A C++ nyelv kezdete 1983-ban történt, nem sokkal ezután 'Bjare Stroustrup' dolgozott a C nyelvű osztályokkal, beleértve néhány további szolgáltatást is, mint például a kezelő túlterhelése. A használt fájlkiterjesztések: „.c” és „.cpp”. A C++ bővíthető és nem függ a platformtól, és tartalmazza az STL-t, amely a Standard Template Library rövidítése. Tehát alapvetően az ismert C++ nyelv valójában egy fordított nyelvként ismert, amely a forrásfájlt objektumfájlok létrehozására fordítja, amelyek egy linkerrel kombinálva futtatható programot hoznak létre.
Másrészt, ha a szintjéről beszélünk, akkor ez egy középszintű, értelmezve az alacsony szintű programozás előnyeit, mint például a meghajtók vagy a kernelek, valamint a magasabb szintű alkalmazások, mint a játékok, a GUI vagy az asztali alkalmazások. De a szintaxis majdnem ugyanaz a C és a C++ esetében is.
A C++ nyelv összetevői:
#include
Ez a parancs egy fejlécfájl, amely a „cout” parancsot tartalmazza. A felhasználó igényeitől és preferenciáitól függően egynél több fejlécfájl is lehet.
int main()
Ez az utasítás a mesterprogram függvény, amely minden C++ program előfeltétele, ami azt jelenti, hogy e nélkül nem lehet C++ programot végrehajtani. Itt az „int” a visszatérési változó adattípusa, amely megmondja, hogy a függvény milyen típusú adatokat ad vissza.
Nyilatkozat:
A változókat deklarálják, és neveket rendelnek hozzájuk.
Probléma kijelentés:
Ez elengedhetetlen egy programban, és lehet „while” ciklus, „for” ciklus vagy bármely más alkalmazott feltétel.
Üzemeltetők:
Az operátorokat a C++ programok használják, és néhányuk kulcsfontosságú, mert a feltételekhez alkalmazzák őket. Néhány fontos operátor: &&, ||, !, &, !=, |, &=, |=, ^, ^=.
C++ bemeneti kimenet:
Most megvitatjuk a C++ bemeneti és kimeneti képességeit. A C++-ban használt összes szabványos könyvtár maximális bemeneti és kimeneti képességeket biztosít, amelyeket bájtok sorozata formájában hajtanak végre, vagy általában az adatfolyamokhoz kapcsolódnak.
Bemeneti adatfolyam:
Abban az esetben, ha a bájtok az eszközről a fő memóriába kerülnek, akkor ez a bemeneti adatfolyam.
Kimeneti adatfolyam:
Ha a bájtok ellentétes irányban áramolnak, akkor ez a kimeneti adatfolyam.
A fejlécfájl megkönnyíti a bevitelt és a kimenetet C++ nyelven.
Példa:
Egy karakterlánc-üzenetet fogunk megjeleníteni egy karakter típusú karakterlánc használatával.
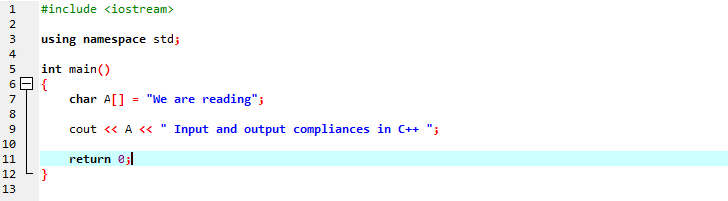
Az első sorba beletesszük az „iostream”-et, amely szinte az összes alapvető könyvtárat tartalmazza, amelyekre szükségünk lehet egy C++ program végrehajtásához. A következő sorban egy névteret deklarálunk, amely az azonosítók hatókörét biztosítja. A fő függvény meghívása után inicializálunk egy karakter típusú tömböt, amely tárolja a karakterlánc üzenetet, és a „cout” összefűzéssel megjeleníti. A szöveg képernyőn történő megjelenítéséhez a „cout”-ot használjuk. Ezenkívül vettünk egy „A” változót, amely egy karakteres adattípusú tömböt tartalmaz egy karaktersorozat tárolására, majd mindkét tömbüzenetet hozzáadtuk a statikus üzenethez a „cout” paranccsal.
A generált kimenet az alábbiakban látható:

Példa:
Ebben az esetben a felhasználó életkorát egy egyszerű karakterlánc-üzenetben ábrázolnánk.
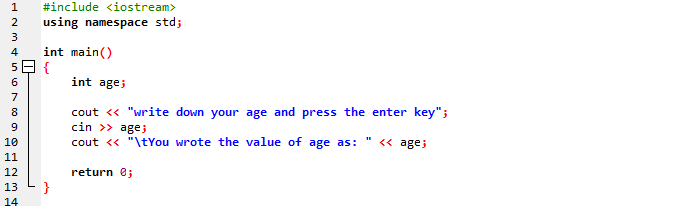
Első lépésben a könyvtárat is bevonjuk. Ezt követően egy névteret használunk, amely megadja az azonosítók hatókörét. A következő lépésben felhívjuk a fő() funkció. Ezt követően inicializáljuk az életkort „int” változóként. A „cin” parancsot használjuk az egyszerű karakterlánc-üzenet bevitelére és a „cout” parancsot. A „cin” a felhasználó életkorának értékét adja meg, a „cout” pedig a másik statikus üzenetben jeleníti meg.

Ez az üzenet jelenik meg a képernyőn a program végrehajtása után, hogy a felhasználó elérje a korát, majd nyomja meg az ENTER billentyűt.

Példa:
Itt bemutatjuk, hogyan nyomtathatunk ki egy karakterláncot a „cout” használatával.

Egy karakterlánc kinyomtatásához először egy könyvtárat, majd az azonosítók névterét adjuk meg. Az fő() függvényt hívják. Továbbá kinyomtatunk egy karakterlánc kimenetet a „cout” paranccsal a beillesztési operátorral, amely ezután megjeleníti a statikus üzenetet a képernyőn.

C++ adattípusok:
Az adattípusok a C++-ban egy nagyon fontos és széles körben ismert téma, mert ez a C++ programozási nyelv alapja. Hasonlóképpen, minden használt változónak meghatározott vagy azonosított adattípusúnak kell lennie.
Tudjuk, hogy minden változó esetében adattípust használunk a deklarálás során, hogy korlátozzuk a visszaállítandó adattípust. Vagy azt is mondhatjuk, hogy az adattípusok mindig megmondják egy változónak, hogy milyen adatot tárol. Valahányszor változót definiálunk, a fordító a deklarált adattípus alapján lefoglalja a memóriát, mivel minden adattípusnak más a memória tárolókapacitása.
A C++ nyelv segíti az adattípusok sokféleségét, hogy a programozó kiválaszthassa a megfelelő adattípust, amelyre szüksége lehet.
A C++ megkönnyíti az alábbi adattípusok használatát:
- Felhasználó által definiált adattípusok
- Származtatott adattípusok
- Beépített adattípusok
Például a következő sorok az adattípusok fontosságának szemléltetésére szolgálnak néhány általános adattípus inicializálásával:
int a = két ; // egész értékúszó F_N = 3.66 ; // lebegőpontos érték
kettős D_N = 8.87 ; // dupla lebegőpontos érték
char Alpha = 'p' ; // karakter
bool b = igaz ; // Boolean
Az alábbiakban látható néhány gyakori adattípus: milyen méretet adnak meg, és milyen típusú információkat tárolnak a változóik:
- Char: Egy bájt méretével egyetlen karaktert, betűt, számot vagy ASCII értékeket tárol.
- Logikai érték: 1 bájt méretével igaz vagy hamis értékként tárolja és adja vissza az értékeket.
- Int: 2 vagy 4 bájt méretű egész számokat tárol, amelyek tizedesjegy nélküliek.
- Lebegőpontos: 4 bájt méretével olyan törtszámokat tárol, amelyek egy vagy több tizedesjegyet tartalmaznak. Ez legfeljebb 7 tizedesjegy tárolására elegendő.
- Dupla lebegőpontos: 8 bájt méretével az egy vagy több tizedesjegyet tartalmazó törtszámokat is tárolja. Ez legfeljebb 15 tizedesjegy tárolására elegendő.
- Üres: Ha nincs meghatározott méret, az üresség tartalmaz valami értéktelent. Ezért olyan függvényeknél használatos, amelyek null értéket adnak vissza.
- Széles karakter: A 8 bitnél nagyobb méretnél, amely általában 2 vagy 4 bájt hosszú, a wchar_t képviseli, amely hasonló a char-hoz, és így egy karakterértéket is tárol.
A fent említett változók mérete a program használatától vagy a fordítóprogramtól függően eltérő lehet.
Példa:
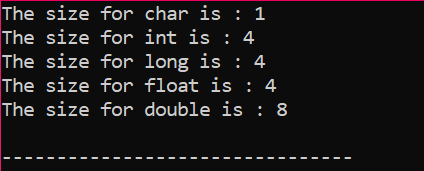
Írjunk csak egy egyszerű kódot C++ nyelven, amely megadja néhány fent leírt adattípus pontos méretét:

Ebben a kódban az
A kimenet bájtban érkezik, az ábrán látható módon:
Példa:
Itt hozzáadnánk két különböző adattípus méretét.
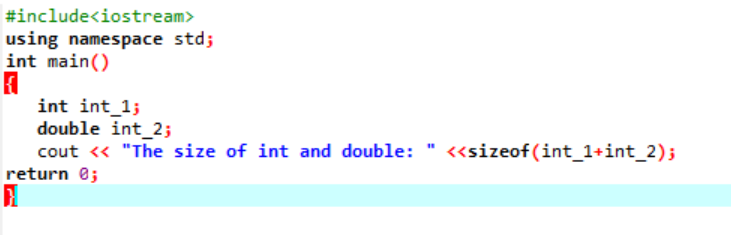
Először is beépítünk egy fejlécfájlt, amely egy „szabványos névteret” használ az azonosítók számára. Következő, a fő() függvényt hívjuk meg, amelyben először az „int” változót inicializáljuk, majd egy „dupla” változót, hogy ellenőrizzük a kettő mérete közötti különbséget. Ezután a méretüket a használatával összefűzzük mérete() funkció. A kimenetet a „cout” utasítás jeleníti meg.

Van még egy kifejezés, amit itt meg kell említeni, és az „Adatmódosítók” . A név azt sugallja, hogy az „adatmódosítókat” a beépített adattípusok mentén használják, hogy módosítsák azok hosszát, amelyet egy adott adattípus a fordító igénye vagy követelménye szerint fenntarthat.
A következő adatmódosítók érhetők el a C++ nyelven:
- Aláírva
- Aláírás nélküli
- Hosszú
- Rövid
A beépített adattípusok módosított méretét és megfelelő tartományát az alábbiakban említjük, ha ezeket az adattípus módosítókkal kombináljuk:
- Rövid int: 2 bájt méretű, számos módosítási tartományt tartalmaz -32 768 és 32 767 között
- Előjel nélküli rövid int: 2 bájt méretű, 0 és 65 535 között módosítható
- Unsigned int: 4 bájt méretű, 0 és 4 294 967 295 között módosítható
- Int: 4 bájt méretű, módosítási tartománya -2 147 483 648 és 2 147 483 647 között
- Hosszú int: 4 bájt méretű, módosítási tartománya -2 147 483 648 és 2 147 483 647 között
- Unsigned long int: 4 bájt méretű, 0 és 4 294 967,295 között módosítható
- Hosszú hosszú int: 8 bájt méretű, számos módosítási tartományt tartalmaz –(2^63) és (2^63)-1 között
- Unsigned long long int: 8 bájt méretű, 0 és 18 446 744 073 709 551 615 között módosítható
- Előjeles karakter: 1 bájt méretű, -128 és 127 között módosítható
- Előjel nélküli karakter: 1 bájt méretű, 0 és 255 között módosítható.
C++ felsorolás:
A C++ programozási nyelvben az „Enumeration” egy felhasználó által definiált adattípus. A felsorolás '' enum' C++ nyelven. A programban használt bármely konstans konkrét nevek kiosztására szolgál. Javítja a program olvashatóságát és használhatóságát.
Szintaxis:
A C++ nyelven a felsorolást a következőképpen deklaráljuk:
enum enum_Name { Állandó1 , Állandó2 , Állandó3… }A felsorolás előnyei C++ nyelven:
Az Enum a következő módokon használható:
- Gyakran használható a switch case utasításokban.
- Használhat konstruktorokat, mezőket és metódusokat.
- Csak az „enum” osztályt tudja kiterjeszteni, más osztályt nem.
- Megnövelheti a fordítási időt.
- Átjárható.
A felsorolás hátrányai C++ nyelven:
Az Enumnak van néhány hátránya is:
Ha egy név egyszer fel van sorolva, az nem használható újra ugyanabban a körben.
Például:
enum Napok{ Ült , Nap , Az én } ;
int Ült = 8 ; // Ebben a sorban hiba van
Az enum nem deklarálható tovább.
Például:
enum formák ;osztály színe
{
üres húz ( formák aShape ) ; //alakzatok nincsenek deklarálva
} ;
Úgy néznek ki, mint a nevek, de egész számok. Így automatikusan konvertálhatnak bármilyen más adattípusra.
Például:
enum formák{
Háromszög , kör , négyzet
} ;
int szín = kék ;
szín = négyzet ;
Példa:
Ebben a példában a C++ felsorolás használatát látjuk:
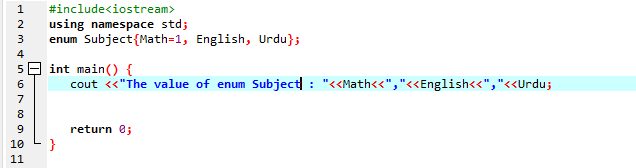
Ebben a kódvégrehajtásban először is az #include
Íme a végrehajtott program eredménye:

Tehát, amint láthatja, a tárgy értékei vannak: matematika, urdu, angol; vagyis 1,2,3.
Példa:
Íme egy másik példa, amelyen keresztül tisztázzuk az enummal kapcsolatos fogalmainkat:
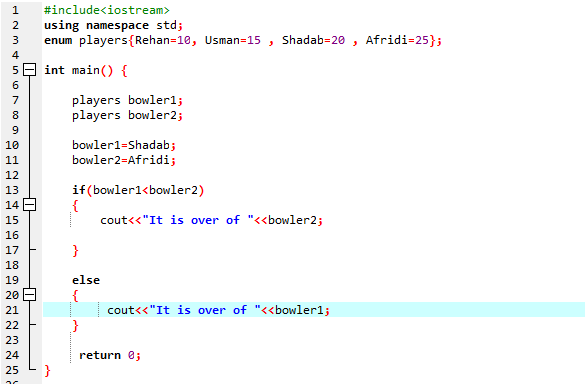
Ebben a programban az
If-else utasítást kell használnunk . Használtuk az összehasonlító operátort is az „if” utasításban, ami azt jelenti, hogy összehasonlítjuk, ha a „bowler2” nagyobb, mint a „bowler1”. Ezután az „if” blokk végrehajtódik, ami azt jelenti, hogy Afridi vége. Ezután beírtuk a „cout<<” kifejezést a kimenet megjelenítéséhez. Először kinyomtatjuk a „Vége van” kijelentést. Ezután a „bowler2” értéke. Ha nem, akkor az else blokk kerül meghívásra, ami azt jelenti, hogy a Shadab vége. Ezután a 'cout<<' parancs alkalmazásával megjelenítjük a 'Vége van' utasítást. Ezután a „bowler1” értéke.

Az If-else nyilatkozata szerint több mint 25-ünk van, ami Afridi értéke. Ez azt jelenti, hogy a „bowler2” enum változó értéke nagyobb, mint a „bowler1”, ezért kerül végrehajtásra az „if” utasítás.
C++ Ha más, Váltás:
A C ++ programozási nyelvben az „if utasítás” és a „switch utasítás” segítségével módosítjuk a programfolyamatot. Ezeket az utasításokat arra használják, hogy több parancskészletet biztosítsanak a program végrehajtásához, az említett utasítások valódi értékétől függően. A legtöbb esetben az „if” utasítás alternatívájaként operátorokat használunk. Mindezek a fent említett állítások kiválasztási állítások, amelyeket döntési vagy feltételes állításoknak nevezünk.
Az „if” kijelentés:
Ez az utasítás egy adott feltétel tesztelésére szolgál, amikor úgy érzi, hogy bármilyen program folyamát módosítani szeretné. Itt, ha egy feltétel igaz, a program végrehajtja az írott utasításokat, de ha a feltétel hamis, akkor egyszerűen leáll. Nézzünk egy példát;
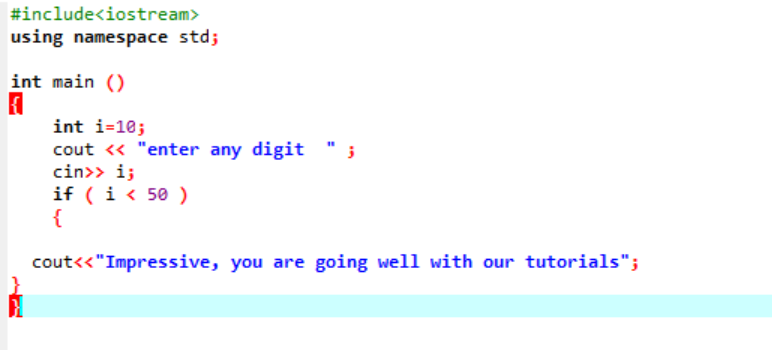
Ez az egyszerű „if” utasítás, ahol az „int” változót 10-re inicializáljuk. Ezután a felhasználó egy értéket vesz, és az „if” utasításban keresztellenőrzi. Ha megfelel az „if” utasításban alkalmazott feltételeknek, akkor a kimenet megjelenik.

Mivel a kiválasztott számjegy 40 volt, a kimenet az üzenet.
Az „If-else” kijelentés:
Egy összetettebb programban, ahol az „if” utasítás általában nem működik együtt, az „if-else” utasítást használjuk. Az adott esetben az „if else” utasítást használjuk az alkalmazott feltételek ellenőrzésére.
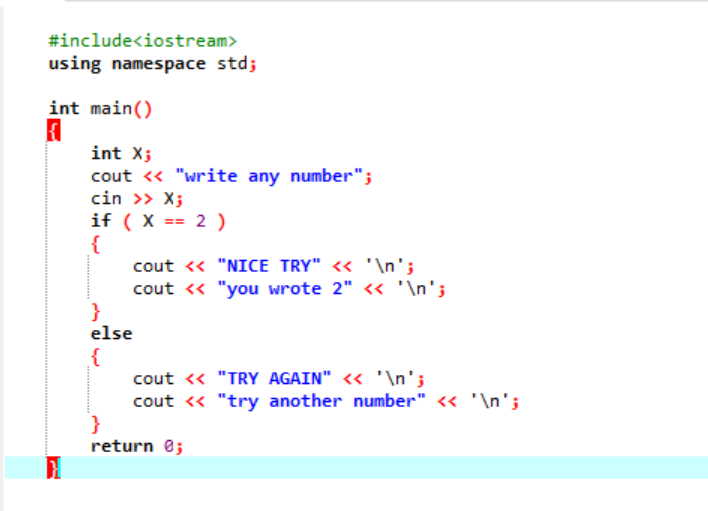
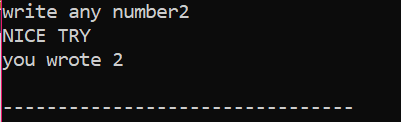
Először deklarálunk egy „int” adattípusú „x” nevű változót, amelynek értéke a felhasználótól származik. Most az „if” utasítást használjuk, ahol azt a feltételt alkalmaztuk, hogy ha a felhasználó által beírt egész szám 2. A kimenet a kívánt lesz, és egy egyszerű „SZÉP PRÓBA” üzenet jelenik meg. Ellenkező esetben, ha a beírt szám nem 2, a kimenet eltérő lesz.
Amikor a felhasználó beírja a 2-es számot, a következő kimenet jelenik meg.
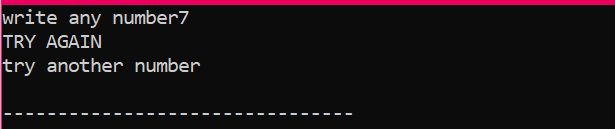
Amikor a felhasználó a 2 kivételével bármilyen más számot ír, a kimenet a következő:
Az If-else-if utasítás:
A beágyazott if-else-if utasítások meglehetősen összetettek, és akkor használatosak, ha ugyanabban a kódban több feltétel is szerepel. Gondolkodjunk el ezen egy másik példa segítségével:
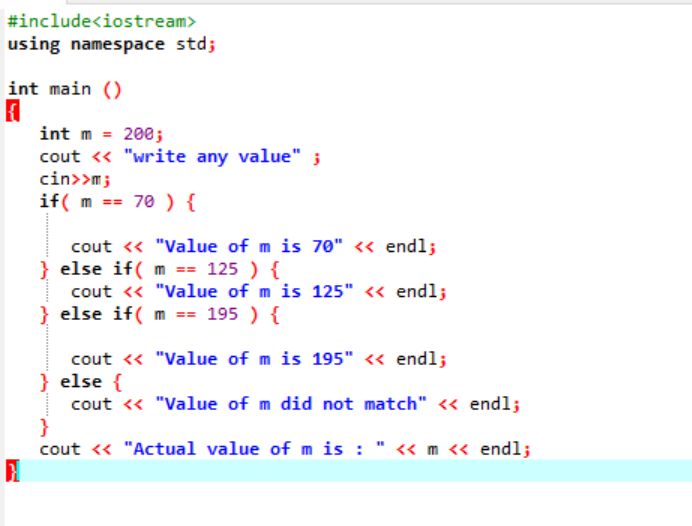
Itt a fejlécfájl és a névtér integrálása után az „m” változó értékét 200-ra inicializáltuk. Az „m” értékét ezután a felhasználótól veszik, majd a programban megadott több feltétellel összevetjük.
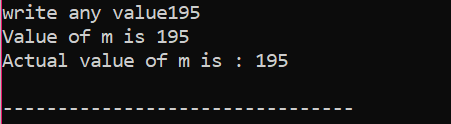
Itt a felhasználó a 195-ös értéket választotta. Ezért a kimenet azt mutatja, hogy ez az „m” tényleges értéke.
Váltási nyilatkozat:
A „switch” utasítást a C++ nyelvben olyan változókhoz használják, amelyeket tesztelni kell, ha több értékből álló listával egyenlő. A „Switch” utasításban a feltételeket különálló esetek formájában azonosítjuk, és minden esetre van egy törés az esetek végére. Több eset rendelkezik megfelelő feltételekkel, és olyan utasításokat alkalmaznak rájuk break utasításokkal, amelyek leállítják a switch utasítást, és áttérnek az alapértelmezett utasításra, ha nem támogatott feltétel.
„Szünet” kulcsszó:
A switch utasítás tartalmazza a „break” kulcsszót. Leállítja a kód végrehajtását a következő esetben. A switch utasítás végrehajtása akkor ér véget, amikor a C++ fordító találkozik a „break” kulcsszóval, és a vezérlő a switch utasítást követő sorba lép. Nem szükséges break utasítást használni egy kapcsolóban. A végrehajtás a következő esetre lép, ha nem használja.
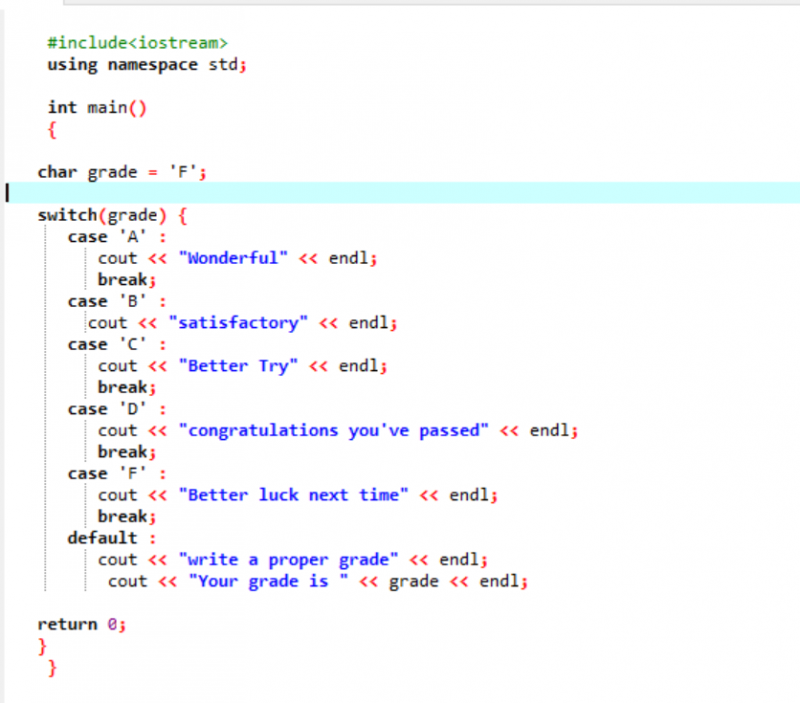
A megosztott kód első sorába belefoglaljuk a könyvtárat. Ezt követően hozzáadjuk a „névteret”. Megidézzük a fő() funkció. Ezután egy karakter adattípus fokozatát „F”-ként deklaráljuk. Ez az osztályzat lehet az Ön kívánsága, és az eredmény a kiválasztott esetekre megfelelően megjelenne. Az eredmény eléréséhez a switch utasítást alkalmaztuk.
Ha az „F”-et választjuk osztályzatként, akkor a kimenet „szerencse legközelebb” lesz, mert ez az az állítás, amelyet ki akarunk nyomtatni abban az esetben, ha „F” az osztályzat.

Változtassuk meg az osztályzatot X-re, és nézzük meg, mi történik. Osztályként „X”-et írtam, és a kapott eredmény az alábbiakban látható:

Tehát a „switch” helytelen kis- és nagybetűje automatikusan az alapértelmezett utasításra viszi a mutatót, és leállítja a programot.
Az if-else és a switch utasításoknak van néhány közös jellemzője:
- Ezeket az utasításokat a program végrehajtásának kezelésére használják.
- Mindkettő egy feltételt értékel, és ez határozza meg a program áramlását.
- Annak ellenére, hogy eltérő ábrázolási stílusuk van, ugyanarra a célra használhatók.
Az if-else és a switch utasítások bizonyos tekintetben különböznek:
- Míg a felhasználó definiálta az értékeket a „switch case” utasításokban, addig a megszorítások határozzák meg az „if-else” utasításokban az értékeket.
- Időbe telik annak meghatározása, hogy hol kell a változtatást végrehajtani, az „if-else” állítások módosítása pedig kihívást jelent. A másik oldalon a „switch” utasítások egyszerűen frissíthetők, mert könnyen módosíthatók.
- Számos kifejezés beillesztéséhez számos „if-else” utasítást használhatunk.
C++ hurkok:
Most megtudjuk, hogyan kell a ciklusokat használni a C++ programozásban. A „hurok” néven ismert vezérlőstruktúra egy sor utasítást ismétel meg. Más szóval, ismétlődő struktúrának nevezik. Az összes utasítás egyszerre, szekvenciális struktúrában kerül végrehajtásra . Másrészt a megadott utasítástól függően a feltételstruktúra végrehajthat vagy kihagyhat egy kifejezést. Bizonyos helyzetekben előfordulhat, hogy egy utasítást többször is végre kell hajtani.
A hurok típusai:
A hurkok három kategóriája létezik:
A hurokhoz:
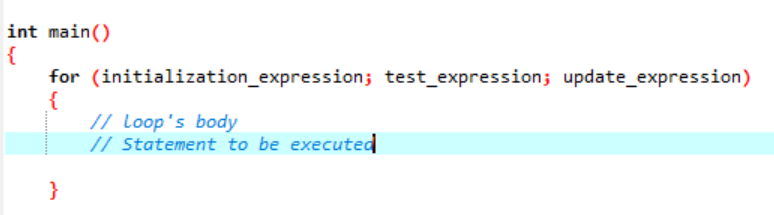
A hurok olyan dolog, amely ciklusként ismétli önmagát, és megáll, ha nem érvényesíti a megadott feltételt. A „for” ciklus számos utasítássorozatot valósít meg, és sűríti a kódot, amely megbirkózik a ciklusváltozóval. Ez azt szemlélteti, hogy a „for” ciklus az iteratív vezérlőstruktúra egy speciális típusa, amely lehetővé teszi számunkra, hogy meghatározott számú alkalommal ismétlődő hurkot hozzunk létre. A ciklus lehetővé teszi, hogy „N” számú lépést hajtsunk végre egyetlen egyszerű sor kódjának felhasználásával. Beszéljünk a szintaxisról, amelyet a szoftveralkalmazásban végrehajtandó „for” ciklushoz használunk.
A „for” ciklus végrehajtásának szintaxisa:
Példa:
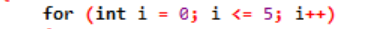
Itt egy hurokváltozót használunk, hogy ezt a hurkot egy „for” ciklusban szabályozzuk. Az első lépés az lenne, hogy értéket rendeljünk ehhez a változóhoz, amelyet ciklusként adunk meg. Ezt követően meg kell határoznunk, hogy kisebb vagy nagyobb-e a számláló értékénél. Most a ciklus törzsét kell végrehajtani, és a ciklusváltozót is frissíteni kell, ha az utasítás igazat ad vissza. A fenti lépéseket gyakran ismételjük, amíg el nem érjük a kilépési feltételt.
- Inicializálási kifejezés: Először be kell állítanunk a ciklusszámlálót a kifejezés bármely kezdeti értékére.
- Teszt kifejezés : Most tesztelnünk kell az adott feltételt az adott kifejezésben. Ha a feltételek teljesülnek, végrehajtjuk a „for” ciklus törzsét, és folytatjuk a kifejezés frissítését; ha nem, meg kell állnunk.
- Kifejezés frissítése: Ez a kifejezés egy bizonyos értékkel növeli vagy csökkenti a ciklusváltozót a ciklus törzsének végrehajtása után.
C++ programpéldák a „For” ciklus érvényesítéséhez:
Példa:
Ez a példa a 0 és 10 közötti egész értékek nyomtatását mutatja be.
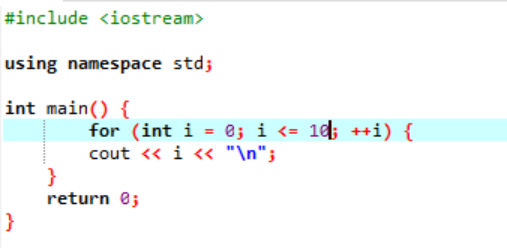
Ebben a forgatókönyvben a 0-tól 10-ig terjedő egész számokat kell kiírnunk. Először inicializáltunk egy i valószínűségi változót, amelynek értéke „0”, majd a már használt feltétel paraméter ellenőrzi a feltételt, ha i<=10. És amikor megfelel a feltételnek, és igazzá válik, megkezdődik a „for” ciklus végrehajtása. A végrehajtást követően a két növelő vagy csökkentő paraméter közül egyet kell végrehajtani, amelynél mindaddig, amíg a megadott i<=10 feltétel hamissá nem válik, az i változó értékét növeljük.

Iterációk száma i<10 feltétellel:
| száma iterációk |
Változók | i<10 | Akció |
| Első | i=0 | igaz | 0 jelenik meg, az i pedig 1-gyel nő. |
| Második | i=1 | igaz | Megjelenik az 1, az i pedig 2-vel nő. |
| Harmadik | i=2 | igaz | Megjelenik a 2, az i pedig 3-mal nő. |
| Negyedik | i=3 | igaz | Megjelenik a 3, az i pedig 4-gyel nő. |
| Ötödik | i=4 | igaz | Megjelenik a 4, az i pedig 5-tel növekszik. |
| Hatodik | i=5 | igaz | Megjelenik az 5, az i pedig 6-tal nő. |
| Hetedik | i=6 | igaz | Megjelenik a 6, az i pedig 7-tel növekszik. |
| Nyolcadik | i=7 | igaz | 7 jelenik meg, az i pedig 8-cal nő |
| Kilencedik | i=8 | igaz | 8 jelenik meg, az i pedig 9-cel növekszik. |
| Tizedik | i=9 | igaz | Megjelenik a 9, az i pedig 10-el növekszik. |
| Tizenegyedik | i=10 | igaz | 10 jelenik meg, az i pedig 11-gyel nő. |
| Tizenkettedik | i=11 | hamis | A hurok véget ért. |
Példa:
A következő példány az egész szám értékét jeleníti meg:
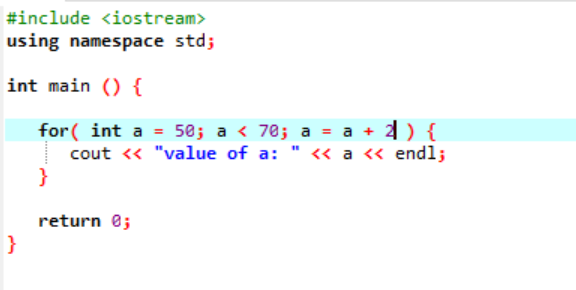
A fenti esetben egy 'a' nevű változót 50-es értékkel inicializálunk. A rendszer egy feltételt alkalmaz, ahol az 'a' változó kisebb, mint 70. Ezután az 'a' értéke frissül, és hozzáadódik 2. Ezután az „a” értéke egy 50-es kezdeti értékről indul, és egyidejűleg 2-t ad hozzá a ciklusban, amíg a feltétel false értéket ad vissza, és az „a” értéke megnő 70-ről, és a ciklus véget ér.
Iterációk száma:
| száma Ismétlés |
Változó | a=50 | Akció |
| Első | a=50 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 50-ből 52 lesz |
| Második | a=52 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 52-ből 54 lesz |
| Harmadik | a=54 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 54-ből 56 lesz |
| Negyedik | a=56 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 56-ból 58 lesz |
| Ötödik | a=58 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 58-ból 60 lesz |
| Hatodik | a=60 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 60-ból 62 lesz |
| Hetedik | a=62 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 62-ből 64 lesz |
| Nyolcadik | a=64 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és 64-ből 66 lesz |
| Kilencedik | a=66 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és a 66-ból 68 lesz |
| Tizedik | a=68 | igaz | Az a értéke két további egész szám hozzáadásával frissül, és a 68-ból 70 lesz |
| Tizenegyedik | a=70 | hamis | A hurok véget ért |
Hurok közben:
Amíg a meghatározott feltétel nem teljesül, egy vagy több utasítás végrehajtható. Ha az iteráció előre ismeretlen, nagyon hasznos. Először a feltételt ellenőrizzük, majd belép a ciklus törzsébe, hogy végrehajtsa vagy implementálja az utasítást.
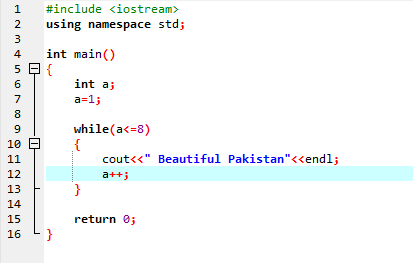
Az első sorban beépítjük az
Do-While hurok:
Amikor a definiált feltétel teljesül, utasítások sorozatát hajtják végre. Először a hurok testét hajtják végre. Ezt követően ellenőrzik a feltételt, hogy igaz-e vagy sem. Ezért az utasítás egyszer végrehajtásra kerül. A feltétel kiértékelése előtt a ciklus törzsét egy „Do-while” ciklusban dolgozzák fel. A program akkor fut, amikor a szükséges feltétel teljesül. Ellenkező esetben, ha a feltétel hamis, a program leáll.
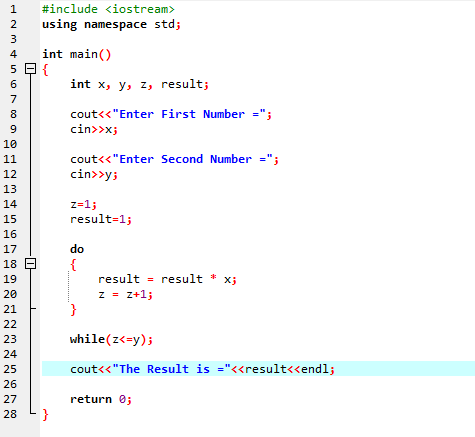
Itt integráljuk az
C++ folytatás/megszakítás:
C++ Nyilatkozat folytatása:
A folytatódik utasítás a C++ programozási nyelvben használatos a ciklus aktuális inkarnációjának elkerülésére, valamint a vezérlés áthelyezésére a következő iterációra. Hurkolás közben a turpināt utasítással bizonyos utasítások kihagyhatók. A cikluson belül is jól használható a végrehajtó utasításokkal együtt. Ha az adott feltétel igaz, akkor a folytatódik utasítást követő összes utasítás nem valósul meg.
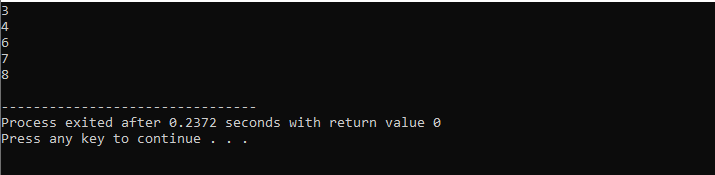
For ciklussal:
Ebben az esetben a „for ciklust” használjuk a C++ továbbra is utasításával, hogy megkapjuk a kívánt eredményt, miközben teljesítünk néhány meghatározott követelményt.

Kezdjük az
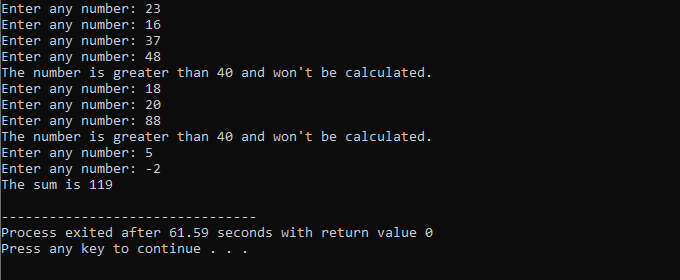
Egy időhurokkal:
A demonstráció során mind a 'while ciklus', mind a C++ 'continue' utasítást használtuk, beleértve néhány feltételt, hogy megnézzük, milyen kimenetet generálhatunk.
Ebben a példában azt a feltételt állítjuk be, hogy a számokat csak 40-hez adjuk. Ha a beírt egész szám negatív, akkor a „while” ciklus befejeződik. Másrészt, ha a szám nagyobb, mint 40, akkor az adott szám kimarad az iterációból.
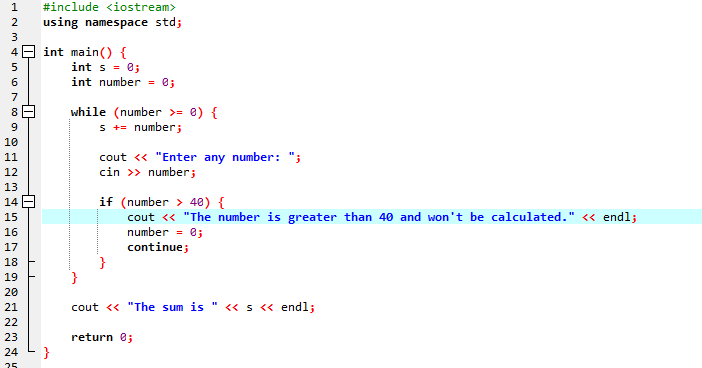
Beépítjük az
C++ break utasítás:
Amikor a break utasítást egy ciklusban használjuk a C++ nyelvben, a ciklus azonnal véget ér, valamint a programvezérlés újraindul a ciklus utáni utasításnál. Lehetőség van arra is, hogy egy esetet egy „kapcsoló” utasításon belül lezárjunk.
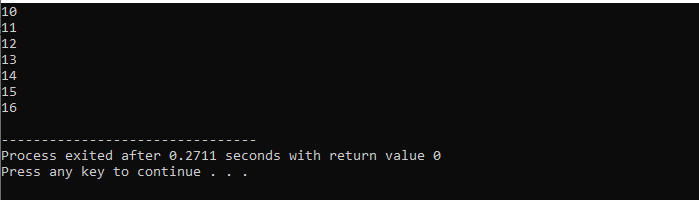
For ciklussal:
Itt a „for” ciklust használjuk a „break” utasítással, hogy megfigyeljük a kimenetet különböző értékeken át ismételve.
Először is beépítünk egy
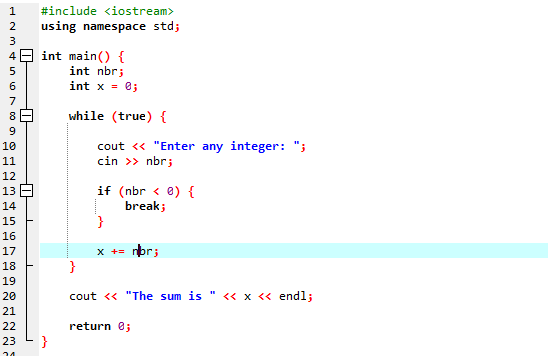
Egy időhurokkal:
A „while” ciklust a break utasítással együtt alkalmazzuk.
Kezdjük az
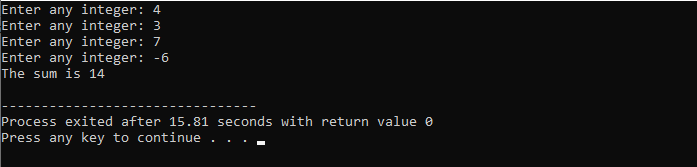
C++ funkciók:
A függvények arra szolgálnak, hogy egy már ismert programot több kódrészletre strukturáljanak, amelyek csak akkor futnak le, amikor meghívják. A C++ programozási nyelvben a függvényt olyan utasítások csoportjaként definiáljuk, amelyek megfelelő nevet kapnak, és ezek által kihívják őket. A felhasználó adatokat adhat át az általunk paramétereknek nevezett függvényeknek. A függvények felelősek a műveletek végrehajtásáért, amikor a kód a legnagyobb valószínűséggel újrafelhasználható.
Egy függvény létrehozása:
Bár a C++ számos előre definiált függvényt biztosít, mint pl fő(), amely megkönnyíti a kód végrehajtását. Ugyanígy létrehozhatja és meghatározhatja a funkciókat az Ön igényei szerint. Csakúgy, mint az összes szokásos függvénynél, itt is szükség van egy névre a függvénynek egy deklarációhoz, amelyet zárójellel adunk hozzá „()”.
Szintaxis:
Üres munka ( ){
// a függvény törzse
}
A Void a függvény visszatérési típusa. A Labor a neve, és a göndör zárójelek közrefogják a függvény törzsét, ahol hozzáadjuk a kódot a végrehajtáshoz.
Függvény hívása:
A kódban deklarált függvények csak akkor kerülnek végrehajtásra, ha meghívásra kerülnek. Függvény hívásához meg kell adni a függvény nevét a zárójellel együtt, amelyet egy pontosvessző ';' követ.
Példa:
Deklaráljunk és készítsünk egy felhasználó által definiált függvényt ebben a helyzetben.
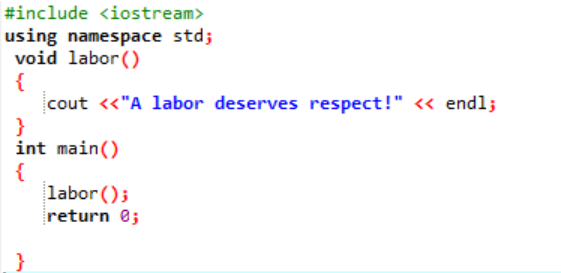
Kezdetben, amint azt minden programnál leírtuk, hozzárendelünk egy könyvtárat és névteret a program végrehajtásának támogatására. A felhasználó által definiált funkció munkaerő() mindig hívják, mielőtt leírná a fő() funkció. nevű függvény munkaerő() kijelentik, ahol egy „A munka tiszteletet érdemel!” üzenet jelenik meg. Ban,-ben fő() függvény egész visszatérési típusával hívjuk meg a munkaerő() funkció.

Ez az az egyszerű üzenet, amelyet az itt megjelenített felhasználó által definiált függvényben definiáltunk a segítségével fő() funkció.
Üres:
A fent említett esetben azt vettük észre, hogy a felhasználó által definiált függvény visszatérési típusa érvénytelen. Ez azt jelzi, hogy a függvény nem ad vissza értéket. Ez azt jelenti, hogy az érték nincs jelen, vagy valószínűleg nulla. Mert amikor egy függvény csak kinyomtatja az üzeneteket, nincs szüksége visszatérési értékre.
Ezt az ürességet hasonlóan használják a függvény paraméterterében, hogy egyértelműen jelezzék, hogy ez a függvény nem vesz fel tényleges értéket a hívás közben. A fenti helyzetben a munkaerő() a következőképpen működik:
Üres munka ( üres ){
Cout << „Egy munka tiszteletet érdemel ! ” ;
}
A tényleges paraméterek:
Meg lehet határozni a függvény paramétereit. A függvény paraméterei annak a függvénynek az argumentumlistájában vannak meghatározva, amely hozzáadódik a függvény nevéhez. Amikor meghívjuk a függvényt, a végrehajtás befejezéséhez át kell adnunk a paraméterek eredeti értékeit. Ezek a tényleges paraméterek. Míg a függvény definiálása közben meghatározott paramétereket formális paramétereknek nevezzük.
Példa:
Ebben a példában a két egész értéket egy függvényen keresztül kicseréljük vagy helyettesítjük.
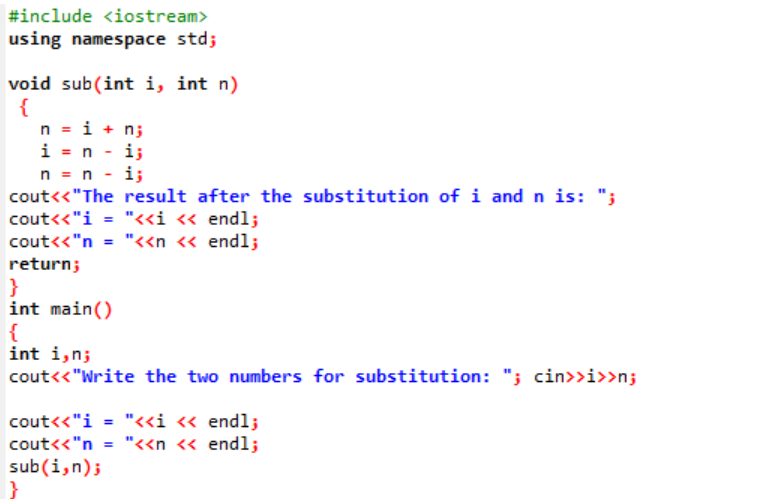
Kezdetben bevesszük a fejlécfájlt. A felhasználó által definiált függvény a deklarált és meghatározott named alatti(). Ez a függvény a két egész érték helyettesítésére szolgál, amelyek az i és az n. Ezután az aritmetikai operátorokat használjuk e két egész szám cseréjére. Az első egész szám „i” értéke az „n” helyett, az n értéke pedig az „i” helyett. Ezután az értékek váltása után az eredmény kinyomtatásra kerül. Ha arról beszélünk fő() függvényben a két egész szám értékét vesszük a felhasználótól és megjelenítjük. Az utolsó lépésben a felhasználó által definiált függvény alatti() hívjuk, és a két értéket felcseréljük.
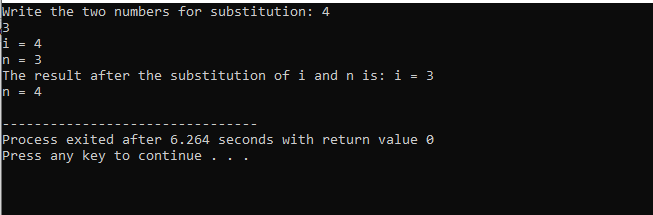
Ebben az esetben a két szám helyettesítése jól látható, hogy a használata közben a alatti() függvény esetén a paraméterlistán belüli 'i' és 'n' értéke a formális paraméter. A tényleges paraméterek azok a paraméterek, amelyek a végén áthaladnak fő() függvény, ahol a helyettesítő függvényt hívjuk.
C++ mutatók:
A pointer C++ nyelven sokkal könnyebben megtanulható és nagyszerűen használható. A C++ nyelvben pointereket használnak, mert megkönnyítik a munkánkat, és minden művelet nagy hatékonysággal működik pointerekkel. Ezenkívül van néhány olyan feladat, amelyet nem lehet végrehajtani, hacsak nem használnak mutatókat, például a dinamikus memóriafoglalást. A mutatókról beszélve a fő gondolat, amit meg kell érteni, az az, hogy a mutató csak egy változó, amely a pontos memóriacímet tárolja értékeként. A mutatók széles körű használata a C++ nyelvben a következő okokból adódik:
- Egyik funkció átadása a másiknak.
- Az új objektumok kiosztása a kupacban.
- Egy tömb elemeinek iterációjához
Általában az „&” (és) operátort használják a memóriában lévő bármely objektum címének eléréséhez.
Mutatók és típusaik:
A mutatónak több típusa van:
- Null mutatók: Ezek nulla értékű mutatók, amelyeket a C++ könyvtárak tárolnak.
- Aritmetikai mutató: Négy fő aritmetikai operátort tartalmaz, amelyek elérhetők: ++, –, +, -.
- Mutatók sora: Ezek tömbök, amelyeket néhány mutató tárolására használnak.
- Mutatóról mutatóra: Ez az a hely, ahol a mutatót a mutató felett használják.
Példa:
Gondolkodjon el a következő példán, amelyben néhány változó címe van kinyomtatva.
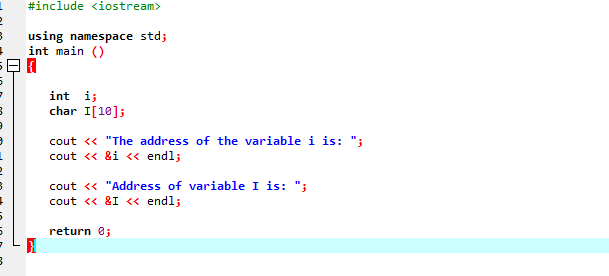
A fejlécfájl és a szabványos névtér hozzáadása után két változót inicializálunk. Az egyik egy i-vel jelzett egész szám, a másik pedig egy 10 karakteres 'I' karakter típusú tömb. Ezután mindkét változó címe megjelenik a „cout” paranccsal.
A kapott kimenet az alábbiakban látható:
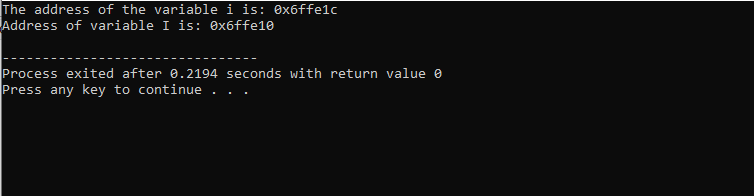
Ez az eredmény mindkét változó címét mutatja.
Másrészt a mutatót olyan változónak tekintjük, amelynek értéke maga egy másik változó címe. A mutató mindig egy (*) operátorral létrehozott adattípusra mutat, amely azonos típusú.
A mutató nyilatkozata:
A mutatót a következőképpen deklaráljuk:
típus * volt - név ;A mutató alaptípusát a „type”, míg a mutató nevét a „var-name” fejezi ki. A változó mutatóhoz való jogosításához pedig a csillag(*) szolgál.
A mutatók változókhoz való hozzárendelésének módjai:
Int * pi ; //egy egész adattípus mutatójaKettős * pd ; //egy kettős adattípus mutatója
Úszó * pf ; //egy lebegő adattípus mutatója
Char * pc ; //egy char adattípus mutatója
Szinte mindig van egy hosszú hexadecimális szám, amely azt a memóriacímet jelöli, amely kezdetben az összes mutató esetében azonos, függetlenül azok adattípusától.
Példa:
A következő példa bemutatja, hogy a mutatók hogyan helyettesítik az „&” operátort, és hogyan tárolják a változók címét.
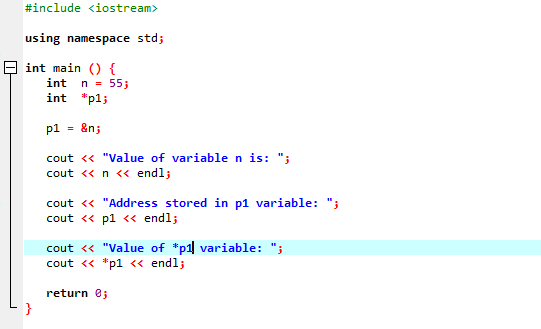
Integrálni fogjuk a könyvtárak és könyvtárak támogatását. Ezután a fő() függvény, ahol először deklarálunk és inicializálunk egy 'n' típusú 'int' változót 55 értékkel. A következő sorban inicializálunk egy 'p1' nevű mutatóváltozót. Ezt követően a 'p1' mutatóhoz hozzárendeljük az 'n' változó címét, majd megjelenítjük az 'n' változó értékét. Megjelenik a „p1” mutatóban tárolt „n” cím. Ezután a „*p1” értéke a „cout” paranccsal megjelenik a képernyőn. A kimenet a következő:
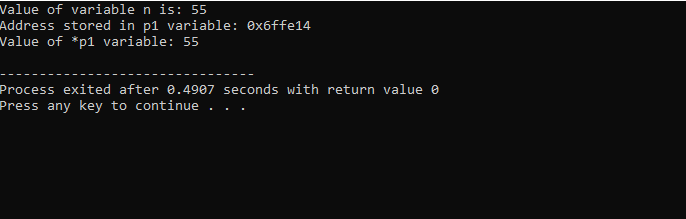
Itt azt látjuk, hogy az „n” értéke 55, és a „p1” mutatóban tárolt „n” címe 0x6ffe14. Megtalálható a mutatóváltozó értéke, és ez 55, ami megegyezik az egész változó értékével. Ezért egy mutató tárolja a változó címét, és a * mutató is tartalmazza az egész szám értékét, amely az eredetileg tárolt változó értékét adja vissza.
Példa:
Tekintsünk egy másik példát, ahol egy mutatót használunk, amely egy karakterlánc címét tárolja.
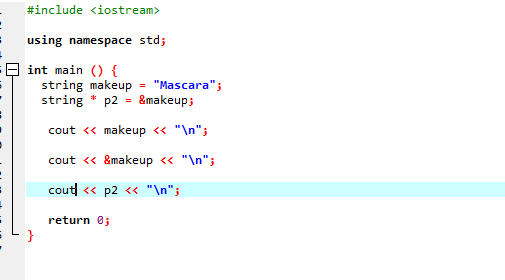
Ebben a kódban először könyvtárakat és névteret adunk hozzá. Ban,-ben fő() függvényében deklarálnunk kell egy „smink” nevű karakterláncot, amelyben a „Mascara” érték szerepel. A „*p2” karakterlánc típusú mutató a sminkváltozó címének tárolására szolgál. A „makeup” változó értéke ezután megjelenik a képernyőn a „cout” utasítás használatával. Ezt követően a „makeup” változó címe kerül kinyomtatásra, majd a végén megjelenik a „p2” mutatóváltozó, amely a mutatóval együtt mutatja a „makeup” változó memóriacímét.
A fenti kódból kapott kimenet a következő:
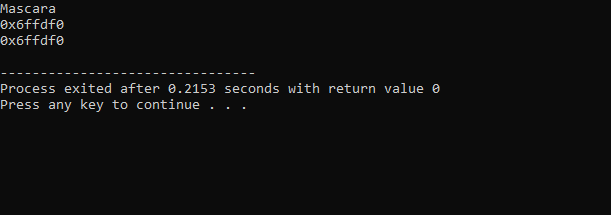
Az első sorban a „makeup” változó értéke jelenik meg. A második sor a „makeup” változó címét mutatja. Az utolsó sorban a „makeup” változó memóriacíme látható a mutató használatával.
C++ memóriakezelés:
A hatékony memóriakezeléshez C++-ban számos művelet hasznos a memóriakezeléshez C++-ban végzett munka közben. Amikor C++-t használunk, a leggyakrabban használt memóriafoglalási eljárás a dinamikus memóriafoglalás, ahol a memóriák a változókhoz futás közben vannak hozzárendelve; nem úgy, mint más programozási nyelveknél, ahol a fordító lefoglalhatja a memóriát a változókhoz. A C++-ban a dinamikusan lefoglalt változók felszabadítása szükséges, hogy a memória felszabaduljon, ha a változó már nincs használatban.
A memória dinamikus kiosztásához és felszabadításához C++ nyelven a „ új' és 'töröl' tevékenységek. Nagyon fontos a memória kezelése úgy, hogy ne vesszen kárba a memória. A memória kiosztása egyszerűvé és hatékonysá válik. Bármely C++ programban a memóriát két szempontból használják: kupacként vagy veremként.
- Kazal : A függvényben deklarált összes változó és minden egyéb részlet, amely a függvényhez kapcsolódik, a veremben tárolódik.
- Halom : A nem használt memóriát vagy azt a részt, ahonnan egy program végrehajtása során lefoglaljuk vagy hozzárendeljük a dinamikus memóriát, kupacnak nevezzük.
A tömbök használata során a memóriafoglalás olyan feladat, ahol egyszerűen nem tudjuk meghatározni a memóriát, kivéve a futásidőt. Tehát a maximális memóriát hozzárendeljük a tömbhöz, de ez sem jó gyakorlat, mivel a legtöbb esetben a memória kihasználatlan marad, és valahogy elpazarolódik, ami egyszerűen nem jó megoldás vagy gyakorlat a személyi számítógép számára. Ez az oka annak, hogy van néhány operátorunk, amelyek a futási idő alatt a kupac memóriájának lefoglalására szolgálnak. A két fő operátor, az „új” és a „törlés” a hatékony memóriafoglalásra és -felszabadításra szolgál.
C++ új operátor:
Az új operátor felelős a memória lefoglalásáért, és az alábbiak szerint kerül felhasználásra:
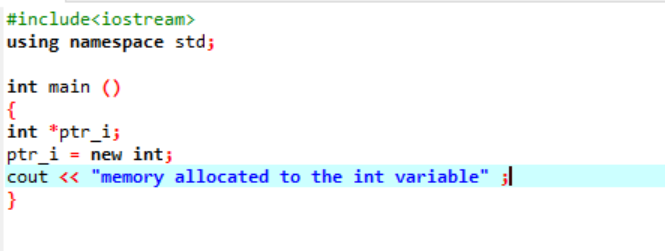
Ebben a kódban szerepel az

A memória egy mutató használatával sikeresen lefoglalva az „int” változóhoz.
C++ törlési operátor:
Amikor befejeztük a változó használatát, fel kell szabadítania azt a memóriát, amelyet korábban lefoglaltunk, mert már nincs használatban. Ehhez a „delete” operátort használjuk a memória felszabadítására.
A most áttekintendő példa mindkét operátor szerepeltetése.
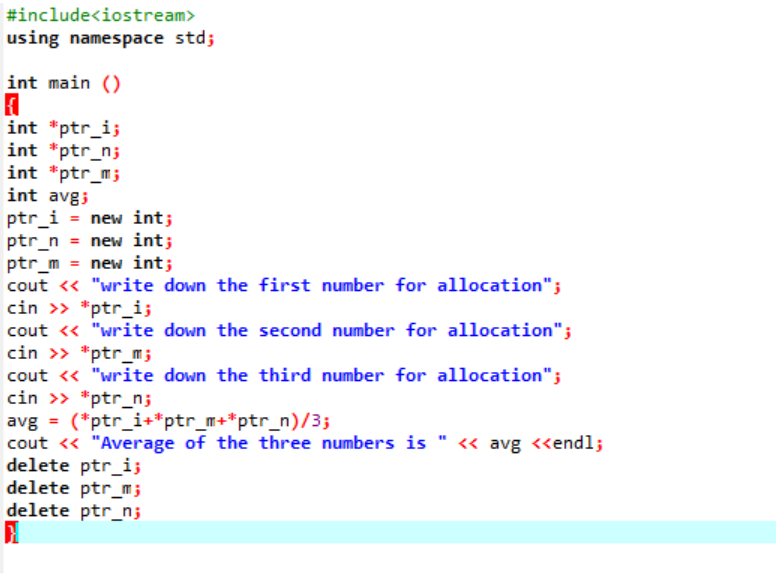
A felhasználótól vett három különböző érték átlagát számítjuk ki. A mutatóváltozók az „új” operátorral vannak hozzárendelve az értékek tárolására. Az átlag képlete megvalósul. Ezt követően a „delete” operátor kerül felhasználásra, amely törli a „new” operátor segítségével a mutatóváltozókban tárolt értékeket. Ez az a dinamikus kiosztás, ahol az allokáció a futási idő alatt történik, majd a felosztás nem sokkal a program leállása után megtörténik.
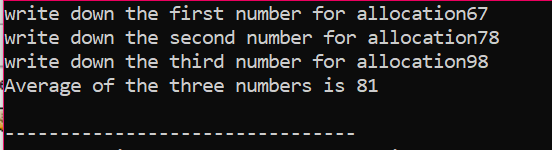
Tömb használata memóriafoglaláshoz:
Most látni fogjuk, hogyan használják az „új” és a „törlés” operátorokat a tömbök használata közben. A dinamikus kiosztás ugyanúgy történik, mint a változók esetében, mivel a szintaxis majdnem ugyanaz.
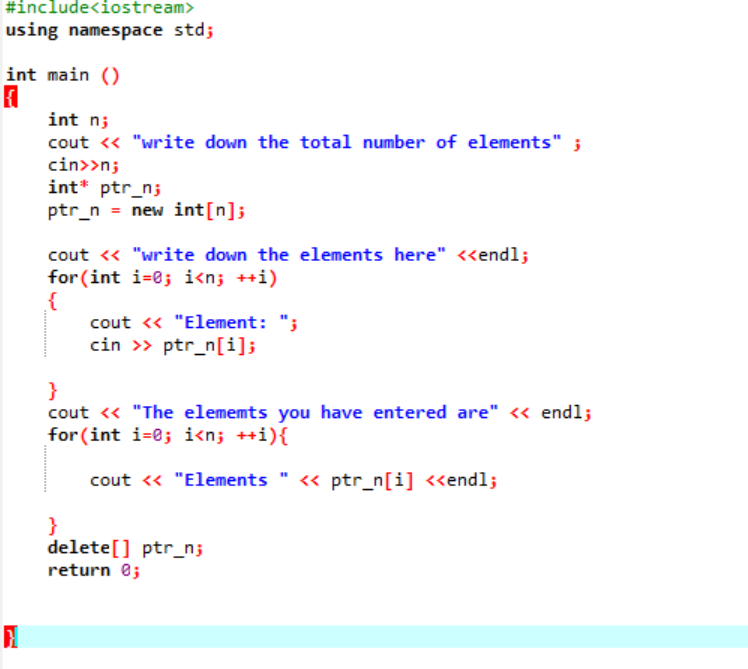
Az adott esetben azoknak az elemeknek a tömbjét vesszük figyelembe, amelyek értéke a felhasználótól származik. A tömb elemeit felveszi és deklarálja a mutatóváltozót, majd lefoglalja a memóriát. A memóriafoglalás után hamarosan elindul a tömbelemek beviteli eljárása. Ezután a tömbelemek kimenete egy „for” ciklus segítségével jelenik meg. Ennek a ciklusnak az iterációs feltétele az olyan elemek mérete, amelyek kisebbek, mint az n által képviselt tömb tényleges mérete.
Ha az összes elemet felhasználjuk, és nincs további követelmény, hogy újra használjuk őket, az elemekhez rendelt memória felszabadításra kerül a „delete” operátor segítségével.
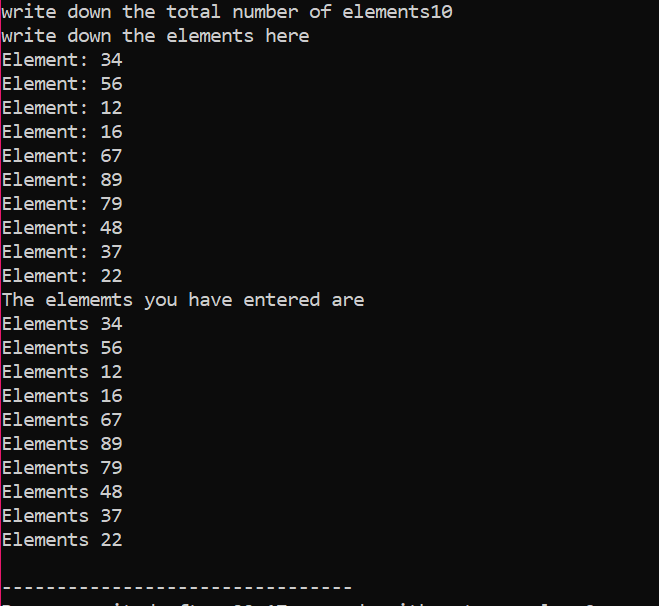
A kimenetben kétszer kinyomtatott értékkészleteket láthattunk. Az első „for” ciklus az elemek értékeinek lejegyzésére szolgál, a másik „for” ciklus pedig a már megírt értékek kinyomtatására szolgál, ami azt mutatja, hogy a felhasználó ezeket az értékeket az érthetőség kedvéért írta.
Előnyök:
Az „új” és a „törlés” operátor mindig prioritást élvez a C++ programozási nyelvben, és széles körben használják. Alapos megbeszélés és megértés során észrevehető, hogy az „új” operátornak túl sok előnye van. Az „új” operátor előnyei a memória lefoglalásában a következők:
- Az új kezelő könnyebben túlterhelhető.
- A futási idő alatti memória lefoglalásakor, ha nincs elég memória, akkor a program automatikus kivételt dob, nem pedig a program leállítását.
- A typecasting eljárás használatának nyüzsgése itt nincs jelen, mert az „új” operátor pontosan ugyanolyan típusú memóriával rendelkezik, mint az általunk kiosztott memória.
- A „new” operátor szintén elutasítja a sizeof() operátor használatát, mivel a „new” elkerülhetetlenül kiszámítja az objektumok méretét.
- Az „új” operátor lehetővé teszi számunkra, hogy inicializáljuk és deklaráljuk az objektumokat, még akkor is, ha spontán módon generálja számukra a helyet.
C++ tömbök:
Alapos megbeszélést folytatunk arról, hogy mik azok a tömbök, és hogyan deklarálják és implementálják őket egy C++ programban. A tömb egy olyan adatstruktúra, amely több érték tárolására szolgál egyetlen változóban, így csökkenti a sok változó önálló deklarálásának nyüzsgését.
A tömbök deklarációja:
Egy tömb deklarálásához először meg kell határozni a változó típusát, és megfelelő nevet kell adni a tömbnek, amelyet ezután a szögletes zárójelbe kell adni. Ez tartalmazza az adott tömb méretét mutató elemek számát.
Például:
Vonós smink [ 5 ] ;Ezt a változót úgy deklaráljuk, hogy öt karakterláncot tartalmaz egy „makeup” nevű tömbben. Ennek a tömbnek az értékeinek azonosításához és illusztrálásához használnunk kell a göndör zárójeleket, minden egyes elemet külön-külön dupla fordított vesszővel zárva, mindegyiket egyetlen vesszővel elválasztva.
Például:
Vonós smink [ 5 ] = { 'Szempillafesték' , 'Színez' , 'Ajakrúzs' , 'Alapítvány' , 'Első' } ;Hasonlóképpen, ha szeretne egy másik tömböt létrehozni egy másik adattípussal, amely állítólag „int”, akkor az eljárás ugyanaz lesz, csak módosítania kell a változó adattípusát az alábbiak szerint:
int Többszörös [ 5 ] = { két , 4 , 6 , 8 , 10 } ;Ha egész értékeket rendelünk a tömbhöz, ezeket nem szabad a fordított vesszők közé tenni, ami csak a karakterlánc-változónál működne. Tehát végső soron egy tömb egymással összefüggő adatelemek gyűjteménye, amelyekben származtatott adattípusok vannak tárolva.
Hogyan érhetők el a tömb elemei?
A tömbben lévő összes elemhez külön szám tartozik, amely az indexszámuk, amelyet a tömb elemeinek eléréséhez használnak. Az index értéke 0-val kezdődik, egészen eggyel kisebbig, mint a tömb mérete. A legelső érték indexértéke 0.
Példa:
Vegyünk egy nagyon egyszerű és egyszerű példát, amelyben egy tömbben inicializáljuk a változókat.
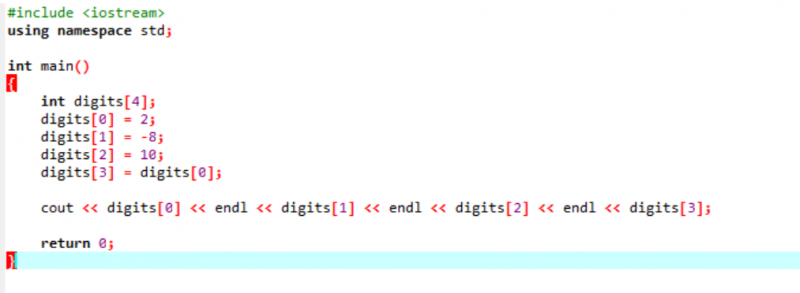
A legelső lépésben beépítjük az
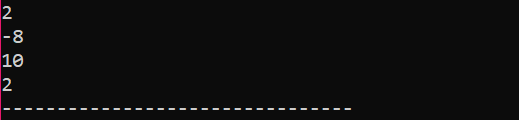
Ez a fenti kód eredménye. Az „endl” kulcsszó automatikusan áthelyezi a másik elemet a következő sorba.
Példa:
Ebben a kódban egy „for” hurkot használunk egy tömb elemeinek kinyomtatására.

A fenti esetben az alapvető könyvtárat adjuk hozzá. A szabványos névtér hozzáadása folyamatban van. Az fő() A függvény az a funkció, ahol egy adott program végrehajtásához szükséges összes funkciót végrehajtjuk. Ezután deklarálunk egy „Num” nevű int típusú tömböt, amelynek mérete 10. Ennek a tíz változónak az értékét a felhasználó a „for” ciklus használatával veszi át. Ennek a tömbnek a megjelenítéséhez ismét egy „for” hurkot használunk. A tömbben tárolt 10 egész szám a „cout” utasítás segítségével jelenik meg.
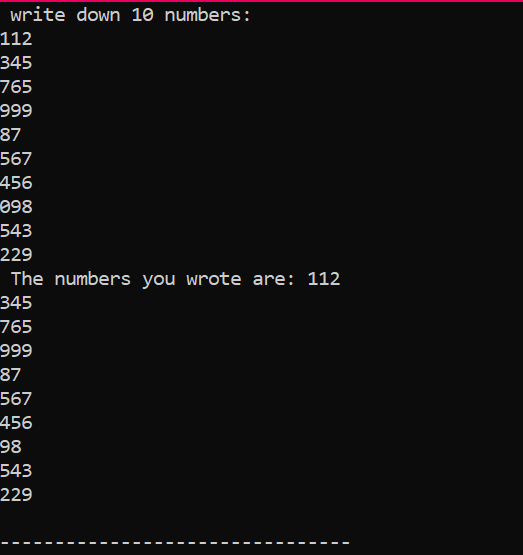
Ezt a kimenetet kaptuk a fenti kód végrehajtásából, amely 10 különböző értékű egész számot mutat.
Példa:
Ebben a forgatókönyvben egy tanuló átlagos pontszámát és az osztályban elért százalékos arányát fogjuk megtudni.
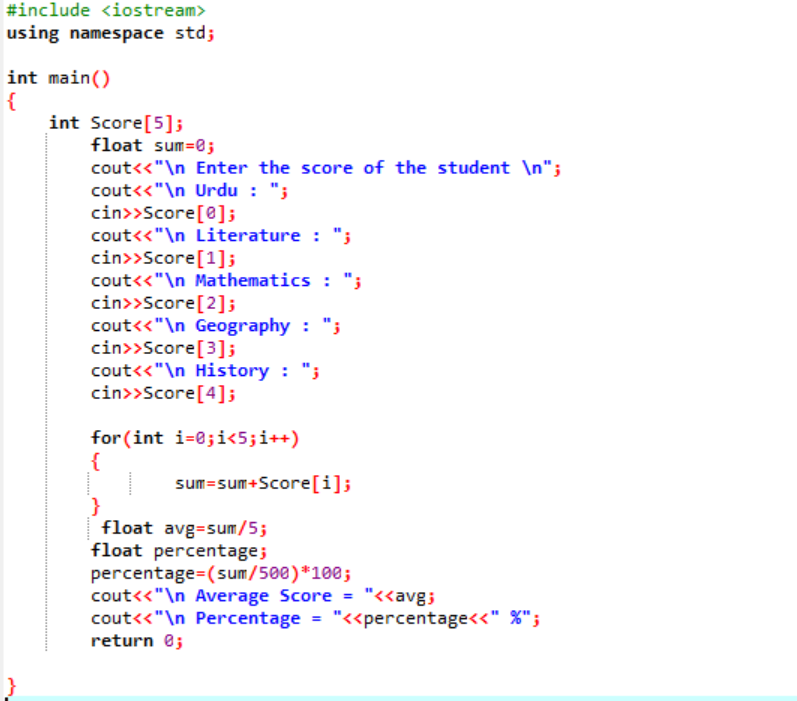
Először is hozzá kell adnia egy könyvtárat, amely kezdeti támogatást nyújt a C++ programnak. Ezután a „Score” nevű tömb 5-ös méretét adjuk meg. Ezután inicializáltuk az adattípus float „sum” változóját. Az egyes tantárgyak pontszámait a felhasználó manuálisan veszi le. Ezután egy „for” hurkot használunk az összes bevont alany átlagának és százalékos arányának megállapítására. Az összeget a tömb és a „for” ciklus használatával kapjuk meg. Ezután az átlagot az átlag képletével találjuk meg. Az átlag megállapítása után az értékét átadjuk a százaléknak, amelyet hozzáadunk a képlethez, hogy megkapjuk a százalékot. Ezután kiszámítja és megjeleníti az átlagot és a százalékot.
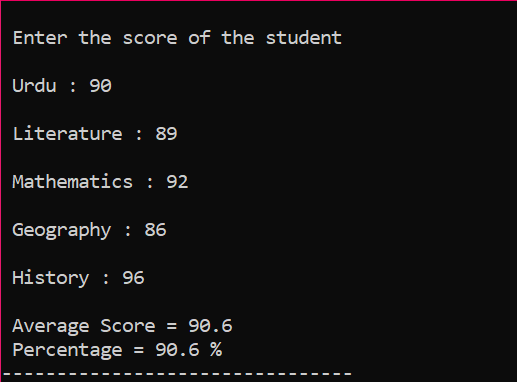
Ez az utolsó kimenet, ahol minden egyes tantárgyra külön-külön veszik a pontszámokat a felhasználók, és kiszámítják az átlagot és a százalékot.
A tömbök használatának előnyei:
- A tömb elemei könnyen elérhetők a hozzájuk rendelt indexszám miatt.
- A keresési műveletet egyszerűen elvégezhetjük egy tömbön keresztül.
- Abban az esetben, ha a programozásban bonyolultságra vágyunk, használhatunk egy 2-dimenziós tömböt, amely a mátrixokat is jellemzi.
- Több, hasonló adattípussal rendelkező érték tárolásához könnyen használható egy tömb.
A tömbök használatának hátrányai:
- A tömbök fix méretűek.
- A tömbök homogének, ami azt jelenti, hogy csak egyetlen típusú érték tárolódik.
- A tömbök egyenként tárolják az adatokat a fizikai memóriában.
- A beillesztési és törlési folyamat a tömbök esetében nem könnyű.
C++ objektumok és osztályok:
A C++ egy objektum-orientált programozási nyelv, ami azt jelenti, hogy az objektumok létfontosságú szerepet játszanak a C++-ban. Ha objektumokról beszélünk, először meg kell fontolni, hogy mik is azok, tehát az objektum az osztály bármely példánya. Mivel a C++ az OOP fogalmaival foglalkozik, a legfontosabbak az objektumok és az osztályok. Az osztályok valójában olyan adattípusok, amelyeket maga a felhasználó határoz meg, és amelyek az adattagok és a csak az adott osztályhoz tartozó példány által elérhető funkciók beágyazására szolgálnak. Az adattagok az osztályon belül definiált változók.
Az osztály más szóval egy vázlat vagy terv, amely felelős az adattagok meghatározásáért és deklarálásáért, valamint az adattagokhoz rendelt funkciókért. Az osztályban deklarált objektumok mindegyike képes megosztani az osztály által bemutatott összes jellemzőt vagy funkciót.
Tegyük fel, hogy van egy madarak nevű osztály, most kezdetben az összes madár repülhet, és szárnya van. Ezért a repülés egy olyan viselkedés, amelyet ezek a madarak felvesznek, és a szárnyak testük részét képezik, vagy alapvető jellemzői.
Osztály meghatározása:
Egy osztály meghatározásához követnie kell a szintaxist, és vissza kell állítania az osztálynak megfelelően. A „class” kulcsszó az osztály meghatározására szolgál, az összes többi adattag és függvény pedig a zárójelben, majd az osztály definíciójában van megadva.
Class NameOfClass
{
Hozzáférés-specifikátor :
Adattagok ;
Adattag funkciók ( ) ;
} ;
Tárgyak deklarálása:
Hamarosan az osztály meghatározása után létre kell hoznunk az objektumokat az osztály által megadott funkciók eléréséhez és definiálásához. Ehhez meg kell írnunk az osztály nevét, majd a deklarálandó objektum nevét.
Adattagok elérése:
A funkciókat és az adattagokat egy egyszerű pont „.” Operátor segítségével érhetjük el. A nyilvános adattagokat is ezzel az üzemeltetővel éri el, de a privát adattagok esetében egyszerűen nem lehet hozzájuk férni. Az adattagok hozzáférése attól függ, hogy a hozzáférés-módosítók milyen hozzáférés-szabályozást adnak nekik, amelyek lehetnek privát, nyilvánosak vagy védettek. Íme egy forgatókönyv, amely bemutatja, hogyan deklarálható az egyszerű osztály, az adattagok és a függvények.
Példa:
Ebben a példában néhány függvényt definiálunk, és az objektumok segítségével elérjük az osztályfüggvényeket és adattagokat.
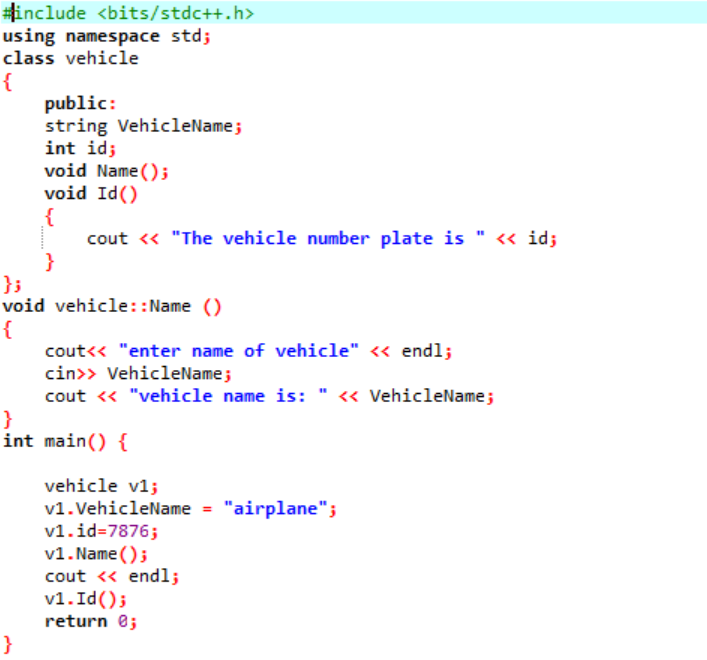
Első lépésben a könyvtárat integráljuk, majd a támogató könyvtárakat is bele kell foglalnunk. Az osztály kifejezetten definiálva van, mielőtt meghívná a fő() funkció. Ezt az osztályt „járműnek” nevezik. Az adattagok a „jármű neve és a jármű „azonosítója” voltak, amely a jármű rendszáma egy karakterlánccal, illetve int adattípussal. A két függvény ehhez a két adattaghoz van deklarálva. Az id() funkció megjeleníti a jármű azonosítóját. Mivel az osztály adattagjai nyilvánosak, így az osztályon kívül is elérhetjük őket. Ezért hívjuk a név() függvényt az osztályon kívül, majd átveszi a „VehicleName” értékét a felhasználótól, és kinyomtatja a következő lépésben. Ban,-ben fő() függvényt, deklarálunk egy objektumot a szükséges osztályból, amely segít az osztály adattagjainak és függvényeinek elérésében. Továbbá csak akkor inicializáljuk a jármű nevének és azonosítójának értékeit, ha a felhasználó nem adja meg a jármű nevének értékét.
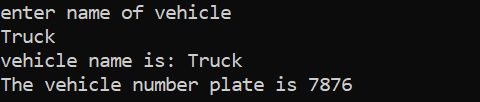
Ez az a kimenet, amelyet akkor kap, amikor a felhasználó saját maga adja meg a jármű nevét, és a rendszámtáblák a hozzá rendelt statikus értékek.
Ha a tagfüggvények definíciójáról beszélünk, meg kell értenünk, hogy nem mindig kötelező az osztályon belül definiálni a függvényt. Amint a fenti példában is látható, az osztály funkcióját az osztályon kívül határozzuk meg, mivel az adattagok nyilvánosan deklaráltak, és ez a '::' hatókör-feloldó operátor segítségével, valamint az osztály nevével történik. az osztály és a függvény neve.
C++ konstruktorok és destruktorok:
Példák segítségével alaposan áttekintjük ezt a témát. Az objektumok törlése és létrehozása a C++ programozásban nagyon fontos. Ezért, amikor egy osztályhoz példányt hozunk létre, néhány esetben automatikusan meghívjuk a konstruktor metódusokat.
Kivitelezők:
Ahogy a név is mutatja, a konstruktor a „konstrukció” szóból származik, amely valaminek a létrehozását határozza meg. Tehát a konstruktor az újonnan létrehozott osztály származtatott függvénye, amely osztja az osztály nevét. És az osztályba tartozó objektumok inicializálására használják. Ezenkívül a konstruktornak nincs önmagának visszatérési értéke, ami azt jelenti, hogy a visszatérési típusa sem lesz érvénytelen. Az érveket nem kötelező elfogadni, de szükség esetén hozzá lehet adni. A konstruktorok hasznosak a memória egy osztály objektumhoz való lefoglalásában és a tagváltozók kezdeti értékének beállításában. Az objektum inicializálása után a kezdeti érték argumentumok formájában adható át a konstruktor függvénynek.
Szintaxis:
Az osztály neve ( ){
//a konstruktor törzse
}
Konstruktorok típusai:
Paraméterezett konstruktor:
Amint azt korábban tárgyaltuk, a konstruktornak nincs paramétere, de hozzá lehet adni egy tetszőleges paramétert. Ez inicializálja az objektum értékét a létrehozás közben. Ennek a fogalomnak a jobb megértéséhez vegye figyelembe a következő példát:
Példa:
Ebben az esetben létrehoznánk az osztály konstruktorát, és deklarálnánk a paramétereket.
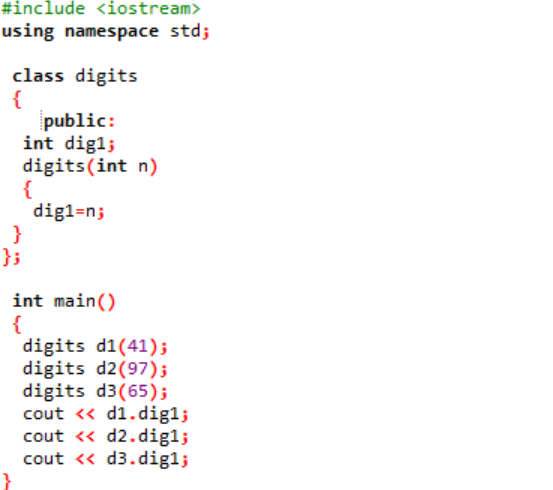
A fejlécfájlt a legelső lépésben belefoglaljuk. A névtér használatának következő lépése a program könyvtárainak támogatása. A „digits” nevű osztályt deklarálják, ahol először a változókat nyilvánosan inicializálják, hogy az egész programban elérhetőek legyenek. A rendszer deklarál egy „dig1” nevű változót integer adattípussal. Ezután deklaráltunk egy konstruktort, amelynek neve hasonló az osztály nevéhez. Ennek a konstruktornak egy egész számú változója van átadva neki 'n' néven, a 'dig1' osztályváltozó pedig n-re van állítva. Ban,-ben fő() A program függvényében három objektum jön létre a „számjegyek” osztály számára, és hozzárendel néhány véletlenszerű értéket. Ezeket az objektumokat azután arra használják, hogy automatikusan lehívják az azonos értékkel rendelkező osztályváltozókat.
Az egész értékek kimenetként jelennek meg a képernyőn.

Másolás konstruktor:
Ez az a típusú konstruktor, amely az objektumokat argumentumnak tekinti, és az egyik objektum adattagjainak értékeit megkettőzi a másikkal. Ezért ezeket a konstruktorokat arra használják, hogy deklarálják és inicializálják az egyik objektumot a másikból. Ezt a folyamatot másolás inicializálásnak nevezik.
Példa:
Ebben az esetben a másolatkészítő deklarálva lesz.

Először is integráljuk a könyvtárat és a könyvtárat. Egy „New” nevű osztály deklarálva van, amelyben az egész számok „e” és „o” inicializálásra kerülnek. A konstruktor nyilvánossá válik, ahol a két változóhoz hozzárendeljük az értékeket, és ezeket a változókat deklaráljuk az osztályban. Ezután ezek az értékek a segítségével jelennek meg fő() függvényt az „int” visszatérési típussal. Az kijelző() függvény meghívása és meghatározása utána történik, ahol a számok megjelennek a képernyőn. Benne fő() funkciót, az objektumokat elkészítik, és ezeket a hozzárendelt objektumokat véletlenszerű értékekkel inicializálják, majd a kijelző() módszert alkalmazzák.
A másoláskonstruktor használatával kapott kimenet az alábbiakban látható.

Pusztítók:
Ahogy a név határozza meg, a destruktorokat a konstruktor által létrehozott objektumok megsemmisítésére használják. A konstruktorokkal összehasonlítva a destruktorok ugyanazt a nevet viselik, mint az osztály, de egy további tilde (~) követi.
Szintaxis:
~ Új ( ){
}
A destruktor nem vesz fel semmilyen argumentumot, és még visszatérési értéke sincs. A fordító implicit fellebbezéssel kéri a programból való kilépést, hogy megtisztítsa a tárhelyet, amely már nem érhető el.
Példa:
Ebben a forgatókönyvben egy destruktort használunk egy objektum törlésére.
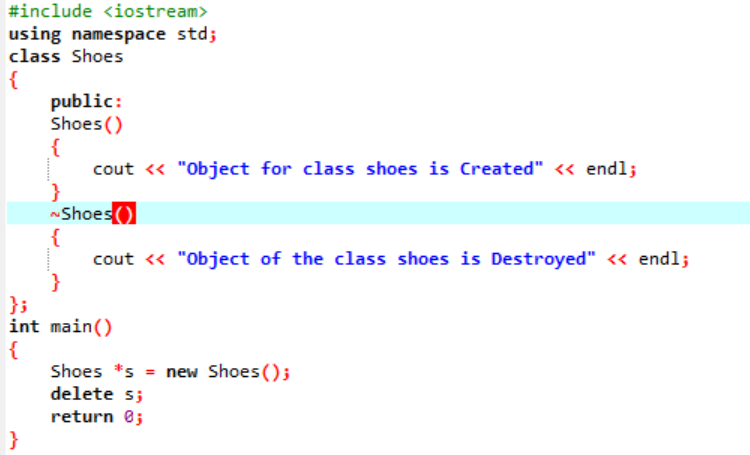
Itt készül a „Cipők” osztály. Létrejön egy konstruktor, amelynek neve hasonló az osztályéhoz. A konstruktorban egy üzenet jelenik meg, ahol az objektum létrejön. A konstruktor után elkészül a destruktor, amely törli a konstruktorral létrehozott objektumokat. Ban,-ben fő() függvényében létrejön egy „s” nevű mutatóobjektum, és egy „delete” kulcsszót használunk az objektum törlésére.

Ezt a kimenetet kaptuk a programtól, ahol a destruktor törli és megsemmisíti a létrehozott objektumot.
Különbség a konstruktorok és a destruktorok között:
| Konstruktorok | rombolók |
| Létrehozza az osztály példányát. | Megsemmisíti az osztály példányát. |
| Az osztálynév mellett argumentumok vannak. | Nincsenek argumentumai vagy paraméterei |
| Az objektum létrehozásakor hívják meg. | Akkor hívják, ha az objektum megsemmisül. |
| Lefoglalja a memóriát az objektumokhoz. | Felszabadítja az objektumok memóriáját. |
| Túlterhelhető. | Nem lehet túlterhelni. |
C++ öröklődés:
Most megismerjük a C++ öröklődését és hatókörét.
Az öröklődés az a módszer, amelyen keresztül egy új osztályt generálnak vagy egy meglévő osztályból származnak. A jelenlegi osztályt „alaposztálynak” vagy „szülő osztálynak”, a létrejövő új osztályt pedig „származékos osztálynak” nevezik. Ha azt mondjuk, hogy egy gyermekosztály öröklődik egy szülő osztálytól, az azt jelenti, hogy a gyermek rendelkezik a szülő osztály összes tulajdonságával.
Az öröklődés egy (egy) kapcsolatra utal. Minden kapcsolatot öröklődésnek nevezünk, ha az „is-a”-t két osztály között használjuk.
Például:
- A papagáj egy madár.
- A számítógép egy gép.
Szintaxis:
A C++ programozásban az öröklődést a következőképpen használjuk vagy írjuk:
osztály < származtatott - osztály >: < hozzáférés - specifikáló >< bázis - osztály >A C++ öröklődés módjai:
Az öröklődés 3 módot foglal magában az osztályok öröklésére:
- Nyilvános: Ebben a módban, ha egy utódosztály deklarálva van, akkor a szülőosztály tagjait az utódosztály örökli, mint a szülőosztály azonosságát.
- Védett: I Ebben a módban a szülő osztály nyilvános tagjai a gyermekosztály védett tagjaivá válnak.
- Magán : Ebben a módban a szülőosztály összes tagja privát lesz a gyermekosztályban.
A C++ öröklődés típusai:
A C++ öröklődés típusai a következők:
1. Egyszeri öröklődés:
Ezzel a fajta öröklődéssel az osztályok egy alaposztályból származnak.
Szintaxis:
M osztály{
Test
} ;
N osztály : nyilvános M
{
Test
} ;
2. Többszörös öröklődés:
Az ilyen típusú öröklődésben egy osztály különböző alaposztályokból származhat.
Szintaxis:
M osztály{
Test
} ;
N osztály
{
Test
} ;
O osztály : nyilvános M , nyilvános N
{
Test
} ;
3. Többszintű öröklődés:
Egy gyermekosztály egy másik gyermekosztály leszármazottja ebben az öröklési formában.
Szintaxis:
M osztály{
Test
} ;
N osztály : nyilvános M
{
Test
} ;
O osztály : nyilvános N
{
Test
} ;
4. Hierarchikus öröklődés:
Ebben az öröklési módszerben egy alaposztályból több alosztály jön létre.
Szintaxis:
M osztály{
Test
} ;
N osztály : nyilvános M
{
Test
} ;
O osztály : nyilvános M
{
} ;
5. Hibrid öröklődés:
Az ilyen típusú öröklődésben több öröklődés kombinálódik.
Szintaxis:
M osztály{
Test
} ;
N osztály : nyilvános M
{
Test
} ;
O osztály
{
Test
} ;
osztály P : nyilvános N , nyilvános O
{
Test
} ;
Példa:
Futtatjuk a kódot, hogy bemutassuk a többszörös öröklődés fogalmát a C++ programozásban.
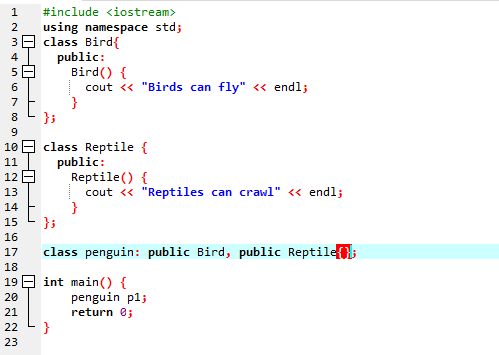
Mivel egy szabványos bemeneti-kimeneti könyvtárral kezdtük, az alaposztály nevét a „Madár” néven adtuk, és nyilvánosságra hoztuk, hogy tagjai elérhetőek legyenek. Aztán van „Reptile” alaposztályunk, és nyilvánosságra is hoztuk. Ezután „cout”-unk van a kimenet kinyomtatásához. Ezek után létrehoztunk egy gyerekosztályú „pingvint”. Ban,-ben fő() függvényt a „p1” pingvin osztály tárgyává tettük. Először a „Madár” osztály, majd a „Hüllő” osztály fog végrehajtani.
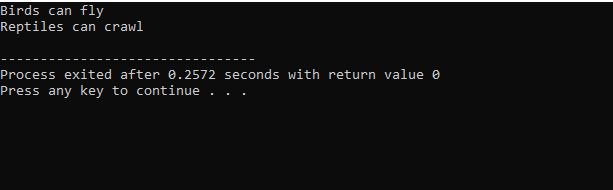
A kód C++ nyelven történő végrehajtása után megkapjuk a „Madár” és a „Reptile” alaposztályok kimeneti utasításait. Ez azt jelenti, hogy a „pingvin” osztály a „Madár” és a „Hüllő” alaposztályokból származik, mivel a pingvin egy madár és egy hüllő is. Repülni és kúszni is tud. Ezért a többszörös öröklődés bebizonyította, hogy egy gyermekosztály sok alaposztályból származtatható.
Példa:
Itt végrehajtunk egy programot, amely megmutatja, hogyan kell használni a többszintű öröklődést.
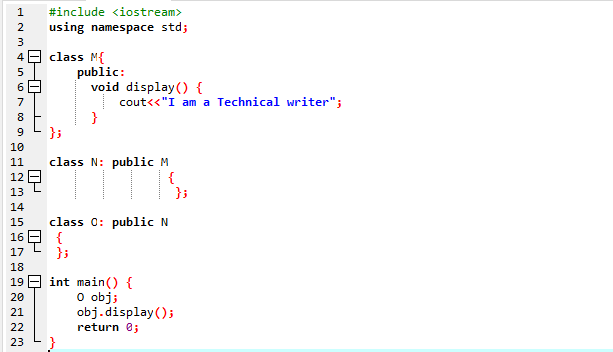
A programunkat input-output Streams használatával indítottuk el. Ezután deklaráltunk egy „M” szülőosztályt, amely nyilvánosnak van beállítva. Felhívtuk a kijelző() függvény és a „cout” parancs az utasítás megjelenítéséhez. Ezután létrehoztunk egy „N” gyermekosztályt, amely az „M” szülőosztályból származik. Van egy új „O” gyermekosztályunk, amely az „N” gyermekosztályból származik, és mindkét származtatott osztály törzse üres. A végén hivatkozunk a fő() függvény, amelyben inicializálnunk kell az „O” osztály objektumát. Az kijelző() Az objektum funkcióját az eredmény bemutatására használják.
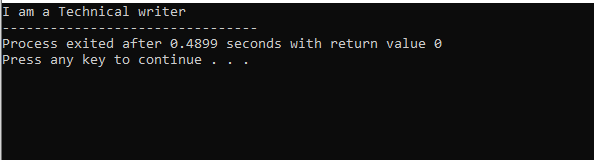
Ezen az ábrán az „M” osztály eredményét láthatjuk, amely a szülő osztály, mert volt a kijelző() funkciót benne. Tehát az „N” osztály az „M” szülőosztályból, az „O” osztály pedig az „N” szülőosztályból származik, amely a többszintű öröklődésre utal.
C++ polimorfizmus:
A „polimorfizmus” kifejezés két szó gyűjteményét jelenti „poli” és ' morfizmus” . A „poli” szó „sok”-ot, a „morfizmus” pedig „formákat” jelent. A polimorfizmus azt jelenti, hogy egy objektum különböző körülmények között eltérően viselkedhet. Lehetővé teszi a programozó számára a kód újrafelhasználását és kiterjesztését. Ugyanaz a kód a feltételtől függően eltérően működik. Egy objektum végrehajtása futási időben is használható.
A polimorfizmus kategóriái:
A polimorfizmus főként kétféle módon fordul elő:
- Fordítsa össze az időpolimorfizmust
- Futási idő polimorfizmus
magyarázzuk el.
6. Az időpolimorfizmus fordítása:
Ez idő alatt a beírt program végrehajtható programmá változik. A kód telepítése előtt a rendszer észleli a hibákat. Ennek elsősorban két kategóriája van.
- Funkció túlterhelés
- Kezelő túlterhelése
Nézzük meg, hogyan használjuk ezt a két kategóriát.
7. Funkció túlterhelés:
Ez azt jelenti, hogy egy funkció különböző feladatokat hajthat végre. A függvényeket túlterheltnek nevezzük, ha több hasonló nevű, de eltérő argumentumú függvény létezik.
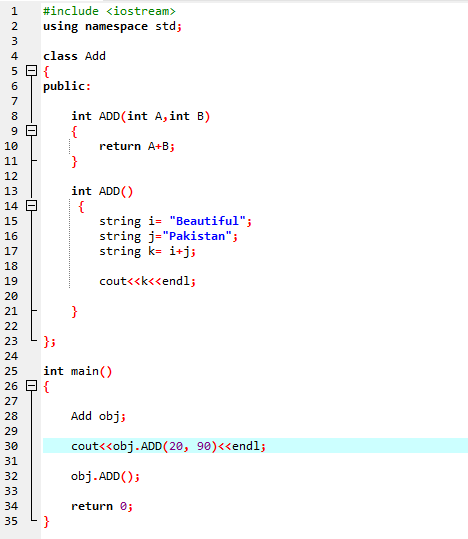
Először az
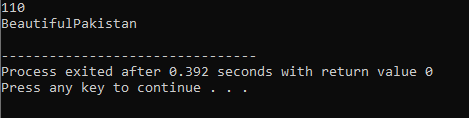
Kezelői túlterhelés:
Az operátor több funkciójának meghatározásának folyamatát operátor túlterhelésnek nevezzük.
A fenti példa tartalmazza az
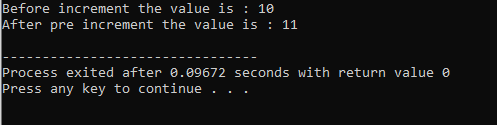
8. Futási idő polimorfizmusa:
Ez az az időtartam, ameddig a kód fut. A kód alkalmazása után a hibák észlelhetők.
Funkció felülbírálása:
Ez akkor fordul elő, ha egy származtatott osztály hasonló függvénydefiníciót használ, mint az egyik alaposztálytagfüggvény.
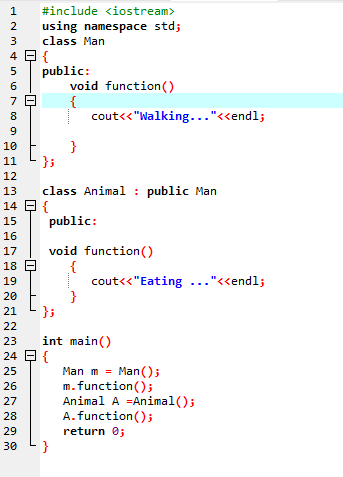
Az első sorban beépítjük az
C++ karakterláncok:
Most megtudjuk, hogyan deklarálhatjuk és inicializálhatjuk a karakterláncot C++ nyelven. A String karaktercsoport tárolására szolgál a programban. A programban tárolja az alfabetikus értékeket, számjegyeket és speciális típusú szimbólumokat. A karaktereket tömbként foglalta le a C++ programban. A tömbök a karakterek gyűjteményének vagy kombinációjának lefoglalására szolgálnak a C++ programozásban. A tömb lezárására egy speciális, null karakterként ismert szimbólumot használnak. Ezt az escape szekvencia (\0) jelöli, és a karakterlánc végének megadására szolgál.
Szerezze meg a karakterláncot a „cin” paranccsal:
Egy karakterlánc-változó bevitelére szolgál üres szóköz nélkül. Az adott esetben egy C++ programot valósítunk meg, amely a „cin” paranccsal kapja meg a felhasználó nevét.
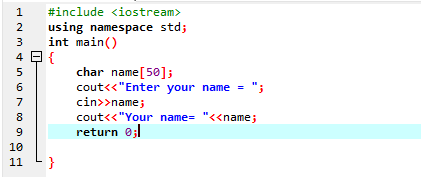
Első lépésben az
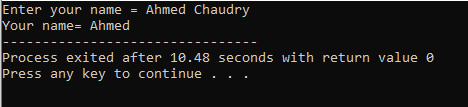
A felhasználó beírja az „Ahmed Chaudry” nevet. De csak „Ahmed”-et kapunk kimenetként, nem pedig a teljes „Ahmed Chaudry”-t, mivel a „cin” parancs nem tud üres karakterláncot tárolni. Csak a szóköz előtti értéket tárolja.
Szerezze le a karakterláncot a cin.get() függvény használatával:
Az kap() A cin parancs funkciója arra szolgál, hogy lekérje a billentyűzetről azt a karakterláncot, amely szóközöket tartalmazhat.
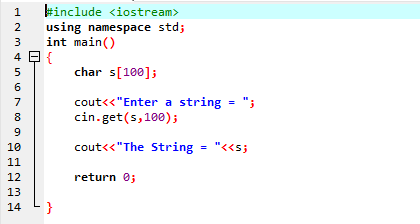
A fenti példa tartalmazza az
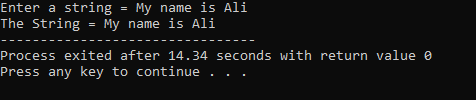
A felhasználó beír egy „A nevem Ali” karakterláncot. A teljes „My name is Ali” karakterláncot kapjuk eredményül, mivel a cin.get() függvény elfogadja az üres szóközöket tartalmazó karakterláncokat.
2D (kétdimenziós) karakterlánc-tömb használata:
Ebben az esetben a bemenetet (három város nevét) vesszük a felhasználótól egy 2D-s karakterláncok felhasználásával.
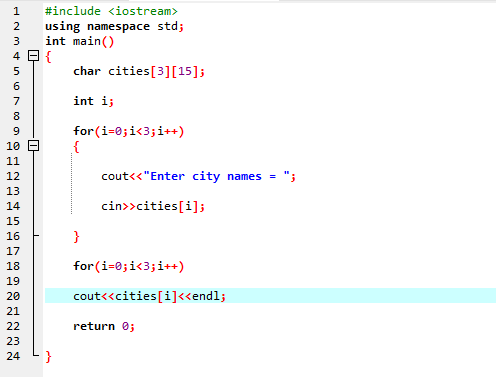
Először integráljuk az
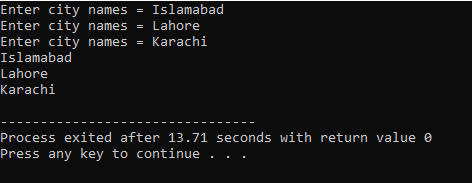
Itt a felhasználó három különböző város nevét írja be. A program egy sorindexet használ, hogy három karakterlánc-értéket kapjon. Minden érték a saját sorában marad meg. Az első karakterlánc az első sorban tárolódik és így tovább. Minden karakterláncérték ugyanúgy jelenik meg a sorindex használatával.
C++ szabványos könyvtár:
A C++ könyvtár sok függvényből, osztályból, konstansból és az összes kapcsolódó elemből álló fürt vagy csoportosítás szinte egy megfelelő halmazba zárva, mindig meghatározva és deklarálva a szabványosított fejlécfájlokat. Ezek megvalósítása két új fejlécfájlt tartalmaz, amelyeket a C++ szabvány nem igényel, ezek a
A Standard Library megszünteti az utasítások újraírásával járó nyüzsgést programozás közben. Ebben sok könyvtár van, amelyek számos funkció kódját tárolják. Ahhoz, hogy ezeket a könyvtárakat hasznosítsuk, kötelező fejlécfájlok segítségével linkelni. Amikor importáljuk a bemeneti vagy kimeneti könyvtárat, ez azt jelenti, hogy importáljuk az abban a könyvtárban tárolt összes kódot, és így tudjuk használni a benne foglalt funkciókat is, ha elrejti az összes mögöttes kódot, amelyet esetleg nem kell. lát.
A C++ standard könyvtár a következő két típust támogatja:
- Egy hosztolt megvalósítás, amely biztosítja a C++ ISO szabvány által leírt összes alapvető szabványos könyvtári fejlécfájlt.
- Önálló megvalósítás, amely csak a fejlécfájlok egy részét igényli a szabványos könyvtárból. A megfelelő részhalmaz a következő:
| Atomic_signed_lock_free és atomic-unsigned_lock_free) |
|
|
| |
|
|
| |
|
|
| |
|
|
| <összehasonlítás> | |
|
| |
|
|
| |
|
|
| <új> |
| |
| |
|
|
A fejlécfájlok közül néhányat sajnálatosnak találtak az elmúlt 11 C++ megjelenése óta: ezek a
A hosztolt és a szabadon álló megvalósítások közötti különbségek az alábbiak szerint láthatók:
- A hosztolt megvalósításban egy globális függvényt kell használnunk, amely a fő funkció. A szabadon álló megvalósítás során a felhasználó önállóan deklarálhat és meghatározhat kezdő és befejező függvényeket.
- Egy tárhely-megvalósításnak egy szála kötelező az egyeztetési időpontban. Míg a szabadonálló megvalósításban a megvalósítók maguk döntik el, hogy szükségük van-e a párhuzamos szál támogatására a könyvtárukban.
Típusok:
Mind a szabadon álló, mind a hosztolt C++ támogatja. A fejlécfájlok a következő két részre oszlanak:
- Iostream alkatrészek
- C++ STL részek (Standard Library)
Amikor C++-ban írunk egy programot végrehajtásra, mindig azokat a függvényeket hívjuk meg, amelyek már az STL-ben implementáltak. Ezek az ismert funkciók hatékonyan veszik fel a bemenetet és a kijelző kimenetet azonosított operátorok segítségével.
Az előzményeket figyelembe véve az STL-t eredetileg Standard Template Library-nek hívták. Ezután az STL könyvtár részeit szabványosították a C++ szabványos könyvtárában, amely ma használatos. Ezek közé tartozik az ISO C++ futásidejű könyvtár és néhány töredék a Boost könyvtárból, beleértve néhány más fontos funkciót is. Esetenként az STL a konténereket vagy gyakrabban a C++ Standard Library algoritmusait jelöli. Most ez az STL vagy Standard Template Library teljes egészében az ismert C++ Standard Library-ről beszél.
Az std névtér és fejlécfájlok:
A függvények vagy változók összes deklarációja a szabványos könyvtárban történik, fejlécfájlok segítségével, amelyek egyenletesen vannak elosztva közöttük. A deklaráció nem történik meg, hacsak nem tartalmazza a fejlécfájlokat.
Tegyük fel, hogy valaki listákat és karakterláncokat használ, hozzá kell adnia a következő fejlécfájlokat:
#include#include
Ezek a szögletes zárójelek „<>” azt jelentik, hogy meg kell keresni az adott fejlécfájlt a definiálandó és benne foglalt könyvtárban. Ehhez a könyvtárhoz egy „.h” kiterjesztés is hozzáadható, amely szükség vagy kívánság esetén megtörténik. Ha kizárjuk a „.h” könyvtárat, szükségünk van egy „c” kiegészítésre közvetlenül a fájl nevének kezdete előtt, csak annak jelzésére, hogy ez a fejlécfájl egy C könyvtárhoz tartozik. Például írhat (#include
Ha a névtérről beszélünk, a teljes C++ szabványos könyvtár ebben a névtérben található, amelyet std-ként jelölünk. Ez az oka annak, hogy a szabványosított könyvtárneveket a felhasználóknak hozzáértően kell meghatározniuk. Például:
Std :: cout << „Ez el fog múlni !/ n” ;C++ vektorok:
Számos módja van az adatok vagy értékek tárolásának C++ nyelven. De egyelőre azt keressük, hogy a programok C++ nyelven történő írása közben a legegyszerűbb és legrugalmasabb módon tároljuk az értékeket. Tehát a vektorok olyan konténerek, amelyek megfelelően sorba vannak rendezve egy sorozatmintában, amelynek mérete a végrehajtás időpontjában az elemek beillesztésétől és levonásától függően változik. Ez azt jelenti, hogy a programozó a program végrehajtása során tetszés szerint módosíthatja a vektor méretét. Olyan módon hasonlítanak a tömbökhöz, hogy kommunikálható tárolási pozíciókkal is rendelkeznek a benne foglalt elemek számára. A vektorokban található értékek vagy elemek számának ellenőrzéséhez egy ' std::count' funkció. A vektorok a C++ szabványos sablonkönyvtárában találhatók, így van egy határozott fejlécfájlja, amelyet először be kell venni:
#includeNyilatkozat:
Egy vektor deklarációja az alábbiakban látható.
Std :: vektor < DT > NameOfVector ;Itt a vektor a használt kulcsszó, a DT a vektor adattípusát mutatja, amely helyettesíthető int, float, char vagy bármilyen más kapcsolódó adattípussal. A fenti nyilatkozat a következőképpen írható át:
Vektor < úszó > Százalék ;A vektor mérete nincs megadva, mert a méret a végrehajtás során növekedhet vagy csökkenhet.
Vektorok inicializálása:
A vektorok inicializálásának több módja van a C++-ban.
1. technika:
Vektor < int > v1 = { 71 , 98 , 3. 4 , 65 } ;Vektor < int > v2 = { 71 , 98 , 3. 4 , 65 } ;
Ebben az eljárásban közvetlenül hozzárendeljük az értékeket mindkét vektorhoz. A mindkettőhöz rendelt értékek teljesen hasonlóak.
2. technika:
Vektor < int > v3 ( 3 , tizenöt ) ;Ebben az inicializálási folyamatban a 3 a vektor méretét határozza meg, a 15 pedig a benne tárolt adatot vagy értéket. Létrejön egy „int” adattípusú vektor a megadott 3-as mérettel, amely a 15-ös értéket tárolja, ami azt jelenti, hogy a „v3” vektor a következőket tárolja:
Vektor < int > v3 = { tizenöt , tizenöt , tizenöt } ;Főbb műveletek:
A főbb műveletek, amelyeket a vektorosztályon belüli vektorokon fogunk megvalósítani:
- Érték hozzáadása
- Hozzáférés egy értékhez
- Érték megváltoztatása
- Érték törlése
Hozzáadás és törlés:
A vektoron belüli elemek hozzáadása és törlése szisztematikusan történik. A legtöbb esetben az elemek a vektortárolók befejezésekor kerülnek beillesztésre, de a kívánt helyre értékeket is hozzáadhat, amelyek végül a többi elemet az új helyükre helyezik. Míg a törlésnél, amikor az értékeket az utolsó pozícióból töröljük, az automatikusan csökkenti a tároló méretét. Ha azonban a tárolón belüli értékek véletlenszerűen törlődnek egy adott helyről, az új helyek automatikusan hozzárendelődnek a többi értékhez.
Használt funkciók:
A vektorban tárolt értékek megváltoztatásához vagy módosításához van néhány előre definiált függvény, amelyet módosítónak nevezünk. Ezek a következők:
- Insert(): Egy adott helyen lévő vektortárolón belüli érték hozzáadására szolgál.
- Erase(): Egy adott helyen lévő vektortárolóban lévő értékek eltávolítására vagy törlésére szolgál.
- Swap(): Az azonos adattípushoz tartozó vektortárolóban lévő értékek felcserélésére szolgál.
- Assign(): Új érték hozzárendelésére szolgál a vektortárolóban korábban tárolt értékhez.
- Begin(): Egy iterátor visszaadására szolgál egy cikluson belül, amely az első elemen belüli vektor első értékére vonatkozik.
- Clear(): A vektortárolóban tárolt összes érték törlésére szolgál.
- Push_back(): érték hozzáadására szolgál a vektortároló befejezésekor.
- Pop_back(): Egy érték törlésére szolgál a vektortároló befejezésekor.
Példa:
Ebben a példában módosítókat használunk a vektorok mentén.
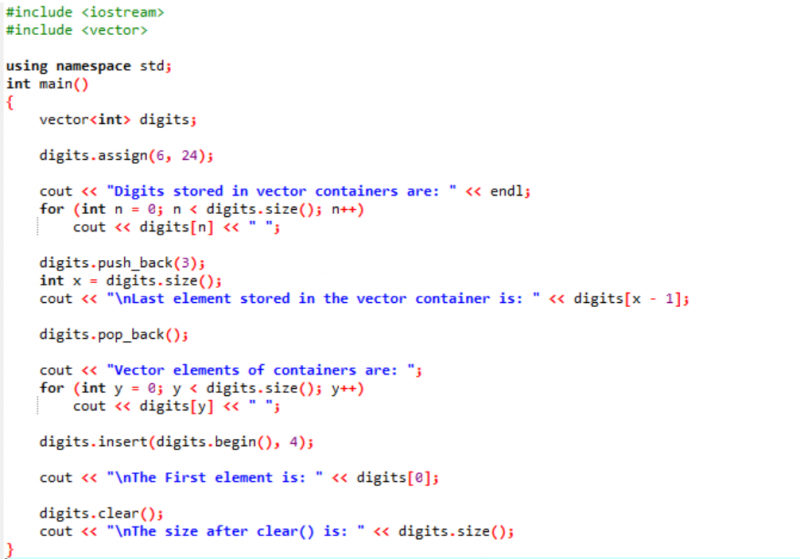
Először is belefoglaljuk az
A kimenet az alábbiakban látható.

C++ fájlok bemeneti kimenete:
A fájl egymással összefüggő adatok halmaza. A C++ nyelven a fájl bájtok sorozata, amelyeket időrendi sorrendben gyűjtenek össze. A fájlok többsége a lemezen belül található. De hardvereszközök, például mágnesszalagok, nyomtatók és kommunikációs vonalak is szerepelnek a fájlokban.
A fájlok be- és kimenetét három fő osztály jellemzi:
- Az „istream” osztályt a bevitel fogadására használják.
- Az „ostream” osztályt a kimenet megjelenítésére használják.
- A bemenethez és a kimenethez használja az „iostream” osztályt.
A fájlokat a C++ folyamként kezeli. Amikor egy fájlban vagy fájlból veszünk be és kimenetet, a következő osztályokat használjuk:
- Offstream: Ez egy adatfolyam osztály, amelyet fájlba írásra használnak.
- Ifstream: Ez egy adatfolyam osztály, amelyet egy fájl tartalmának olvasására használnak.
- Folyam: Ez egy adatfolyam osztály, amelyet fájlba vagy fájlból való olvasásra és írásra egyaránt használnak.
Az „istream” és az „ostream” osztályok az összes fent említett osztály ősei. A fájlfolyamok ugyanolyan könnyen használhatók, mint a „cin” és „cout” parancsok, azzal a különbséggel, hogy ezeket a fájlfolyamokat más fájlokhoz társítják. Nézzünk egy példát az „fstream” osztály rövid tanulmányozására:
Példa:
Ebben az esetben az adatokat fájlba írjuk.
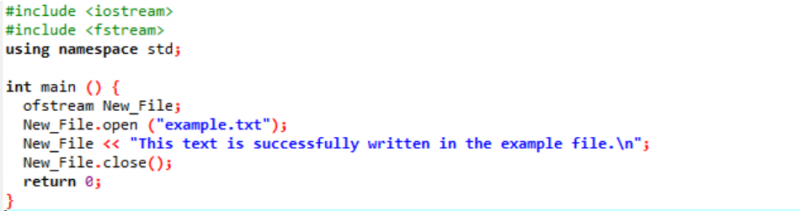
Az első lépésben integráljuk a bemeneti és kimeneti adatfolyamot. Ezután hozzáadódik az

A „példa” fájl megnyílik a személyi számítógépről, és a fájlra írt szöveg a fent látható módon ebbe a szövegfájlba kerül.
Fájl megnyitása:
Amikor egy fájlt megnyitunk, azt egy adatfolyam képviseli. A fájlhoz egy objektum jön létre, mint az előző példában a New_File. Az adatfolyamon végrehajtott összes bemeneti és kimeneti művelet automatikusan érvényesül magára a fájlra. Egy fájl megnyitásához az open() függvényt a következőképpen használjuk:
Nyisd ki ( NameOfFile , mód ) ;Itt a mód nem kötelező.
Fájl bezárása:
Miután az összes beviteli és kimeneti művelet befejeződött, be kell zárnunk a szerkesztésre megnyitott fájlt. Alkalmaznunk kell a Bezárás() funkció ebben a helyzetben.
Új fájl. Bezárás ( ) ;Ha ez megtörténik, a fájl elérhetetlenné válik. Ha bármilyen körülmények között az objektum megsemmisül, még akkor is, ha a fájlhoz kapcsolódik, a destruktor spontán meghívja a close() függvényt.
Szöveges fájlok:
A szöveg tárolására szövegfájlokat használnak. Ezért, ha a szöveg be van írva, vagy megjelenik, akkor néhány formázási módosulnia kell. A szövegfájlon belüli írási művelet ugyanaz, mint a „cout” parancs végrehajtása.
Példa:
Ebben a forgatókönyvben az előző ábrán már elkészített szöveges fájlba írunk adatokat.
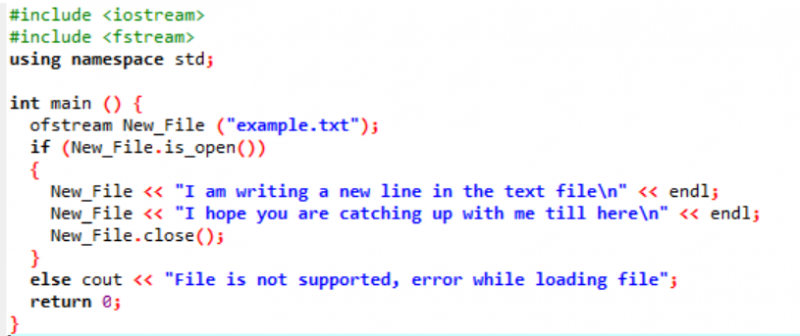
Itt adatokat írunk az „example” nevű fájlba a New_File() függvény segítségével. Megnyitjuk az „example” fájlt a nyisd ki() módszer. Az „ofstream” az adatok fájlhoz való hozzáadására szolgál. A fájlon belüli összes munka elvégzése után a kívánt fájlt bezárja a Bezárás() funkció. Ha a fájl nem nyílik meg, a „Fájl nem támogatott, hiba a fájl betöltésekor” hibaüzenet jelenik meg.

A fájl megnyílik, és a szöveg megjelenik a konzolon.
Szövegfájl olvasása:
Egy fájl olvasását a következő példa segítségével mutatjuk be.
Példa:
Az „ifstream” a fájlban tárolt adatok olvasására szolgál.
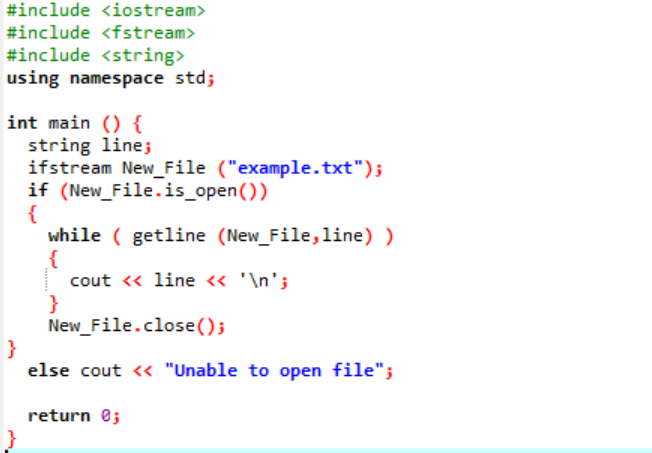
A példa az elején tartalmazza a fő fejlécfájlokat:
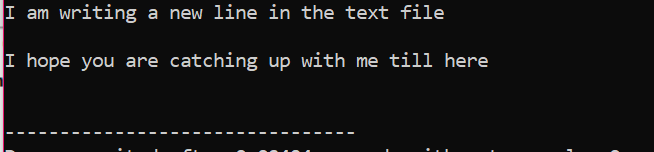
A szövegfájlban tárolt összes információ a képen látható módon megjelenik a képernyőn.
Következtetés
A fenti útmutatóban részletesen megismertük a C++ nyelvet. A példákkal együtt minden témát bemutatunk és elmagyarázunk, és minden akciót kidolgozunk.