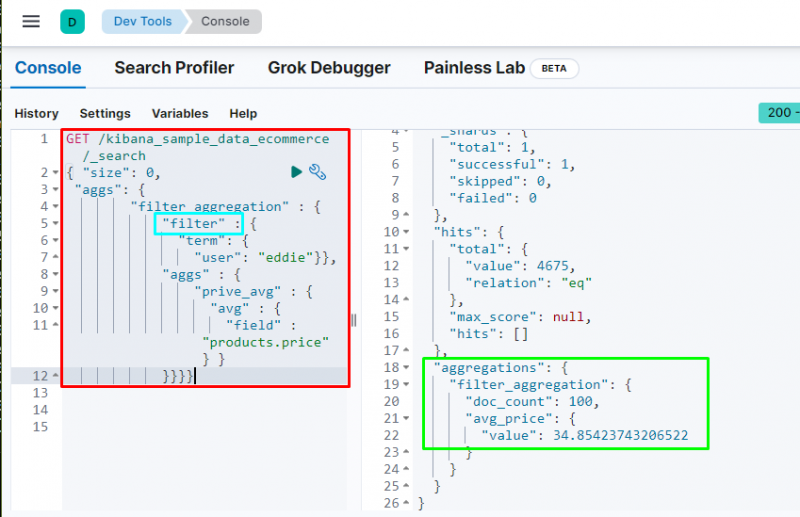
A kód végrehajtása az adatokat a „ Eddie ” felhasználót, és megjeleníti a megvásárolt cikkek átlagárát. A fenti képernyőképen látható, hogy a felhasználó talált 100 alkalommal az adatokból és a érték a átl _ ár összesítését.
Term Aggregation
Az aggregáció kifejezés létrehoz egy tárolót, és a mező adatait a tárolóban tárolja, a következő kód pedig a „ felhasználó ” mezőben tárolja adatait a vödörben:
KAP / kibana_sample_data_ecommerce / _keresés{
'méret' : 0 ,
'aggs' : {
'Term_Aggregation' : {
'feltételek' : {
'terület' : 'felhasználó'
}
}
}
}
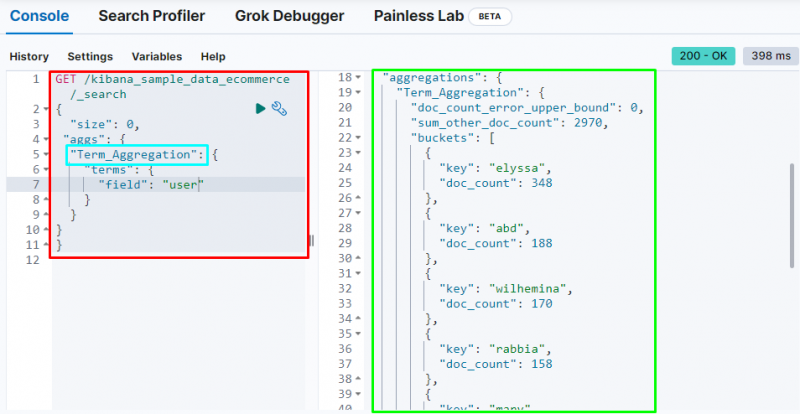
A következő képernyőképen látható, hogy az összesítés kifejezés gyűjtőcsoportokat hozott létre minden egyes felhasználó és dokumentumszáma számára.
Ez minden az Elasticsearch aggregációról és a különböző fontos összesítésről szól.
Következtetés
Az Elasticsearch alkalmazásban az összesítést arra használják, hogy adatokat kapjanak az összesített dokumentumokból, és ezeket a dokumentumokat egy adott mezőből vonják ki. Vannak olyan fontos összesítések, amelyeket arra használnak, hogy hasznos betekintést nyerjenek az indexekből. Ez az útmutató elmagyarázta az Elasticsearch aggregációt, és bemutatta az Elasticsearch aggregáció használatának folyamatát.