Gyűjtemény létrehozása
Az indexek használata előtt létre kell hoznunk egy új gyűjteményt a MongoDB-nkban. Már létrehoztunk egyet, és beszúrtunk 10 „Dummy” nevű dokumentumot. A find() MongoDB függvény megjeleníti a „Dummy” gyűjtemény összes rekordját az alábbi MongoDB shell képernyőn.
teszt> db.Dummy.find() 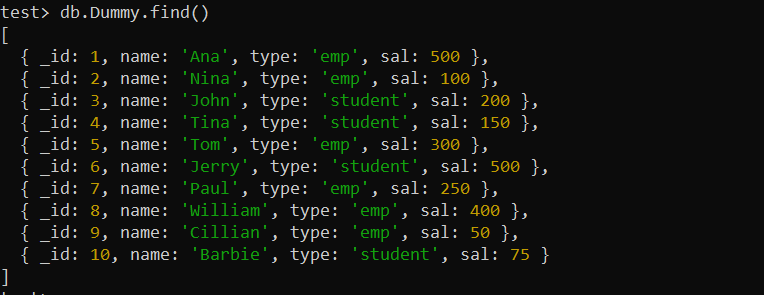
Válassza az Indexelés típusát
Index létrehozása előtt először meg kell határoznia a lekérdezési feltételekben általánosan használt oszlopokat. Az indexek jól teljesítenek azokon az oszlopokon, amelyeket gyakran szűrnek, rendeznek vagy keresnek. A nagy számosságú (sok különböző értékű) mezők gyakran kiváló indexelési lehetőségek. Íme néhány kódpélda a különböző indextípusokhoz.
01. példa: Egymezős index
Valószínűleg ez az index legalapvetőbb típusa, amely egyetlen oszlopot indexel az oszlop lekérdezési sebességének növelése érdekében. Ez az indextípus olyan lekérdezésekhez használatos, amelyekben egyetlen kulcsmezőt használ a gyűjteményrekordok lekérdezéséhez. Tételezzük fel, hogy a „típus” mezőt használja a „Dummy” gyűjtemény rekordjainak lekérdezésére a keresési függvényen belül, az alábbiak szerint. Ez a parancs végignézi a teljes gyűjteményt, aminek feldolgozása hosszú ideig tarthat, amíg a hatalmas gyűjtemények feldolgozódnak. Ezért optimalizálnunk kell ennek a lekérdezésnek a teljesítményét.
teszt> db.Dummy.find({típus: 'emp' })
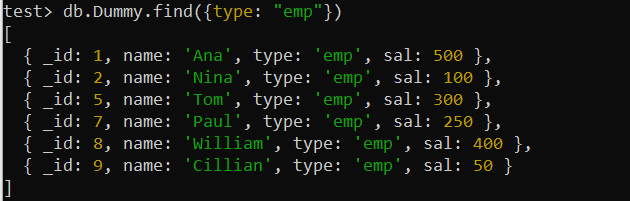
A Dummy gyűjtemény fenti rekordjait a „type” mező használatával találtuk meg, azaz feltételt tartalmaznak. Ezért az egykulcsos index itt használható a keresési lekérdezés optimalizálására. Tehát a MongoDB createIndex() függvényét fogjuk használni, hogy indexet hozzunk létre a „Dummy” gyűjtemény „type” mezőjében. A lekérdezés használatának illusztrációja egy „type_1” nevű, egykulcsos index sikeres létrehozását mutatja be a héjon.
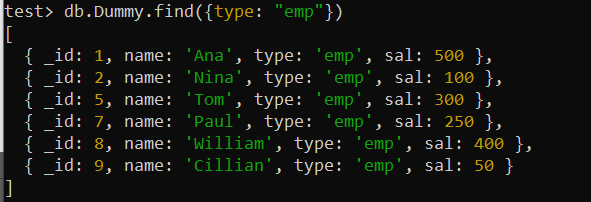
teszt> db.Dummy.createIndex({ típus: 1 })Használjuk a find() lekérdezést, amint az a „type” mező használatával nyer. A művelet lényegesen gyorsabb lesz, mint a korábban használt find() függvény, mivel az index a helyén van, mivel a MongoDB felhasználhatja az indexet a kért munkacímmel rendelkező rekordok gyors lekérésére.
teszt> db.Dummy.find({típus: 'emp' })
02. példa: Összetett index
Előfordulhat, hogy bizonyos körülmények között különféle kritériumok alapján kívánunk tárgyakat keresni. Összetett index megvalósítása ezekben a mezőkben segíthet a lekérdezés teljesítményének javításában. Tegyük fel, hogy ezúttal a „Dummy” gyűjteményből szeretne keresni, több különböző keresési feltételeket tartalmazó mező használatával, ahogy a lekérdezés megjelenik. Ez a lekérdezés olyan rekordokat keresett a gyűjteményből, ahol a „type” mező értéke „emp”, a „sal” mező pedig nagyobb, mint 350.
A $gte logikai operátort használták a feltétel alkalmazására a „sal” mezőre. A 10 lemezből álló teljes gyűjtemény átkutatásával összesen két lemez került vissza.
teszt> db.Dummy.find({típus: 'emp' , sal: {$gte: 350 } }) 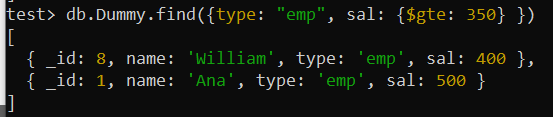
Hozzon létre egy összetett indexet a fent említett lekérdezéshez. Ez az összetett index „típus” és „sal” mezőkkel rendelkezik. Az „1” és „-1” számok növekvő, illetve csökkenő sorrendet jelölnek a „type” és „sal” mezőben. Az összetett index oszlopainak sorrendje fontos, és meg kell felelnie a lekérdezési mintáknak. A MongoDB a „type_1_sal_-1” nevet adta ennek az összetett indexnek, ahogyan megjelenik.
teszt> db.Dummy.createIndex({ típus: 1 , lesz:- 1 }) 
Miután ugyanazt a find() lekérdezést használtuk olyan rekordok keresésére, amelyeknél a „type” mező értéke „emp”, és a „sal” mező értéke nagyobb, mint 350, ugyanazt a kimenetet kaptuk a sorrend kis változtatásával. az előző lekérdezés eredményéhez képest. A „sal” mező nagyobb értékrekordja most az első helyen áll, míg a legkisebb a legalacsonyabb a fenti összetett index „sal” mezőjéhez beállított „-1” szerint.
teszt> db.Dummy.find({típus: 'emp' , sal: {$gte: 350 } }) 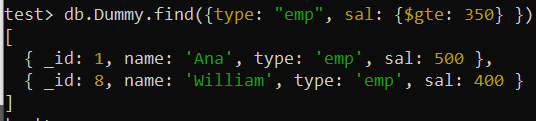
03. példa: Szöveg index
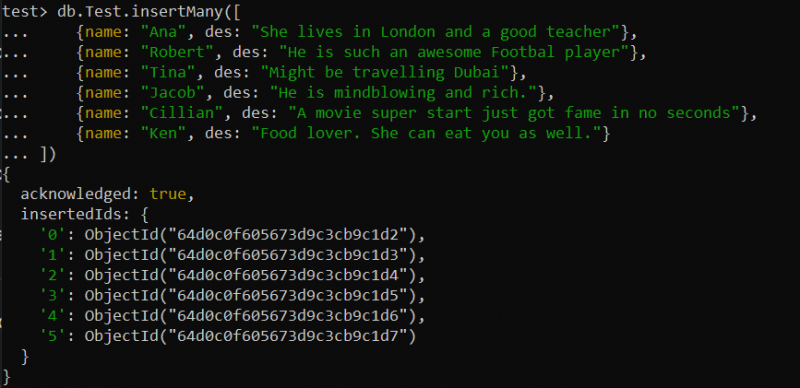
Néha olyan helyzetbe kerülhet, amikor nagy adatkészlettel kell foglalkoznia, mint például a termékek, összetevők nagy leírása stb. A szöveges index hasznos lehet teljes szöveges kereséshez egy nagy szövegmezőben. Például létrehoztunk egy új „Test” nevű gyűjteményt tesztadatbázisunkban. Összesen 6 rekordot szúrt be ebbe a gyűjteménybe az insertMany() függvény használatával az alábbi find() lekérdezés szerint.
teszt> db.Test.insertMany([{név: 'Ana' , ebből: 'Londonban él, és jó tanár' },
{név: 'Robert' , ebből: 'Ő egy fantasztikus futballista' },
{név: 'tól től' , ebből: 'Talán Dubaiba utazom' },
{név: 'Jákób' , ebből: – Lenyűgöző és gazdag. },
{név: 'Cillian' , ebből: 'Egy szuperfilm pillanatok alatt hírnevet szerzett' },
{név: 'Ken' , ebből: – Ételkedvelő. Téged is meg tud enni. }
])
Most létrehozunk egy szöveges indexet a gyűjtemény „Des” mezőjében, a MongoDB createIndex() függvényének felhasználásával. A mező értékében szereplő „text” kulcsszó az index típusát jeleníti meg, amely „szöveg” index. A des_text indexnevet automatikusan generáltuk.
teszt> db.Test.createIndex({ des: 'szöveg' })Most a find() függvényt használták a „text-search” végrehajtására a gyűjteményben a „des_text” indexen keresztül. A $search operátort használták az „élelmiszer” szó keresésére a gyűjteményrekordokban, és megjelenítették az adott rekordot.
teszt> db.Test.find({ $text: { $search: 'étel' }}); 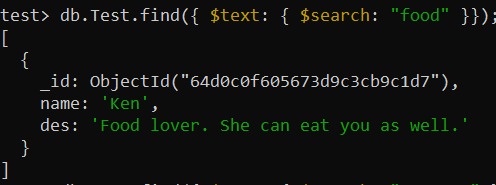
Indexek ellenőrzése:
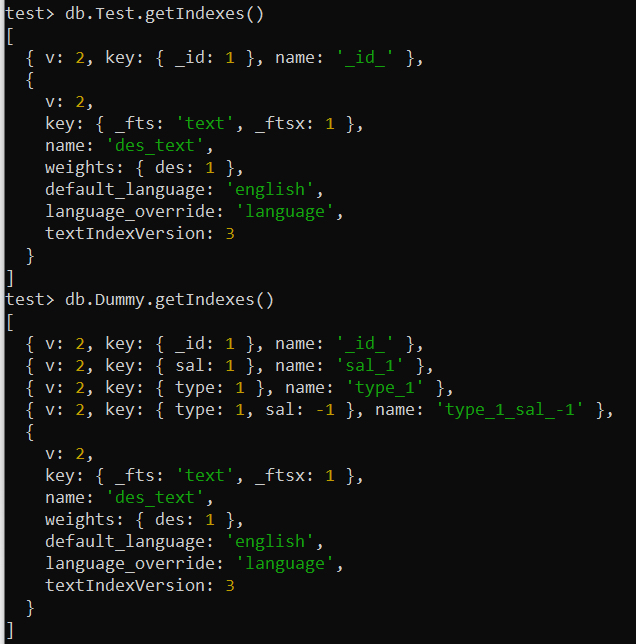
Ellenőrizheti és felsorolhatja a különböző gyűjtemények összes alkalmazott indexét a MongoDB-ben. Ehhez használja a getIndexes() metódust egy gyűjtemény nevével együtt a MongoDB shell képernyőjén. Ezt a parancsot külön használtuk a „Test” és a „Dummy” gyűjteményekhez. Ez a képernyőn megjeleníti a beépített és a felhasználó által meghatározott indexekkel kapcsolatos összes szükséges információt.
teszt> db.Test.getIndexes()teszt> db.Dummy.getIndexes()
Esési indexek:
Ideje törölni azokat az indexeket, amelyeket korábban a gyűjteményhez a dropIndex() függvény segítségével hoztak létre, és ugyanazt a mezőt, amelyre az indexet alkalmazták. Az alábbi lekérdezés azt mutatja, hogy az egyetlen indexet eltávolították.
teszt> db.Dummy.dropIndex({típus: 1 }) 
Ugyanígy az összetett index is eldobható.
teszt> db.Dummy.drop index({típus: 1 , lesz: 1 }) 
Következtetés
Az adatok MongoDB-ből való lekérésének felgyorsításával az indexelés elengedhetetlen a lekérdezések hatékonyságának növeléséhez. Indexek hiányában a MongoDB-nek a teljes gyűjteményben meg kell keresnie a megfelelő rekordokat, ami a készlet méretének növekedésével kevésbé hatékony. A MongoDB azon képessége, hogy gyorsan fel tudja fedezni a megfelelő rekordokat az index adatbázis-struktúra felhasználásával, felgyorsítja a lekérdezések feldolgozását megfelelő indexelés alkalmazása esetén.