A File Input Stream osztálynak sokkal több módszere van, amelyek szintén nagyon hasznosak az adatok fájlból való kinyerésében; ezek egy része int read(byte[] b), ez a függvény a bemeneti adatfolyamból b.length bájt hosszúságig olvas be adatokat. A Fájlcsatorna lekéri a csatornát (): A fájl bemeneti adatfolyamhoz kapcsolódó adott Fájlcsatorna objektumot a rendszer visszaadja ennek használatával. A Finalize() segítségével biztosítható, hogy a close() függvény meghívásra kerüljön, ha már nincs hivatkozás a fájl bemeneti adatfolyamára.
01. példa: Egy bájt beolvasása szöveges fájlból a bemeneti adatfolyam osztály read() és close() metódusaival
Ez a példa a Fájlbeviteli adatfolyamot használja egyetlen karakter beolvasására és a tartalom kinyomtatására. Tegyük fel, hogy van egy „file.txt” nevű fájlunk az alábbi tartalommal:

Tegyük fel, hogy van egy „file.txt” nevű fájlunk a fenti tartalommal. Most próbáljuk meg elolvasni és kinyomtatni a fájl első karakterét.
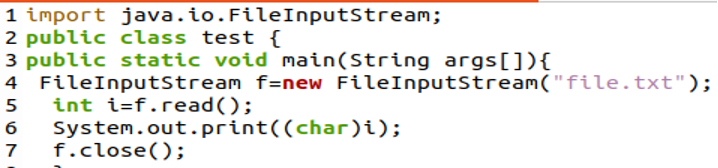
Először importálnunk kell a java.io-t. File Input Stream csomag fájlbeviteli adatfolyam létrehozásához. Ezután létrehozunk egy új File Input Stream objektumot, amely az „f” változóban megadott fájlhoz (file.txt) lesz kapcsolva.
Ebben a példában a Java File Input Stream osztály „int read()” metódusát fogjuk használni, amely egyetlen bájt beolvasására és az „I” változóba való mentésére szolgál. Ezután a „System.out.print(char(i))” megjeleníti az adott bájtnak megfelelő karaktert.
Az f.close() metódus bezárja a fájlt és az adatfolyamot. A következő kimenetet a fent említett szkript felépítése és futtatása után kapjuk, mivel azt látjuk, hogy az „L” szövegnek csak a kezdőbetűje van kinyomtatva.

02. példa: Szövegfájl teljes tartalmának beolvasása a bemeneti adatfolyam osztály read() és close() metódusaival
Ebben a példában egy szöveges fájl teljes tartalmát fogjuk olvasni és megjeleníteni; az alábbiak szerint:
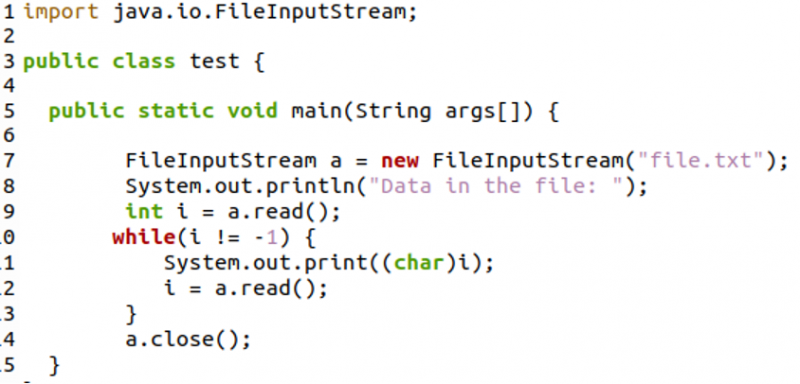
Ismét importálni fogjuk a java.io-t. File Input Stream csomag fájlbeviteli adatfolyam létrehozásához.
Először beolvassuk a fájl első bájtját, és megjelenítjük a megfelelő karaktert a while ciklusban. A while ciklus addig fut, amíg már nem marad bájt, vagyis a szöveg végéig a fájlban. A 12. sor a következő bájtot olvassa be, és a ciklus a fájl utolsó bájtjáig folytatódik.
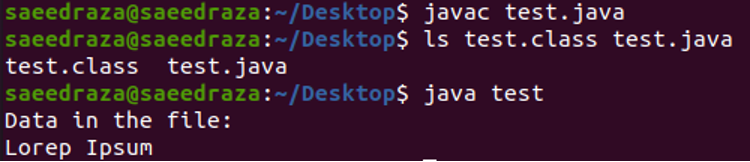
A fenti kód lefordítása és végrehajtása után a következő eredményeket kapjuk. Amint látjuk, a „Lorep Ipsum” fájl teljes szövege megjelenik a terminálban.
03. példa: A szöveges fájlban elérhető bájtok számának meghatározása a bemeneti adatfolyam osztály elérhető() metódusával
Ebben a példában a File Input Stream „available()” függvényét fogjuk használni a fájlbeviteli adatfolyam meglévő bájtok számának meghatározására.
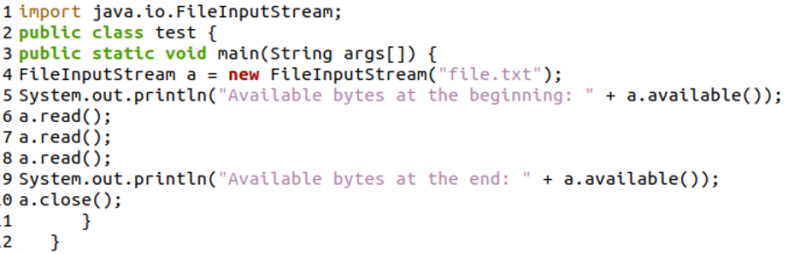
Először létrehoztunk egy „a” nevű fájl bemeneti adatfolyam osztály objektumot a következő kóddal. Az 5. sorban az „available()” metódust használtuk a fájlban elérhető bájtok teljes mennyiségének meghatározására és megjelenítésére. Ezután a 6. sortól a 8. sorig háromszor használtuk a „read()” függvényt. Most a 9. sorban ismét az „available()” metódust használtuk a fennmaradó bájtok ellenőrzésére és megjelenítésére.
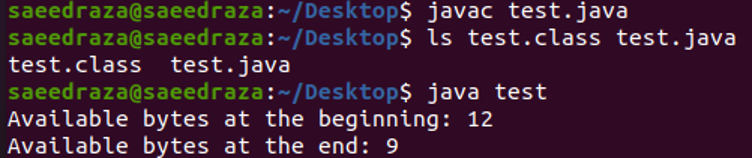
A kód fordítása és futtatása után láthatjuk, hogy a kimenet első sora a fájlban elérhető bájtok teljes számát mutatja. A következő sor a kód végén elérhető bájtok számát mutatja, ami 3-mal kevesebb, mint a kód elején elérhető bájtok száma. Ennek az az oka, hogy a kódunkban háromszor használtuk az olvasási módszert.
04. példa: Szövegfájl bájtjainak kihagyása egy adott pontból származó adatok olvasásához a bemeneti adatfolyam osztály skip() módszerével
Ebben a példában a File Input Stream „skip(x)” metódusát fogjuk használni, amely a bemeneti adatfolyam adott számú bájtnyi adatának figyelmen kívül hagyására vagy figyelmen kívül hagyására szolgál.
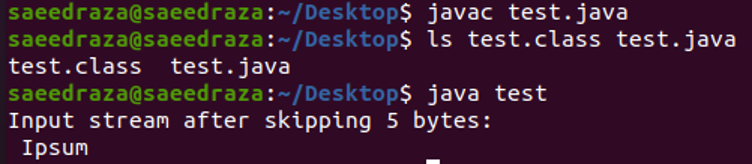
Az alábbi kódban először létrehoztunk egy fájlbeviteli adatfolyamot, amelyet az „a” változóban tároltunk. Ezután az „a.skip(5)” metódust használtuk, amely kihagyja a fájl első 5 bájtját. Ezután kinyomtattuk a fájl fennmaradó karaktereit a „read()” metódussal egy while cikluson belül. Végül a „close()” metódussal lezártuk a fájlbeviteli adatfolyamot.
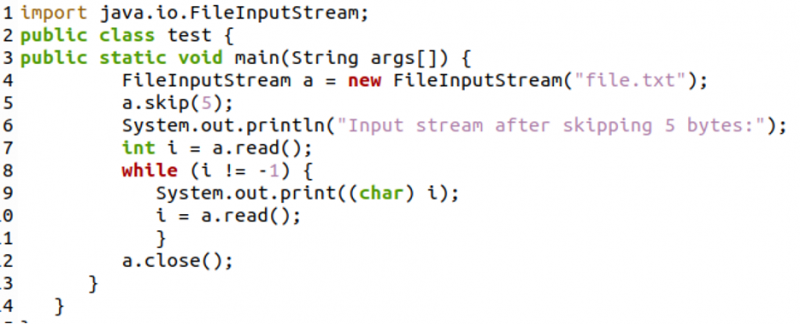
Alább látható a terminál képernyőképe a kód fordítása és futtatása után. Amint látjuk, csak az „Ipsum” jelenik meg, mivel az első 5 bájtot kihagytuk a „skip()” metódussal.
Következtetés
Ebben a cikkben a File Input Stream osztály felhasználását és annak különböző módszereit tárgyaltuk; read(), elérhető(), skip() és close(). Ezekkel a módszerekkel olvastuk be a fájl első elemét a read() és close() metódusokkal. Ezután az egész fájlt iteratív megközelítéssel és ugyanazokkal a módszerekkel olvassuk be. Ezután az available() metódussal határoztuk meg a fájl indításakor és befejezésekor jelen lévő bájtok számát. Ezt követően a skip() metódussal több bájtot kihagytunk a fájl beolvasása előtt, ami lehetővé tette, hogy megkapjuk a szükséges adatokat.